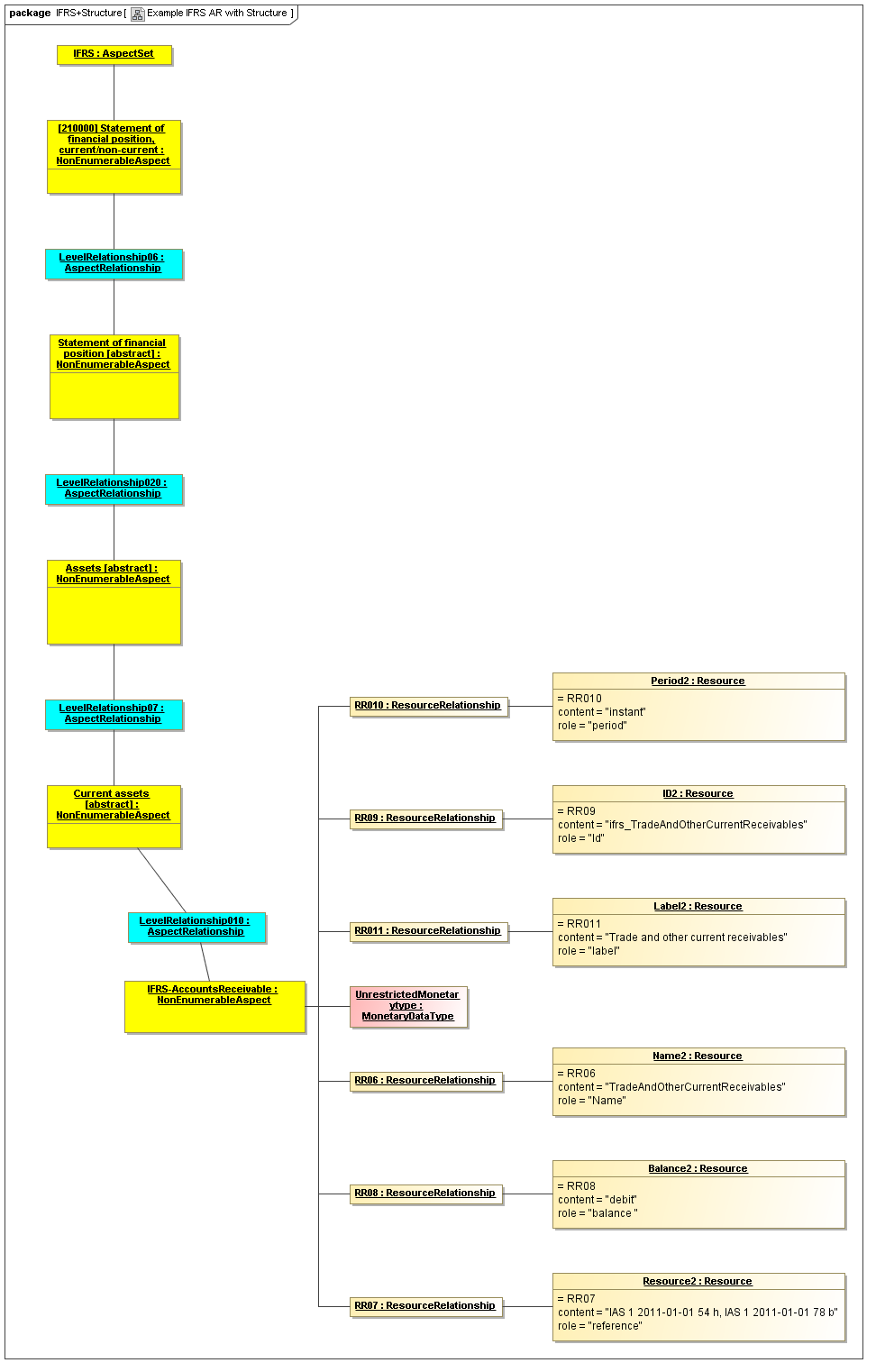
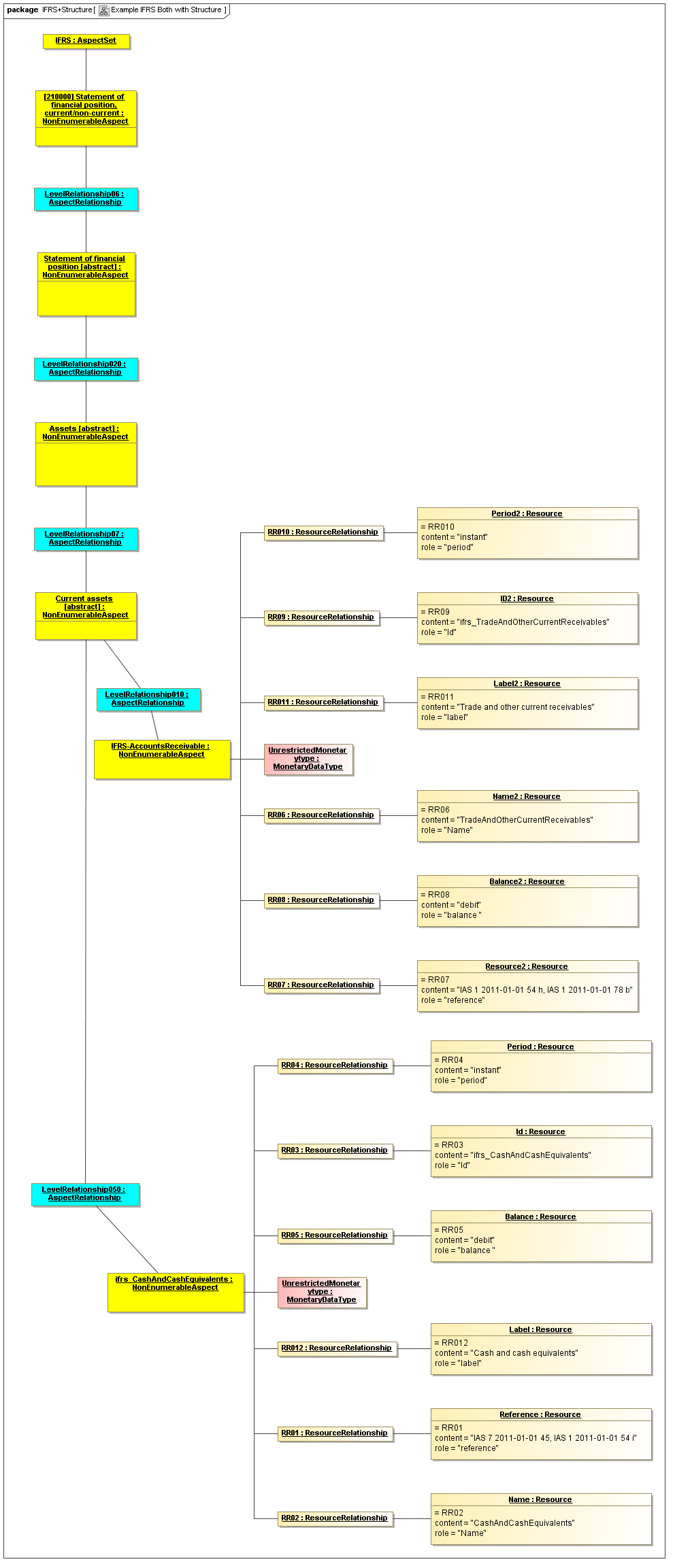
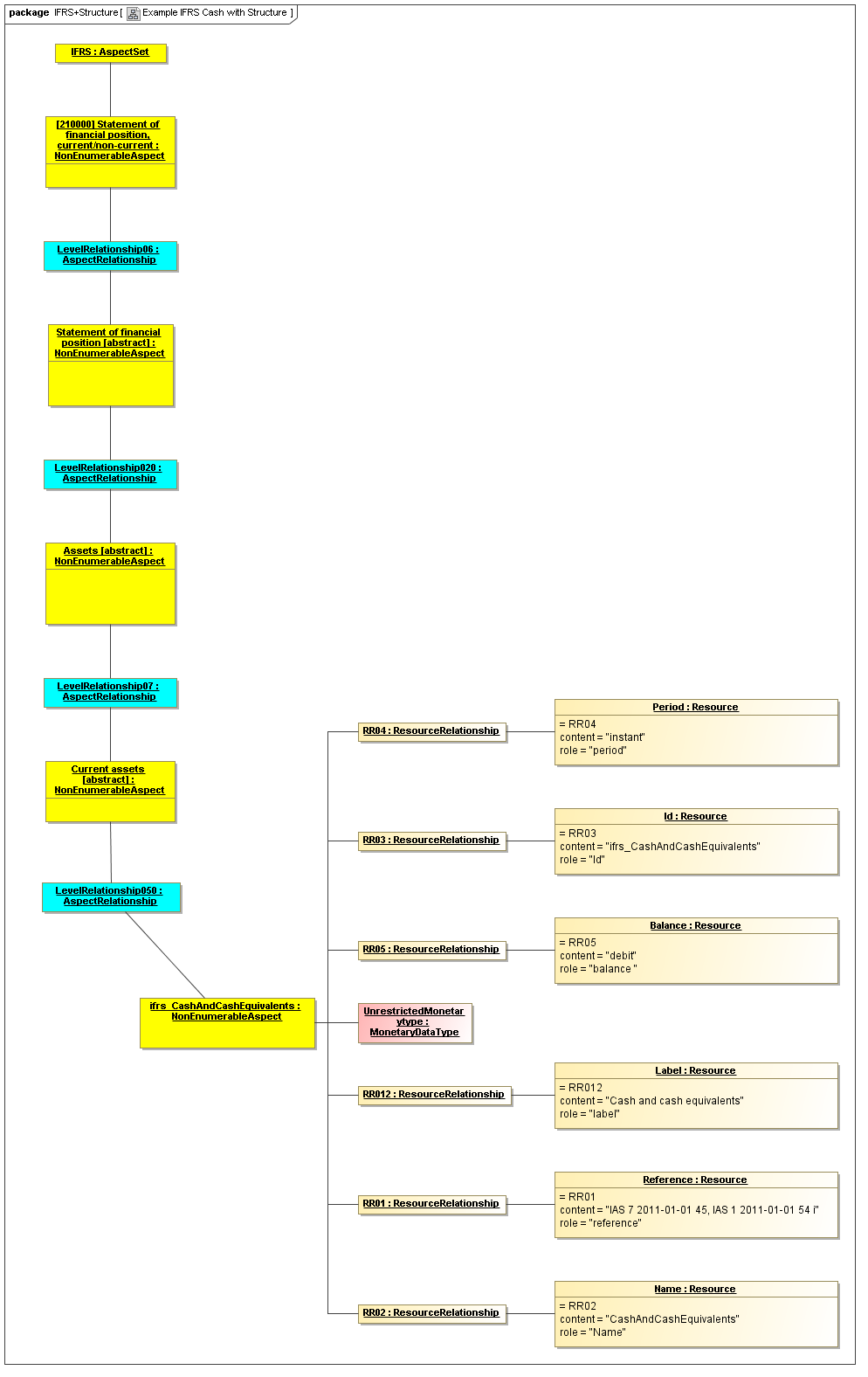
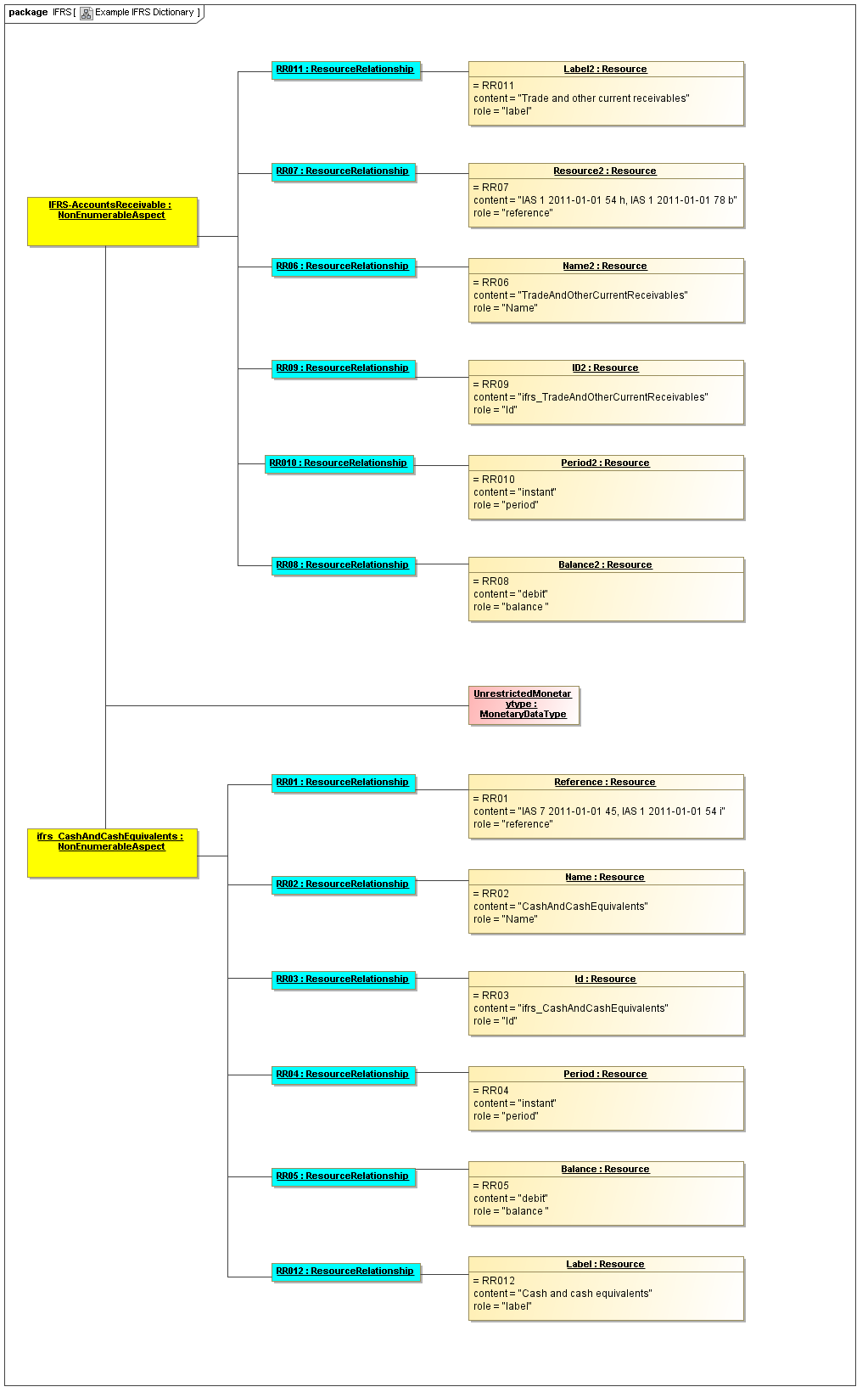
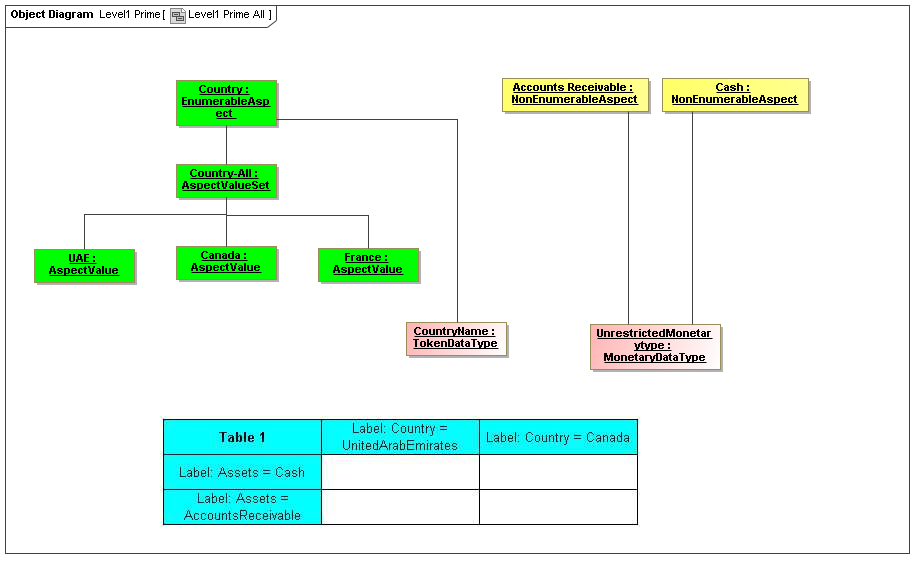
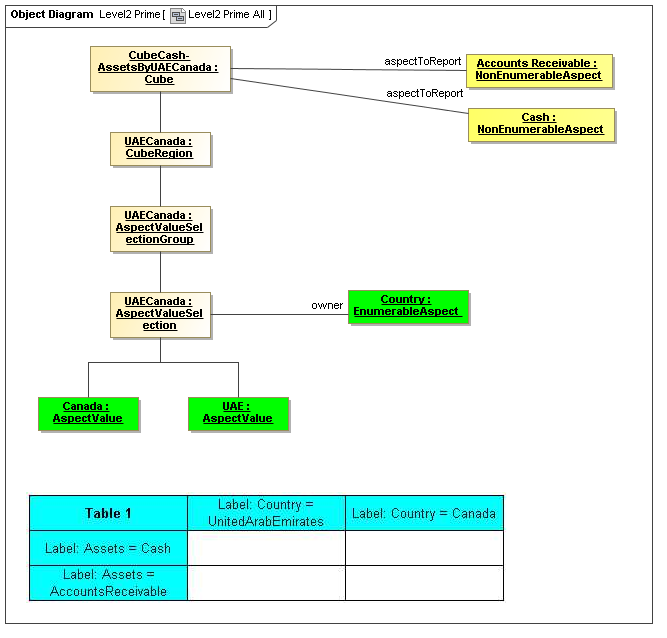
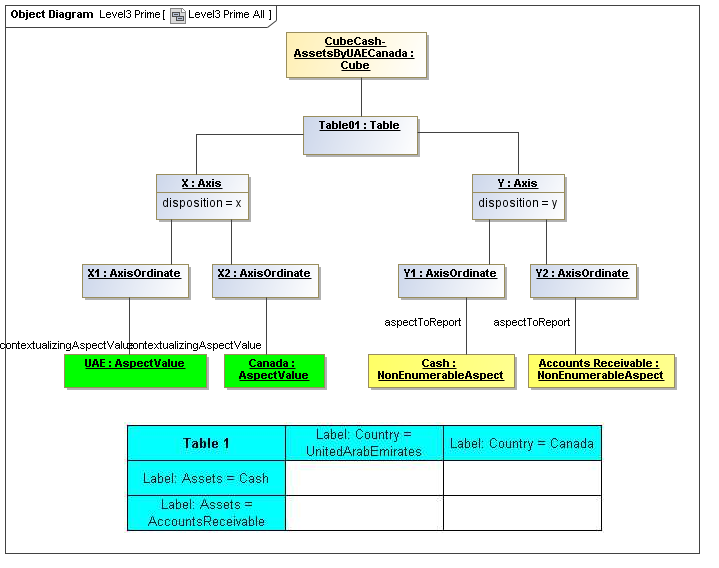
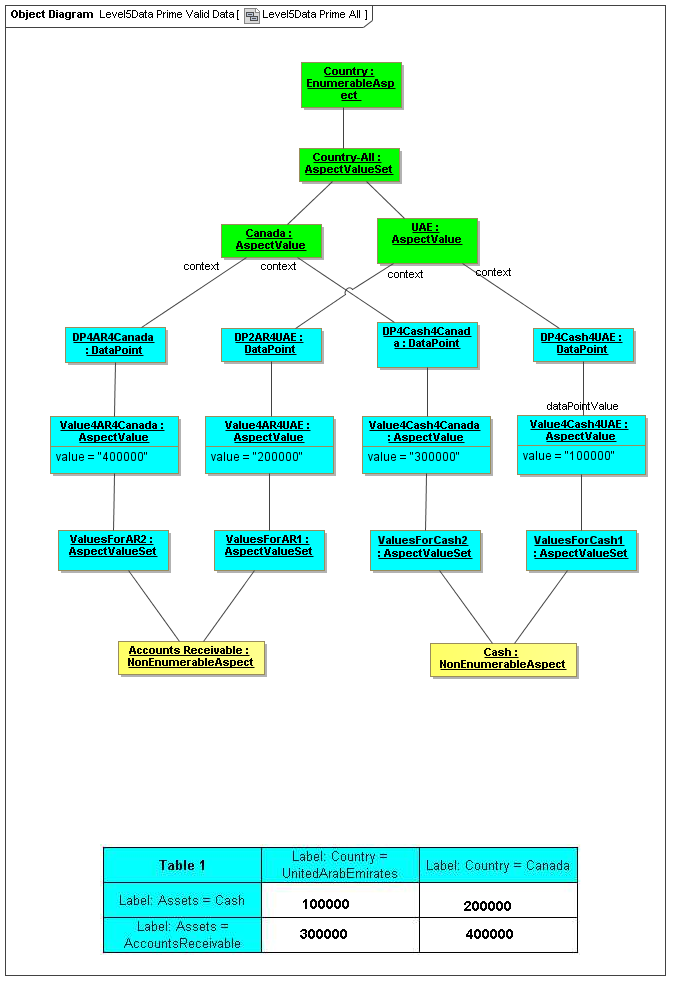
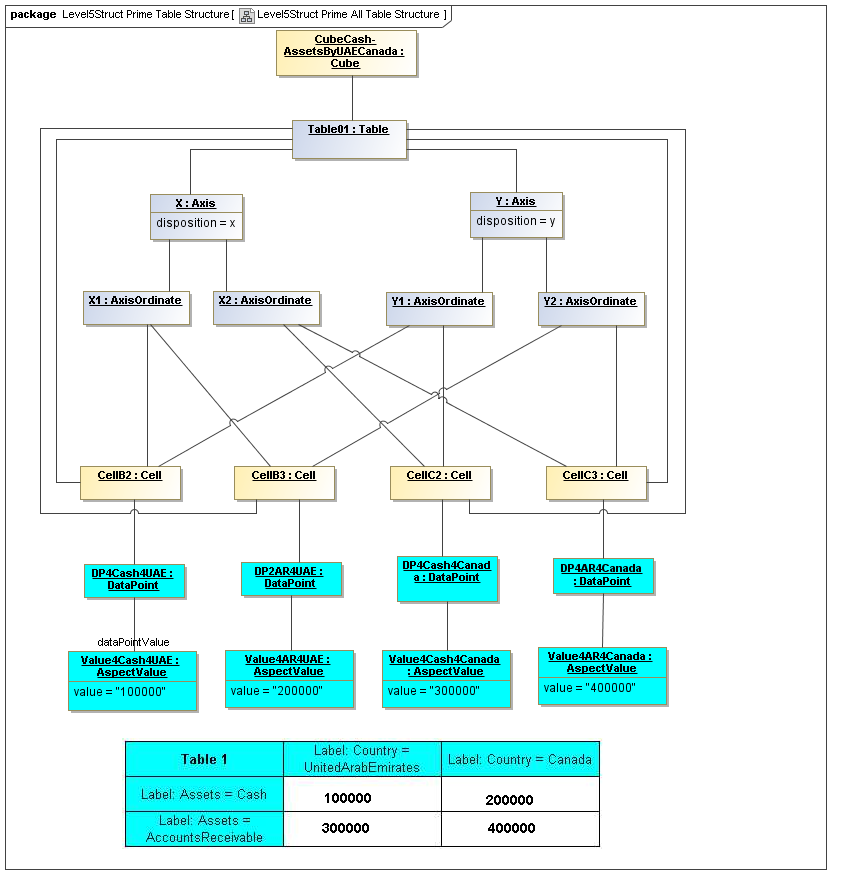
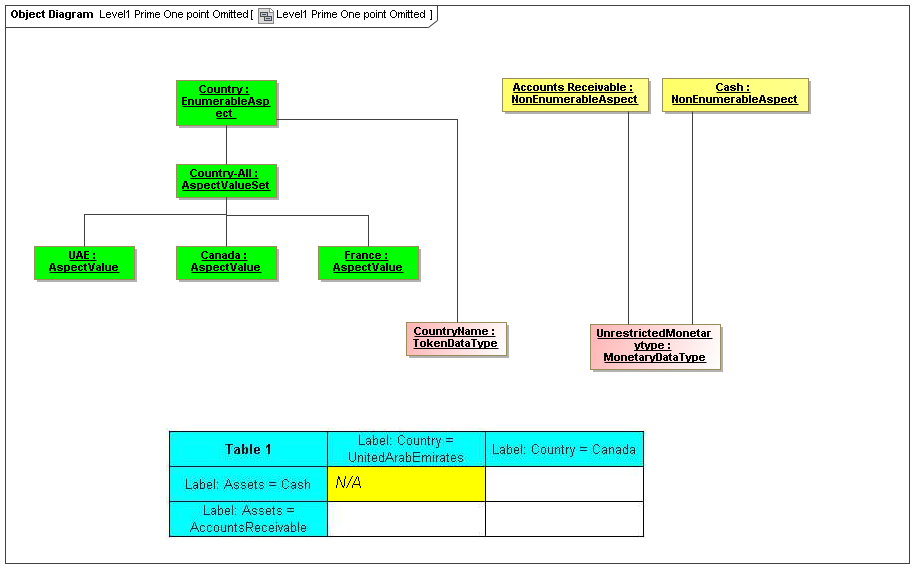
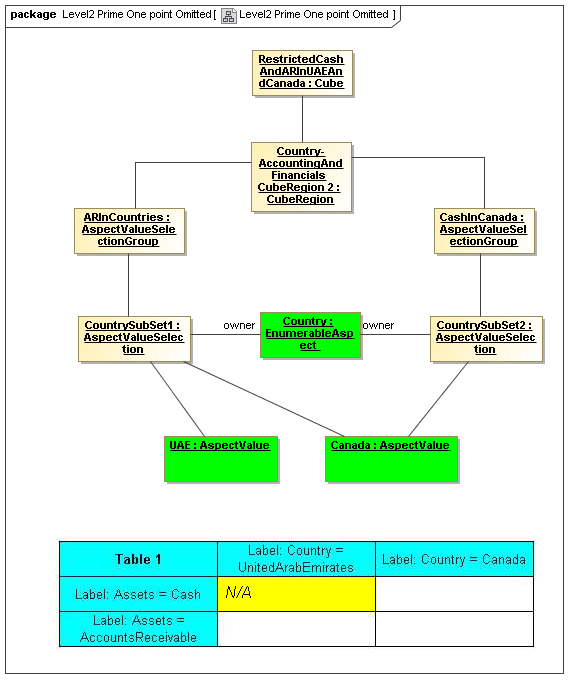
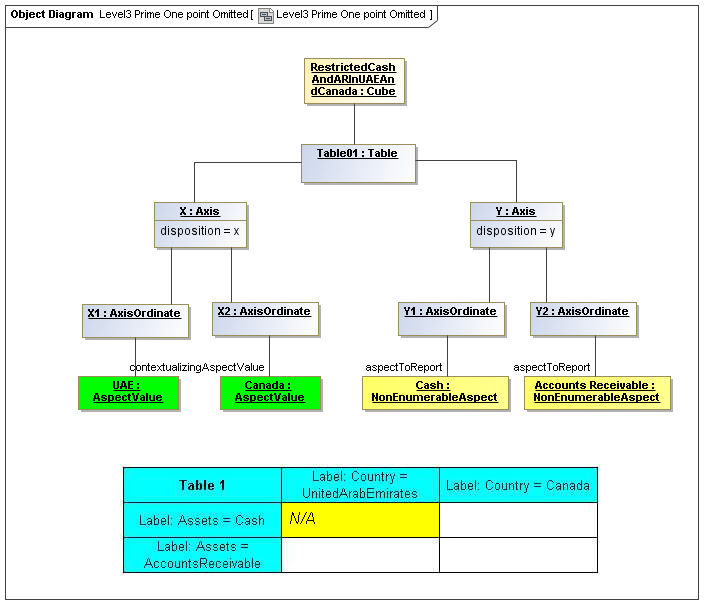
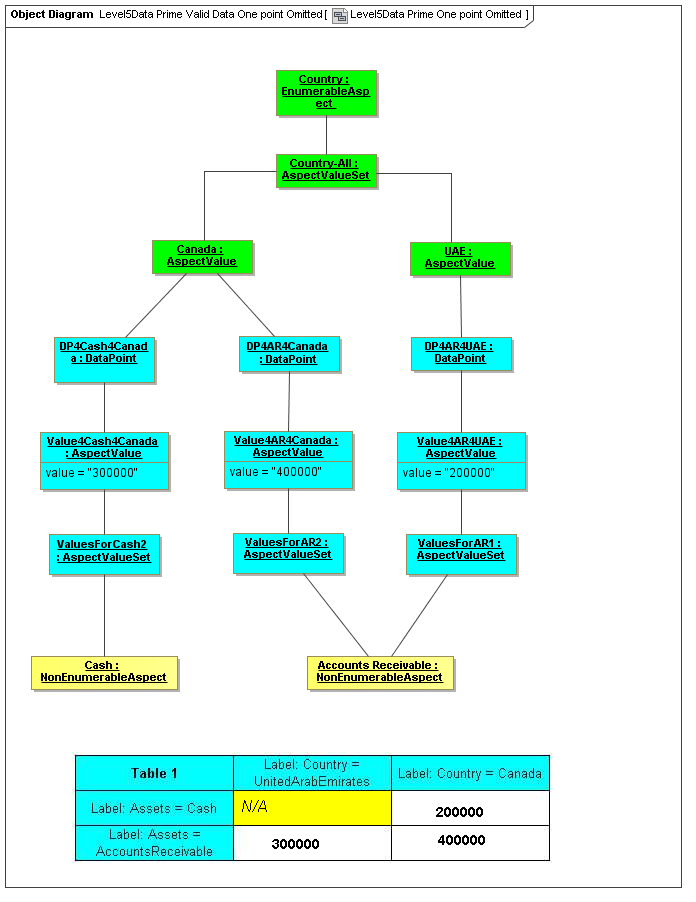
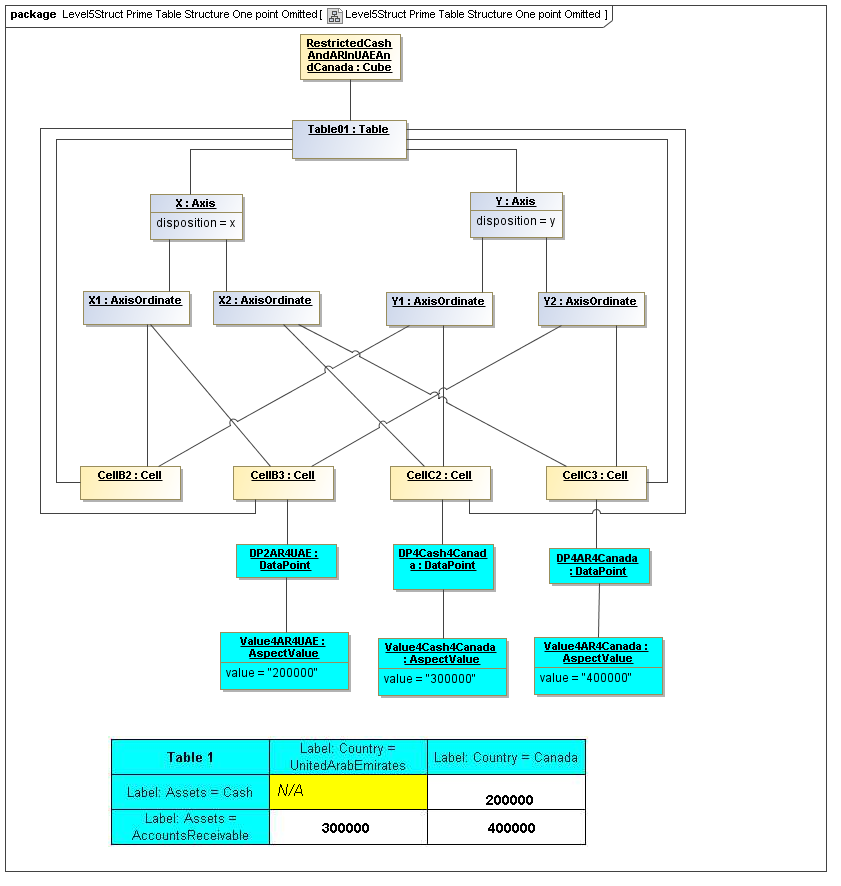
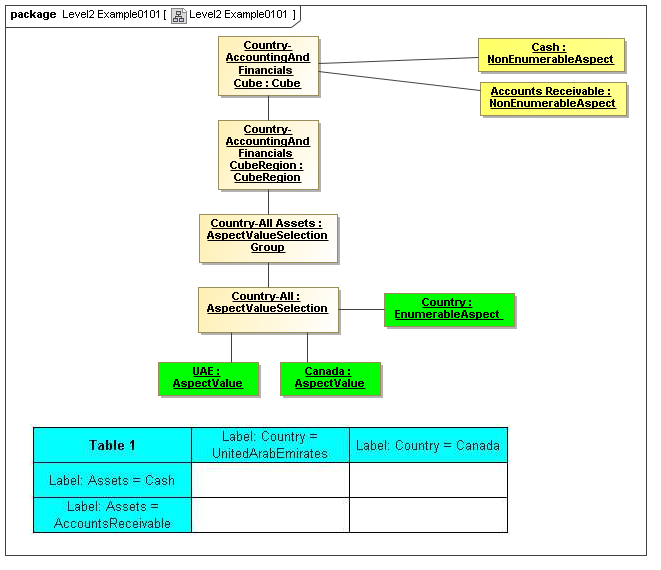
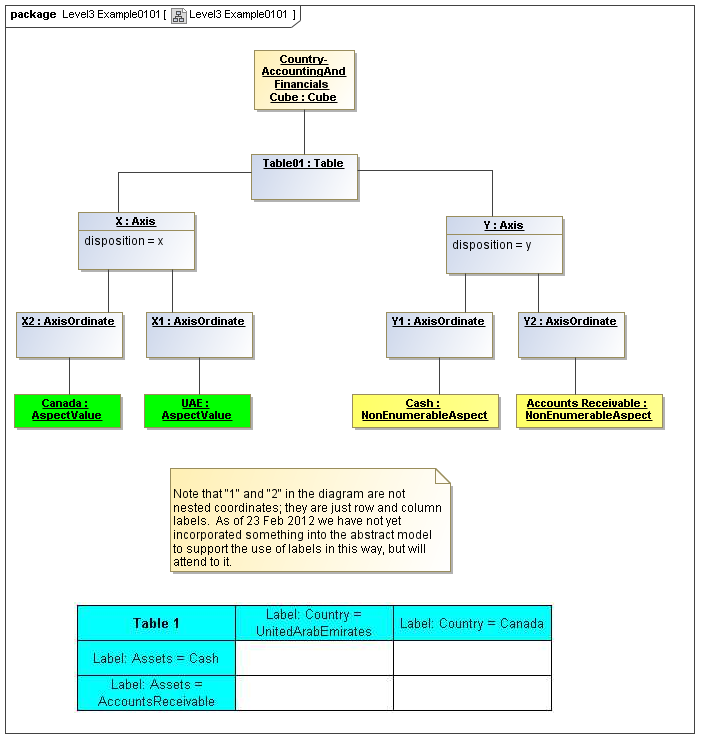
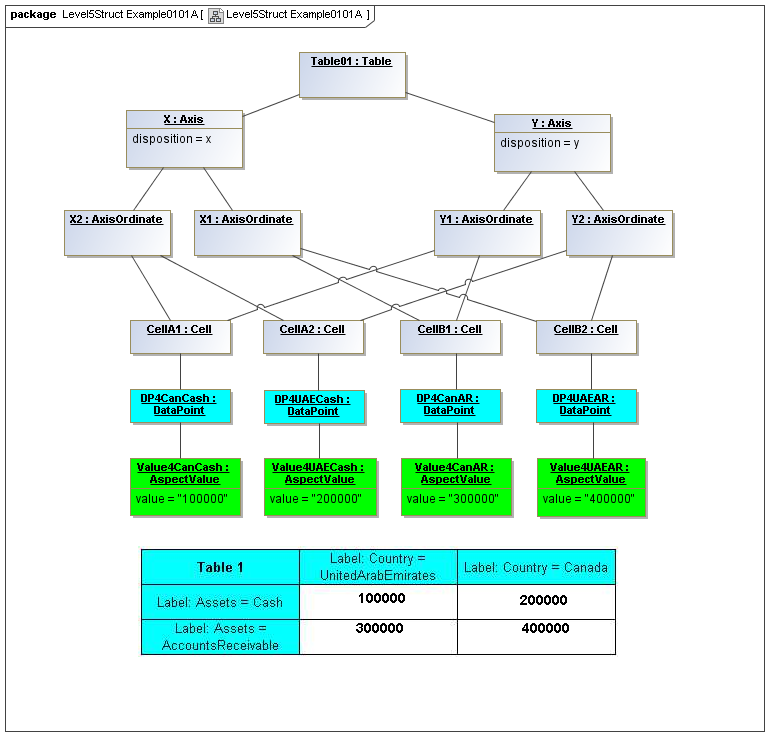
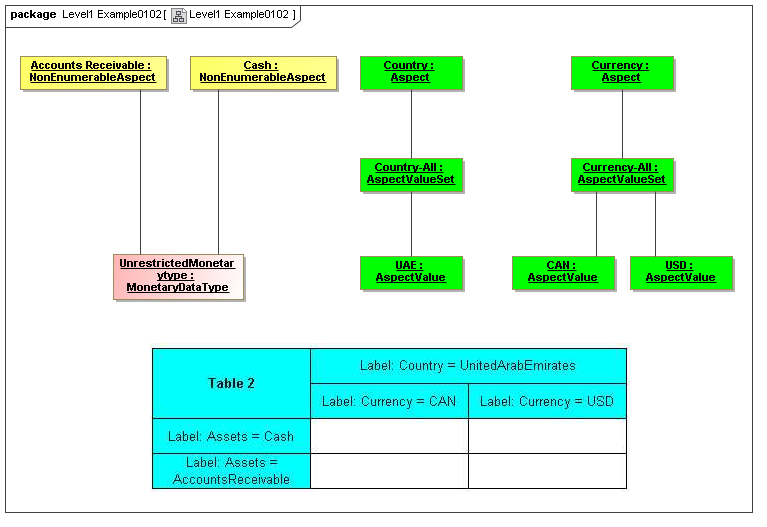
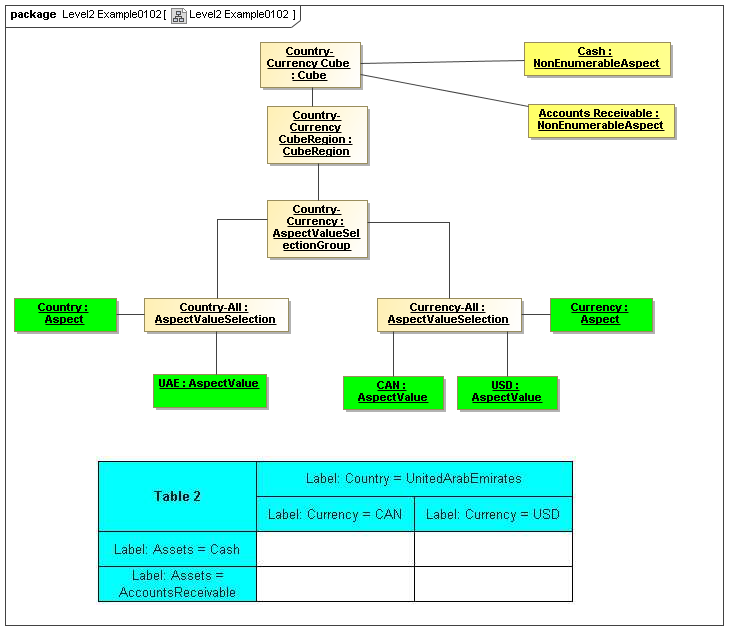
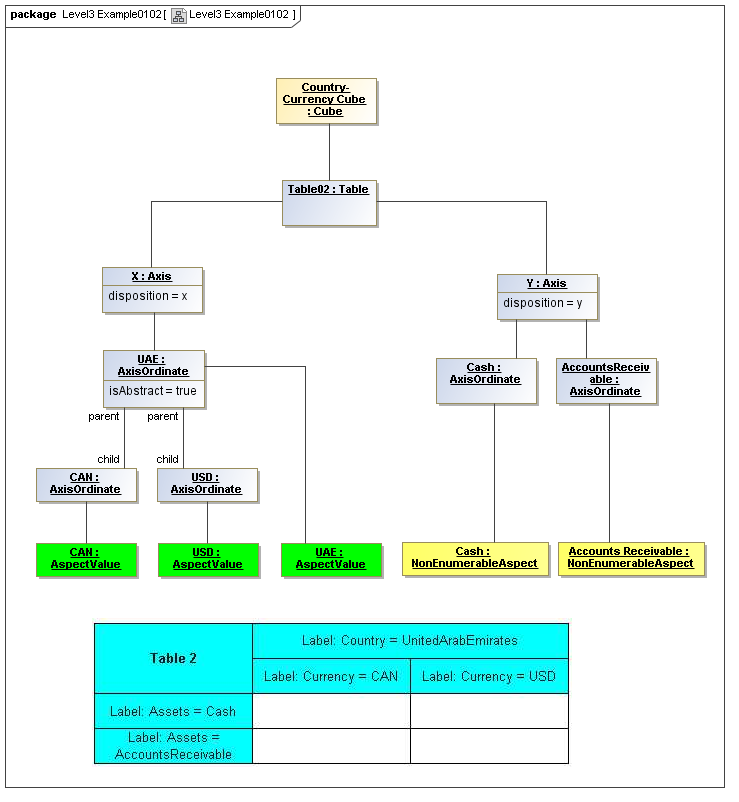
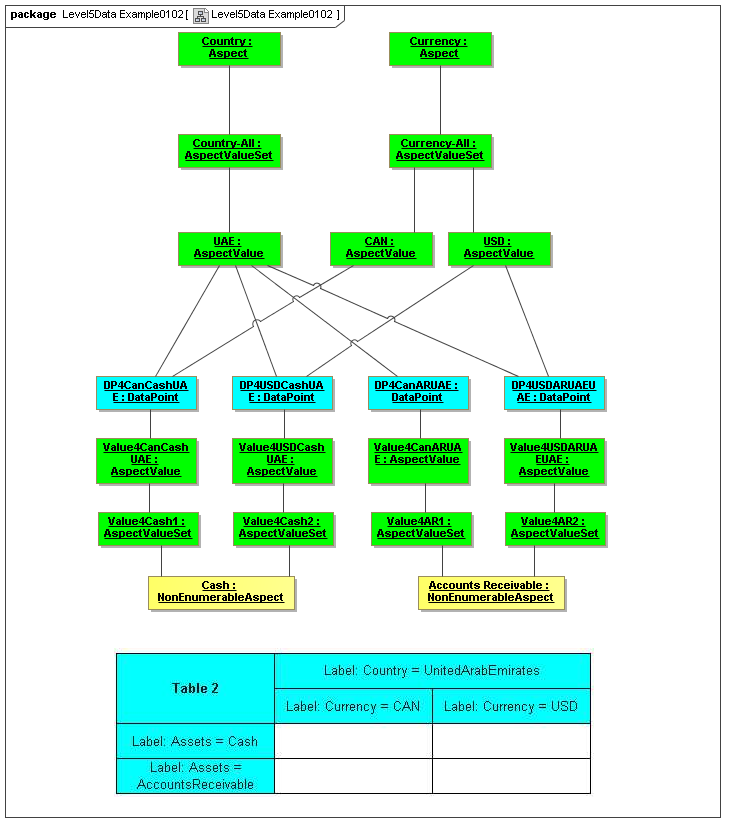
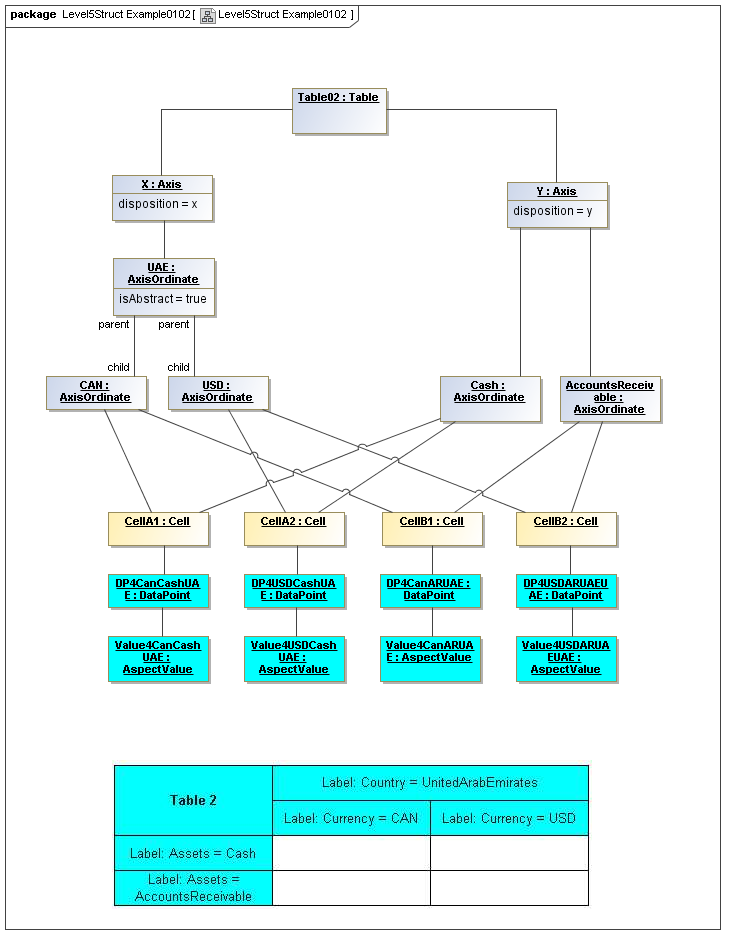
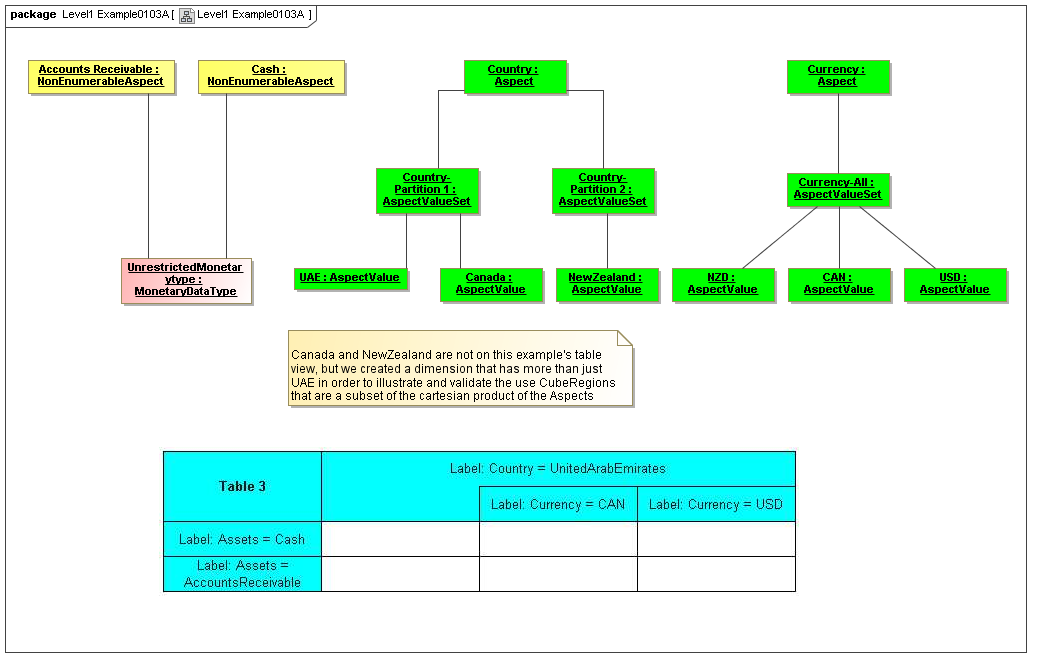
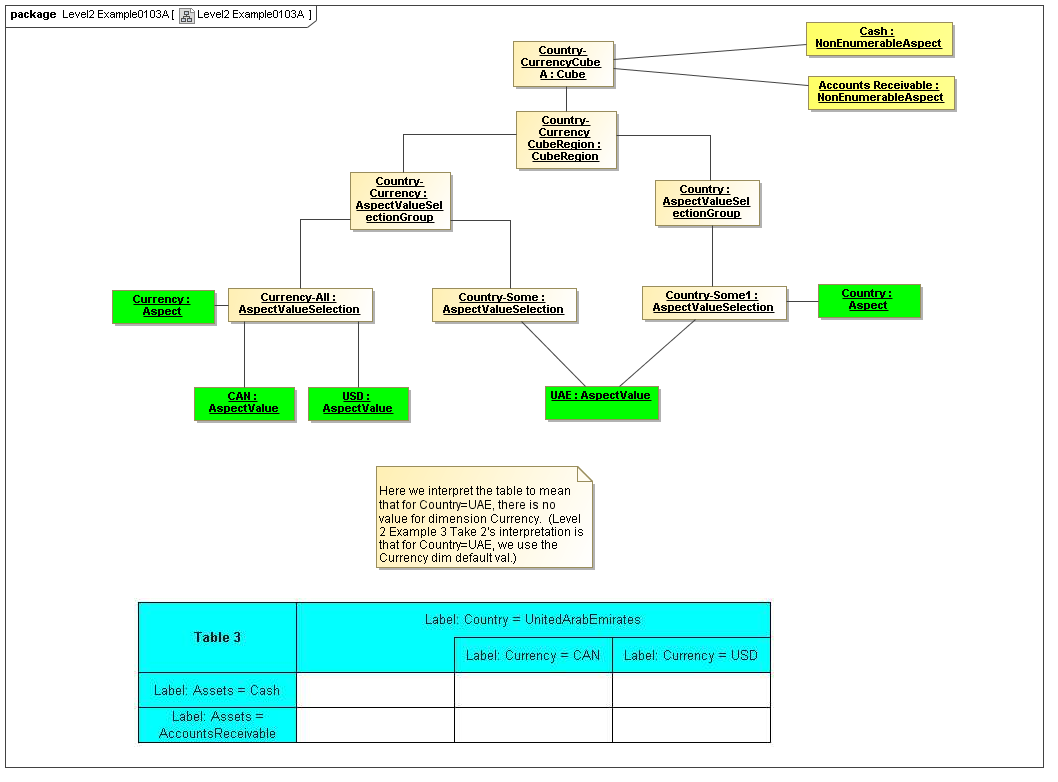
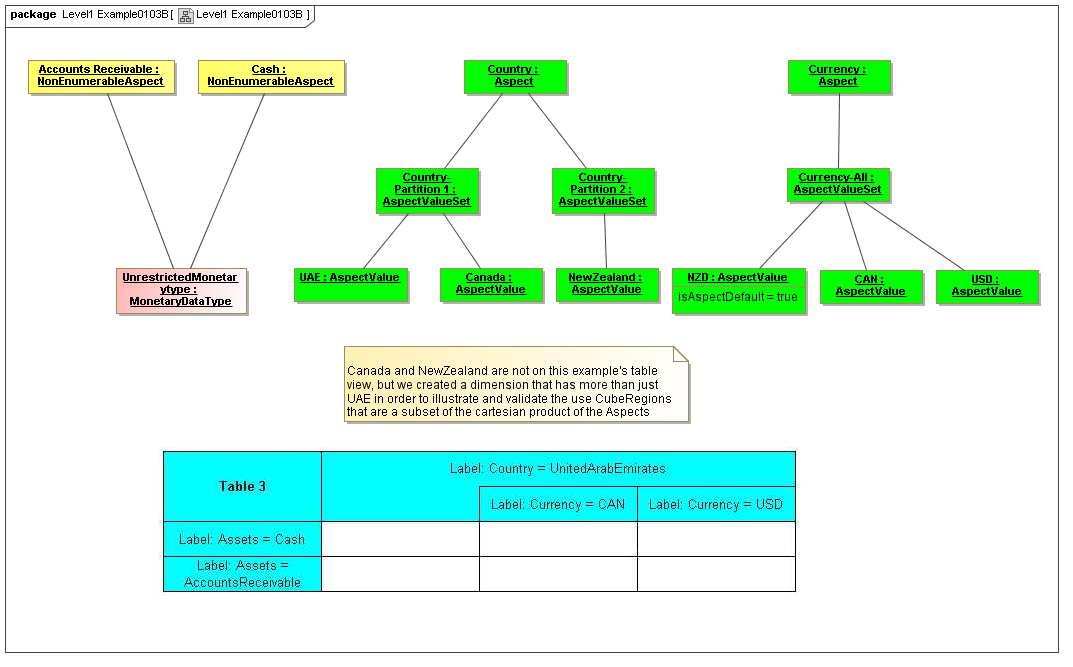
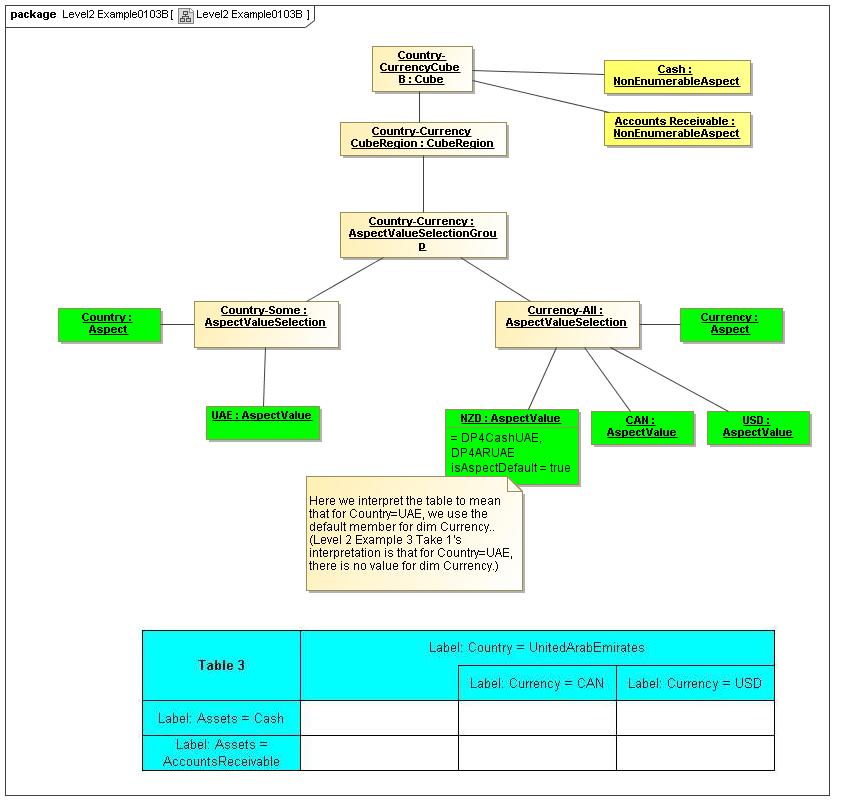
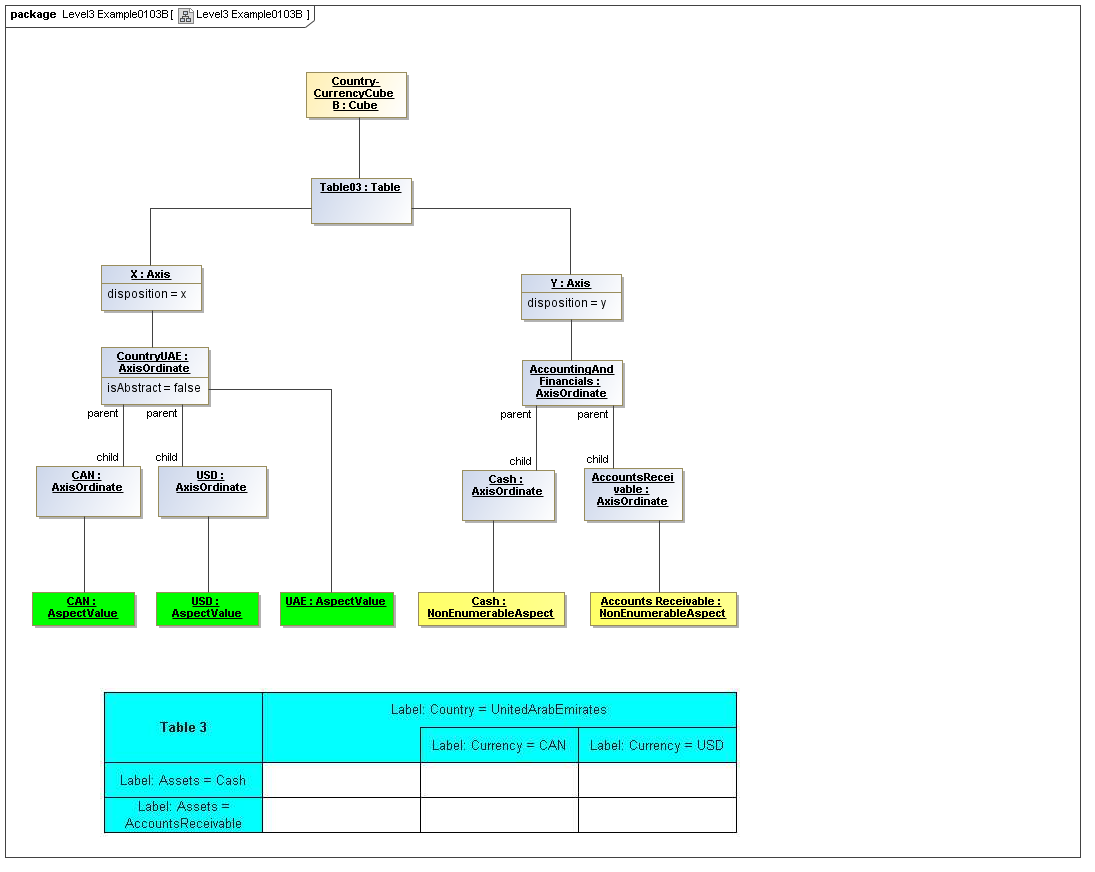
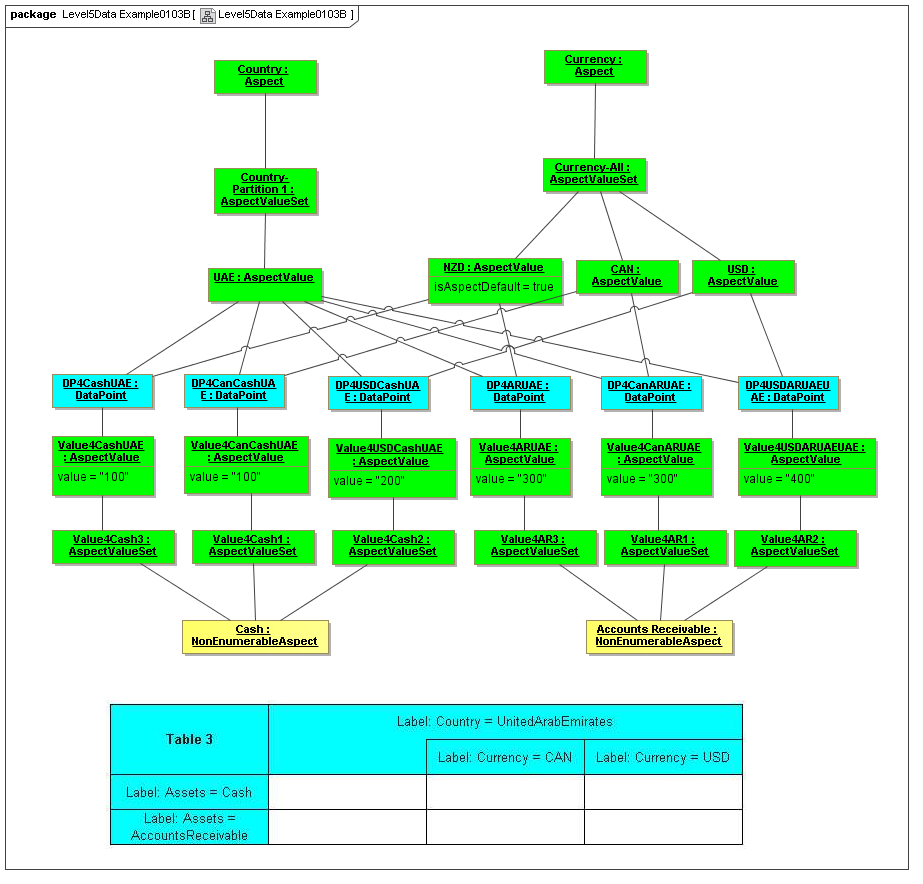
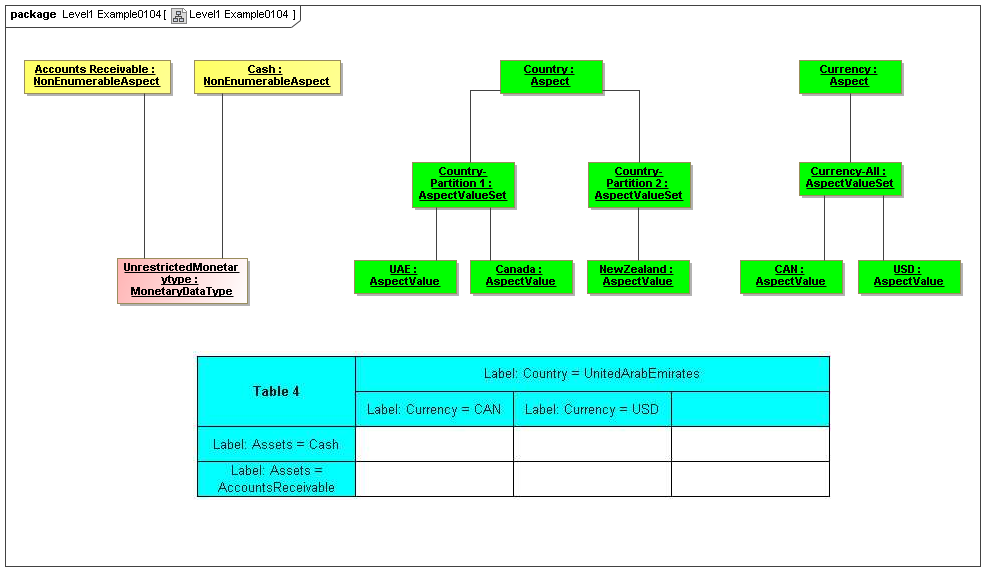
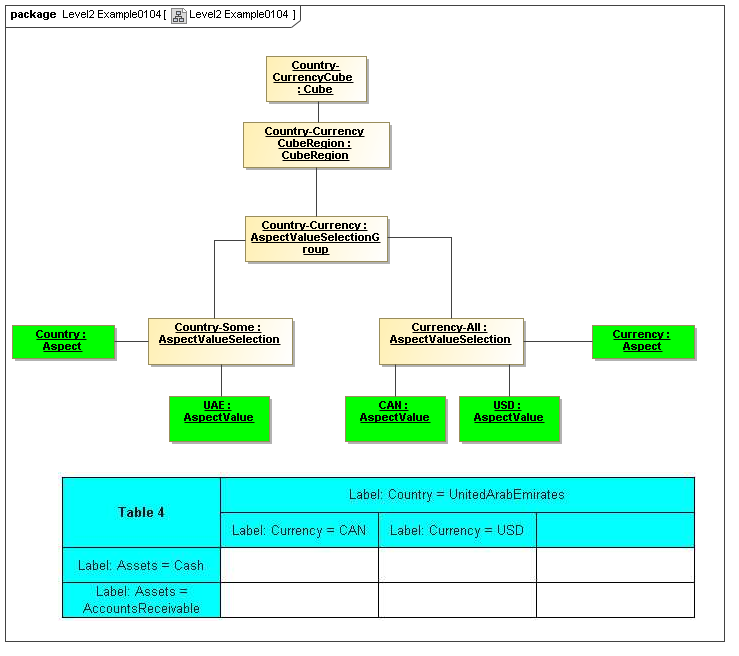
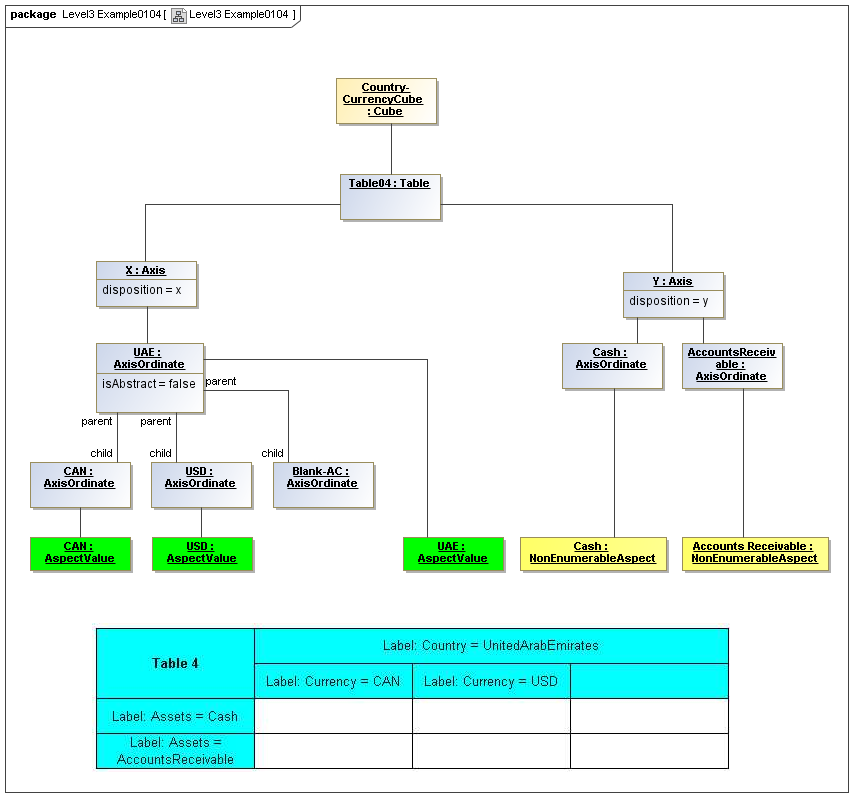
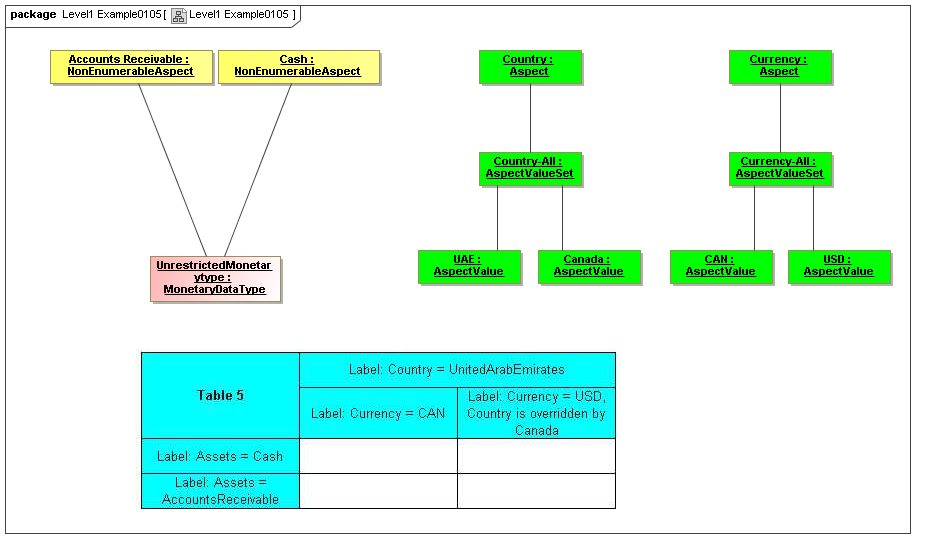
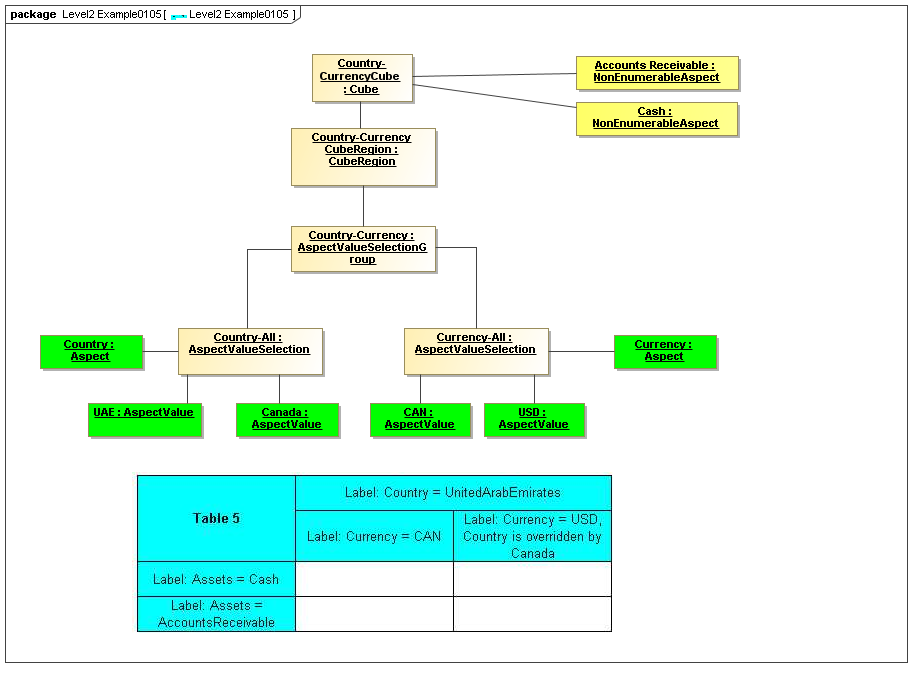
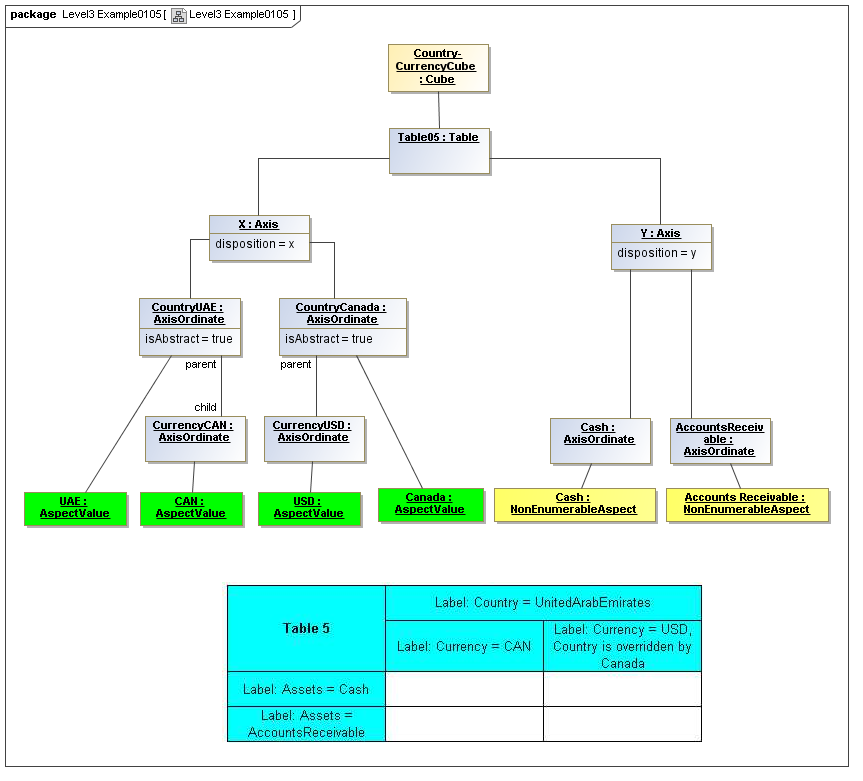
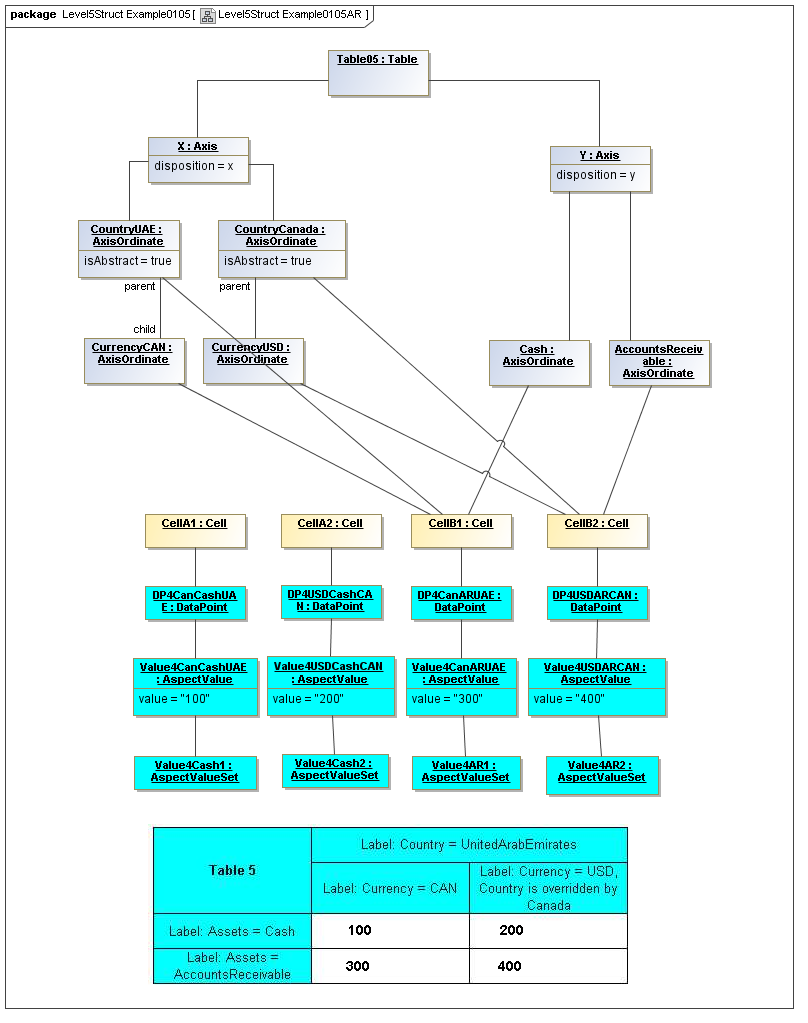
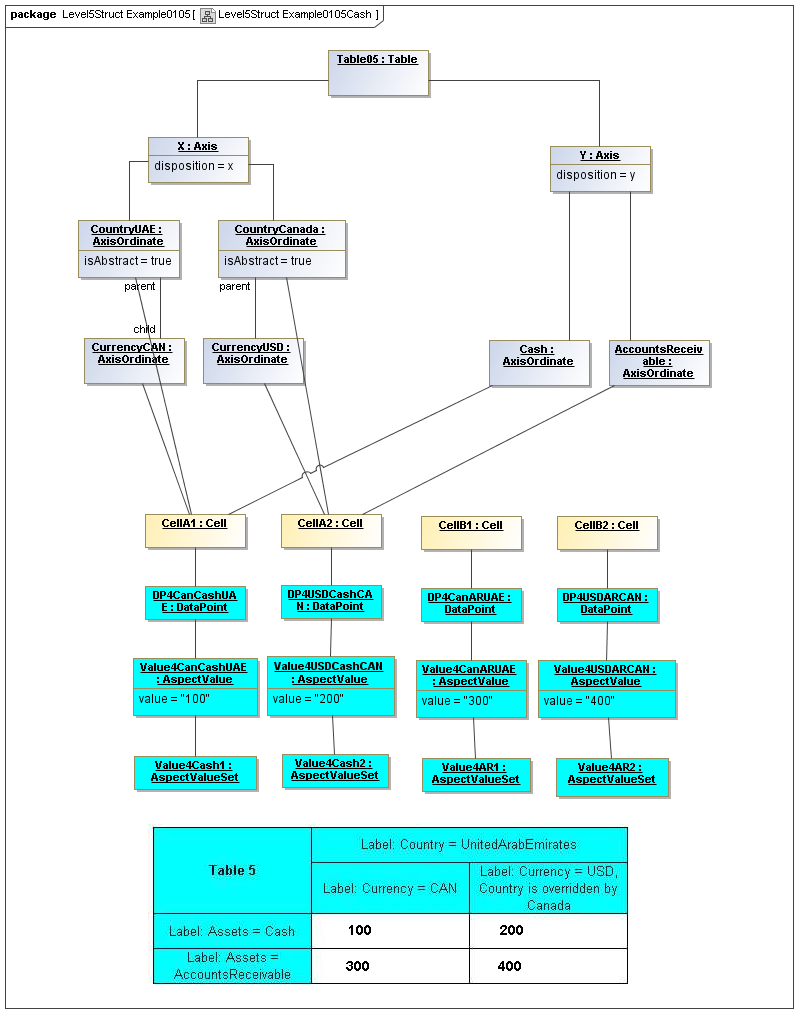
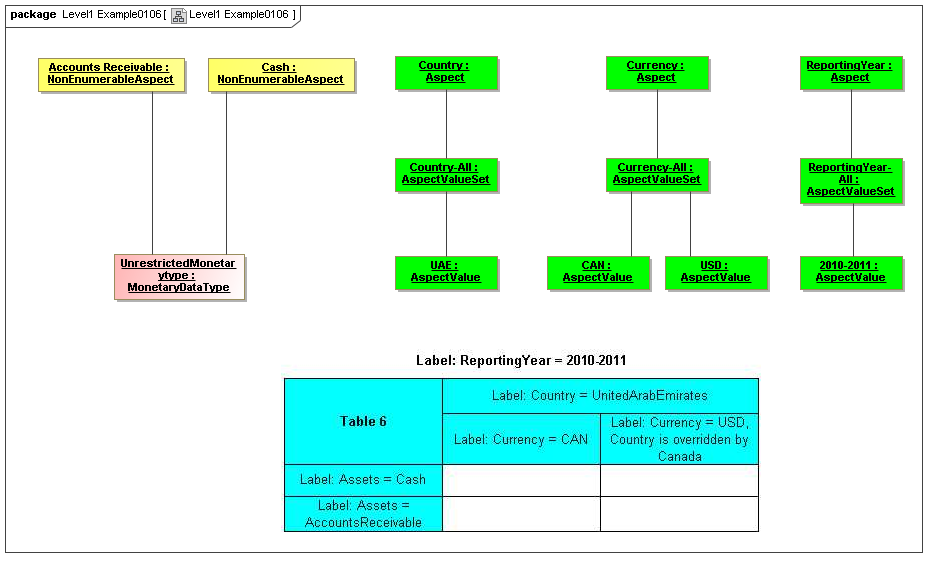
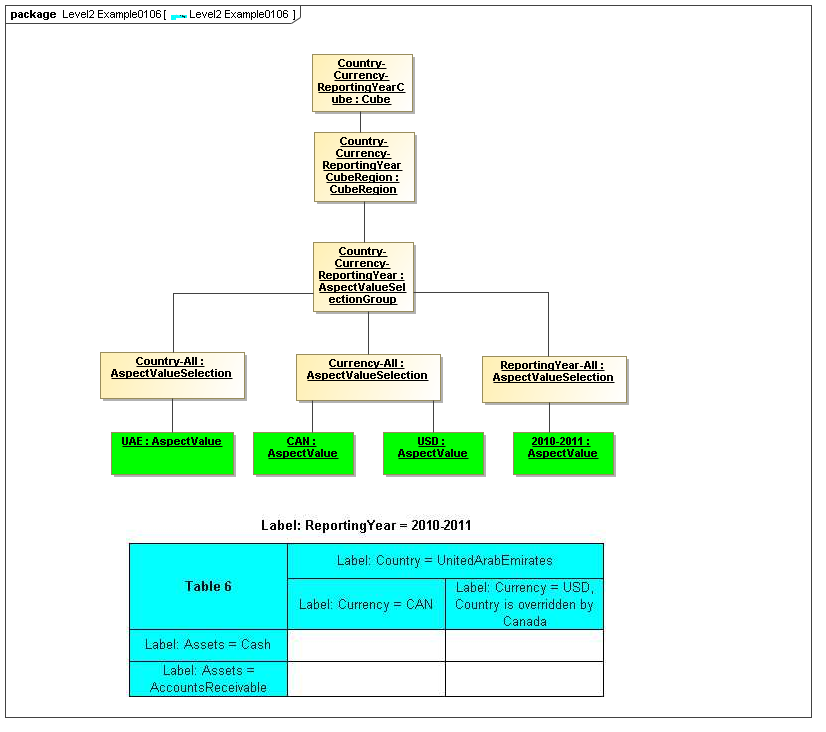
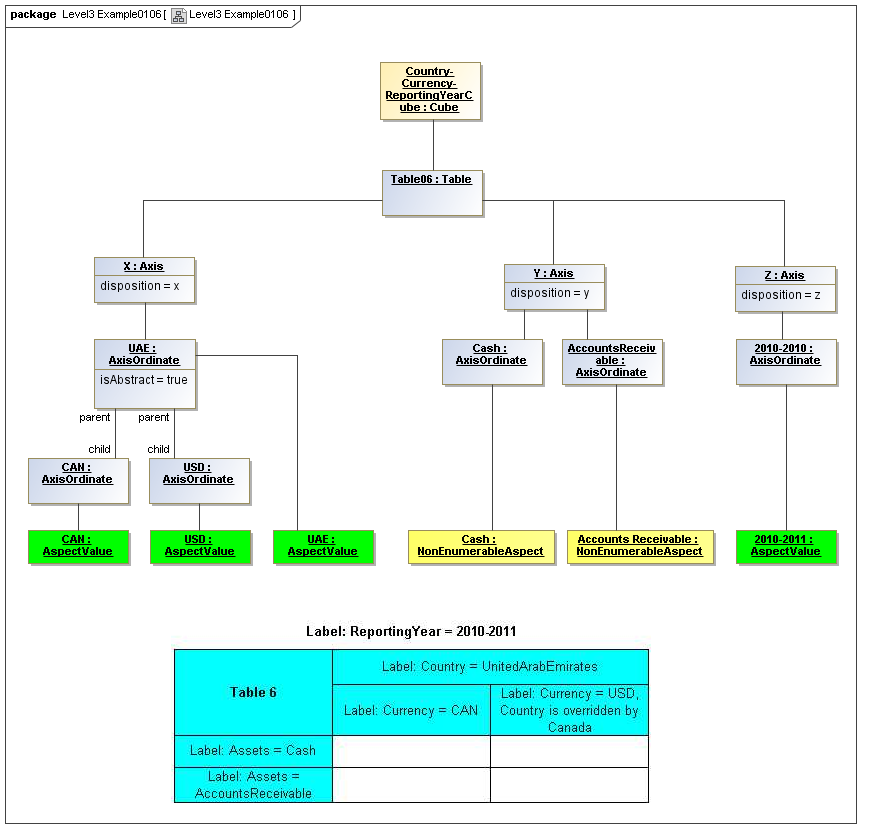
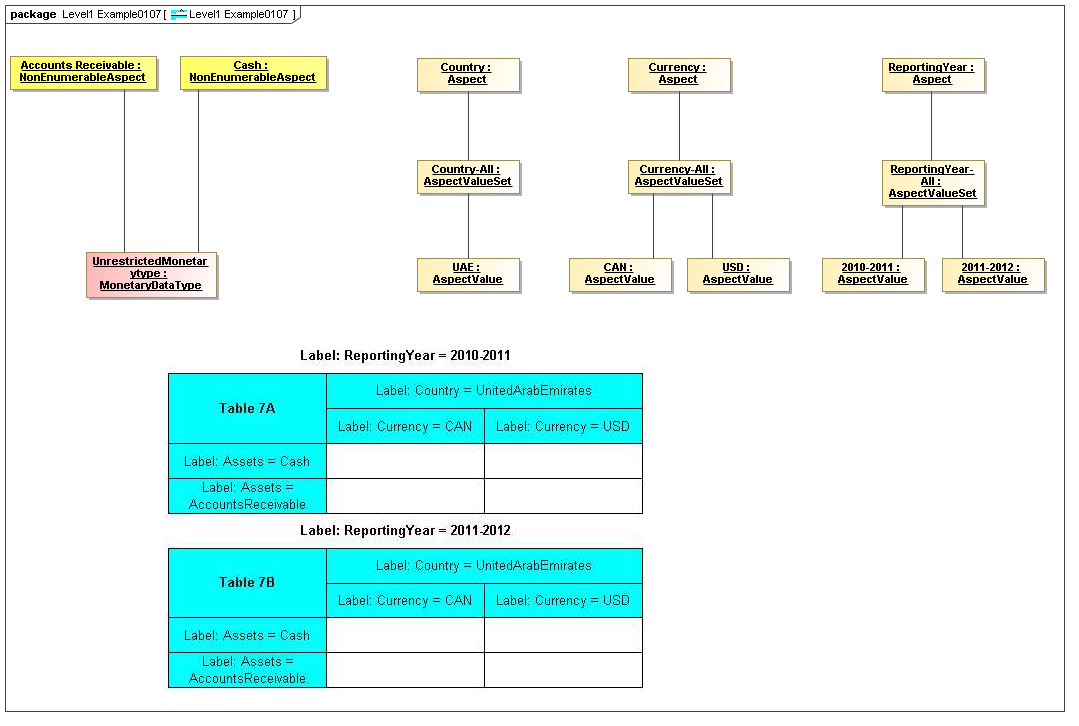
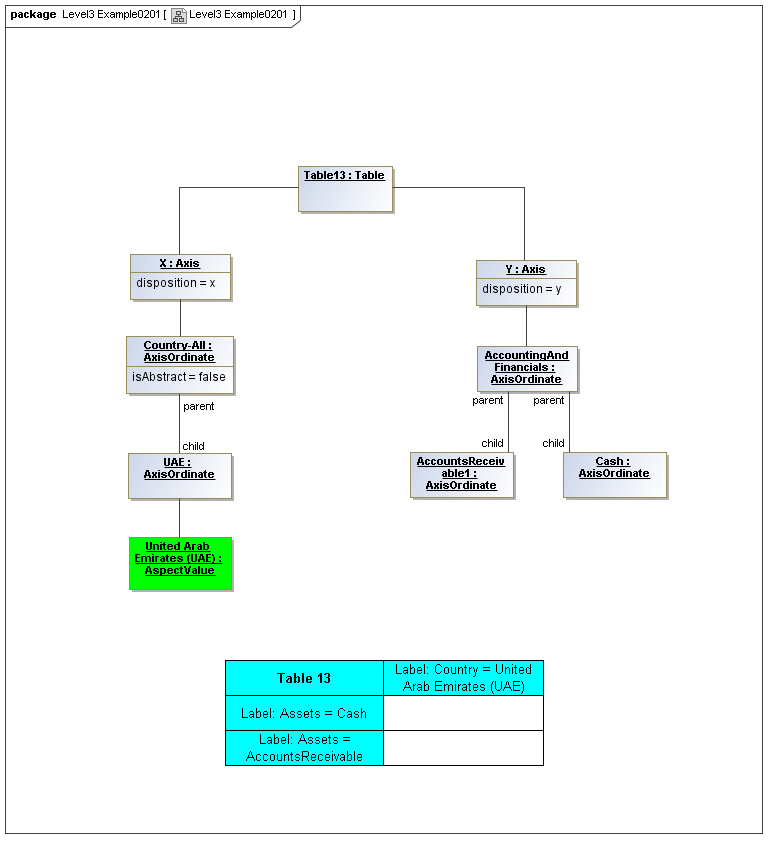
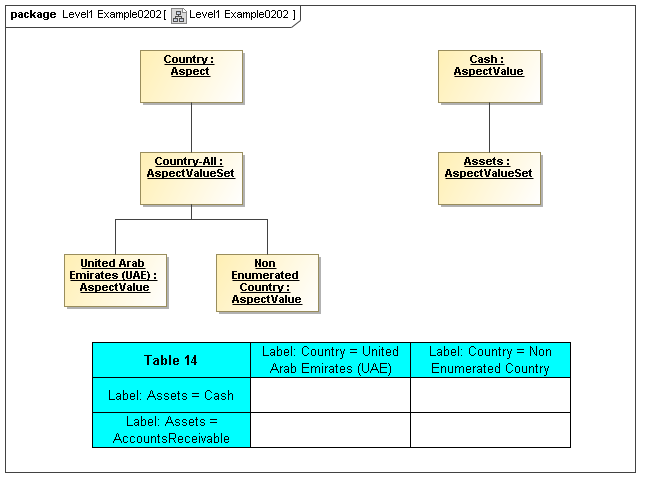
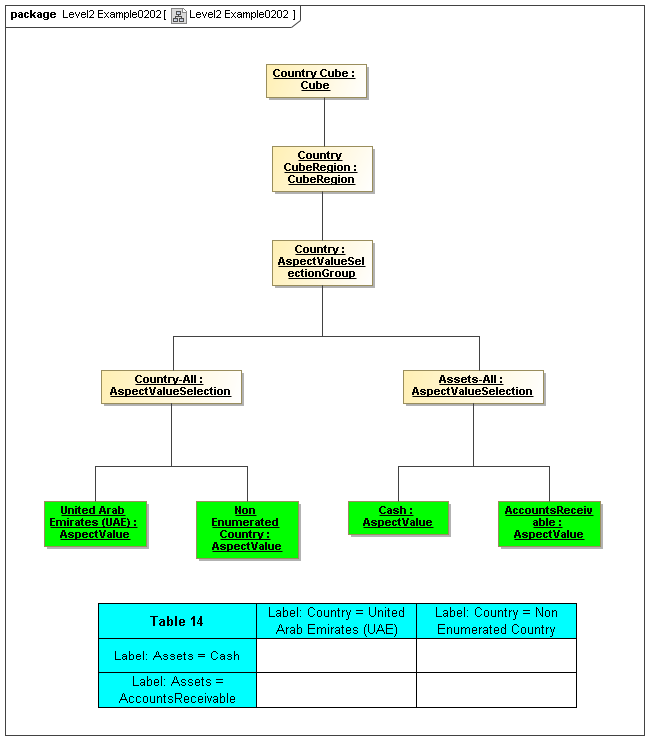
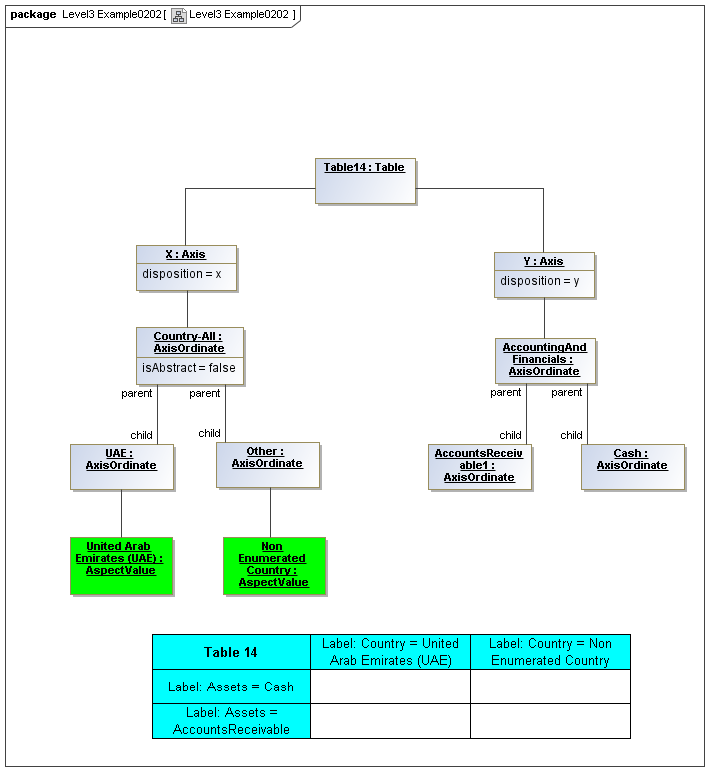
1 Overview
This document presents a meta-model for XBRL 2.1 [XBRL 2.1] and Dimensions 1.0 [DIMENSIONS] that separates the semantics defined in those specifications from their syntactical representation.
The meta-model will serve as a valuable technical resource that communicates the fundamental semantic value of these specifications.
1.1 Charter
The charter for the Abstract Modelling Task Force was defined by the XBRL Standards Board in these terms:
- Scope: The abstract modelling task force will be responsible for delivering an UML model which captures the semantics of the XBRL 2.1 core specification and the Dimensions 1.0 specification. The UML model will capture the fundamental¬structures and design of XBRL and XBRL Dimensions as standalone UML artefacts, decoupled from any specific XML syntactical details. The scope was expanded in December 2011 to include the use of these semantics by XBRL extension modules including Formula, Table Linkbase, Versioning, and to base the meta-model on accepted industry meta-modeling technology.
- Deliverables: The abstract model is likely to include use case diagrams, class diagrams, object diagrams, sequence diagrams and other such diagrams as may be later defined by the task force.
- Audience: The abstract model will be developed with a specific focus towards software engineering, as a means of establishing a common framework for communicating and understanding the XBRL technology. The audience was expanded in October 2011 to include using this meta-model to serve as the basis for the future rewrite of all of XBRL specifications, training material, and a future standard API.
1.2 Scope
The Abstract Model is intended to cover the current and future use of XBRL including by its extension modules, both in 2012 syntax (based on XML) and in future use anticipated by mapping onto database technologies such as modeled by OLAP [OMGCWM].
1.3 Model vs. meta-model
To frame the efforts of the Abstract Modelling Task Force properly, it is important to understand the distinction between modelling and meta-modelling. Whereas a model is typically a representation of some phenomena in the real world, a meta-model is more concerned about describing and defining the actual modelling framework that is used to construct the model.
As an example, consider how common modelling frameworks, such as SQL, XML and UML, would contrast against each other at the meta-model level:
- SQL would be defined in terms of tables, rows, columns, primary keys, foreign keys, etc.
- XML would be defined in terms of elements, attributes, namespaces, etc.
- UML would be defined in terms of classes, attributes, operations, associations, generalizations, etc.
In the 1.0 version of the Abstract Model, XBRL at the meta-model level had been defined in terms of concepts, facts, relationships, etc. This was deemed by reviewers to be too close to the syntax based on XML, and not reflective of the meta modeling achievable for XBRL and needed for realization of XBRL with database technologies as needed for large-scale consumption. The meta-model presented in this document describes XBRL in terms of data points (based on common usage of the term, hypercubes and regions, based on OLAP meta-modelling, and Tables based on the XBRL Table Linkbase. This meta-model is described in layers that can be mapped down to the syntactical abstractions in XML realization of XBRL, as well as to alternative realization of XBRL by OLAP implementations and other semantic modelling facilities.
1.3.1 Domain modelling
Once the traits of a meta-model are understood, IT professionals can then apply the meta-model to their task of modelling a specific domain. Meta-models are not responsible for expressing domain characteristics, but rather it is during the application of the meta-model to a given domain that domain-specific characteristics can be introduced into that specific instance of the meta-model.
Consequently, the meta-model presented in this document does not represent any specific taxonomy or domain project. However, it is anticipated that instances of this meta-model will eventually be created to communicate how XBRL has been applied in specific projects and taxonomies.
1.4 Layered modelling
A common issue that is addressed during modelling is that of scale, and identifying what level of abstraction or scale will be appropriate for the task at hand.
A fundamental principle which has guided the work of the Abstract Modelling Task Force has been to separate this issue of scale into 2 distinct layers of abstraction:
- the Primary Layer - captures the pure semantics of XBRL and thus, as much as possible, is independent of the XML syntax
- the Secondary Layer - captures the artefacts introduced by the XML syntax, OLAP based implementation, and other semantics technologies, and is thus a more direct representation of the concrete realizations of the specifications
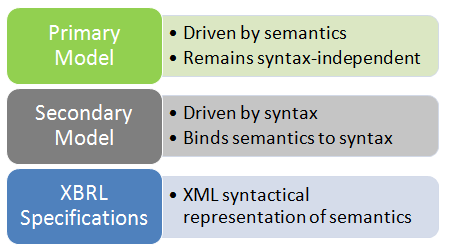
The model presented in this document is the Primary Model, with a mapping to the Secondary Model for XBRL, and is thus focused more on the semantics of XBRL than on the syntax. For this reason, the reader should be aware that syntactical artefacts of XBRL (such as Contexts, Arcs, and Locators) do not appear in this model as they have been considered to be artefacts of syntax rather than having any semantic significance.
1.5 Relationship to other work
- Table Linkbase 1.0 [TABLELINKBASE],
- Formula 1.0 [FORMULA],
- Versioning 1.0 [VERSIONING], and
- Global Ledger Taxonomy Framework [GLOBALLEDGER].
The meta-model is based on concepts and modeling technology, to the degree possible, of the Common Warehouse Metamodel [OMGCWM].
This document pertains to XBRL as defined in the XBRL 2.1 Specification [XBRL 2.1].
This document pertains to XBRL Dimensions as defined in the Dimensions 1.0 Specification [DIMENSIONS].
This document pertains to XBRL Table Linkbase as defined in the XBRL Table Linkbase 1.0 [TABLELINKBASE].
This document pertains to XBRL Formula as defined in the XBRL Formula 1.0 [FORMULA].
This document pertains to XBRL Versioning as defined in the XBRL Versioning 1.0 [VERSIONING].
This document pertains to XBRL Global Ledger as defined in the XBRL Global Ledger Taxonomy Framework [GLOBALLEDGER].
This document pertains to XBRL artefacts realized using database technologies implemented using OMG OLAP [OMGCWM].
2 Packaging
The abstract model has been broken down into these packages, each of which builds upon the next:
Primary Model
The primary model is a meta-class layer independent of concrete realization considerations, such as XML syntax, type, and particle models, XBRL 2.1 relationship sets, instance, schema and linkbases, OLAP implementation schemes in databases, and ontology implementation schemes.
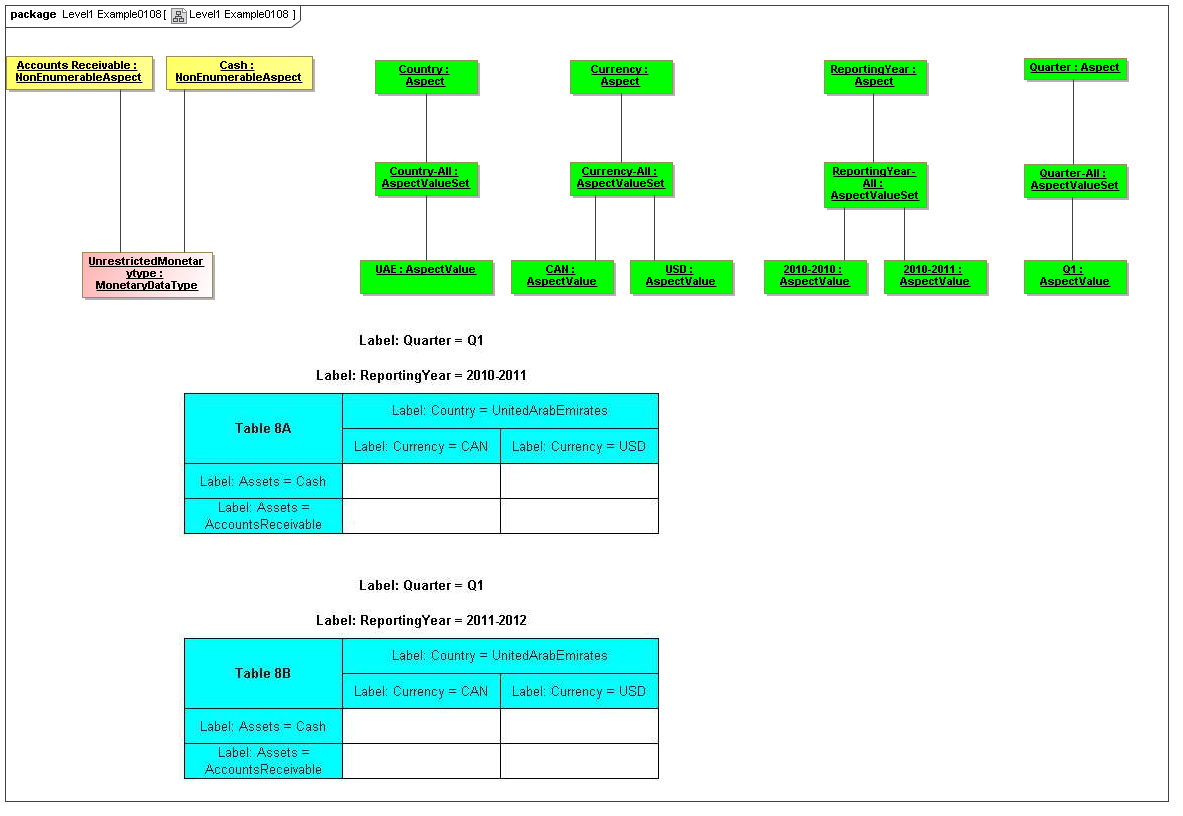
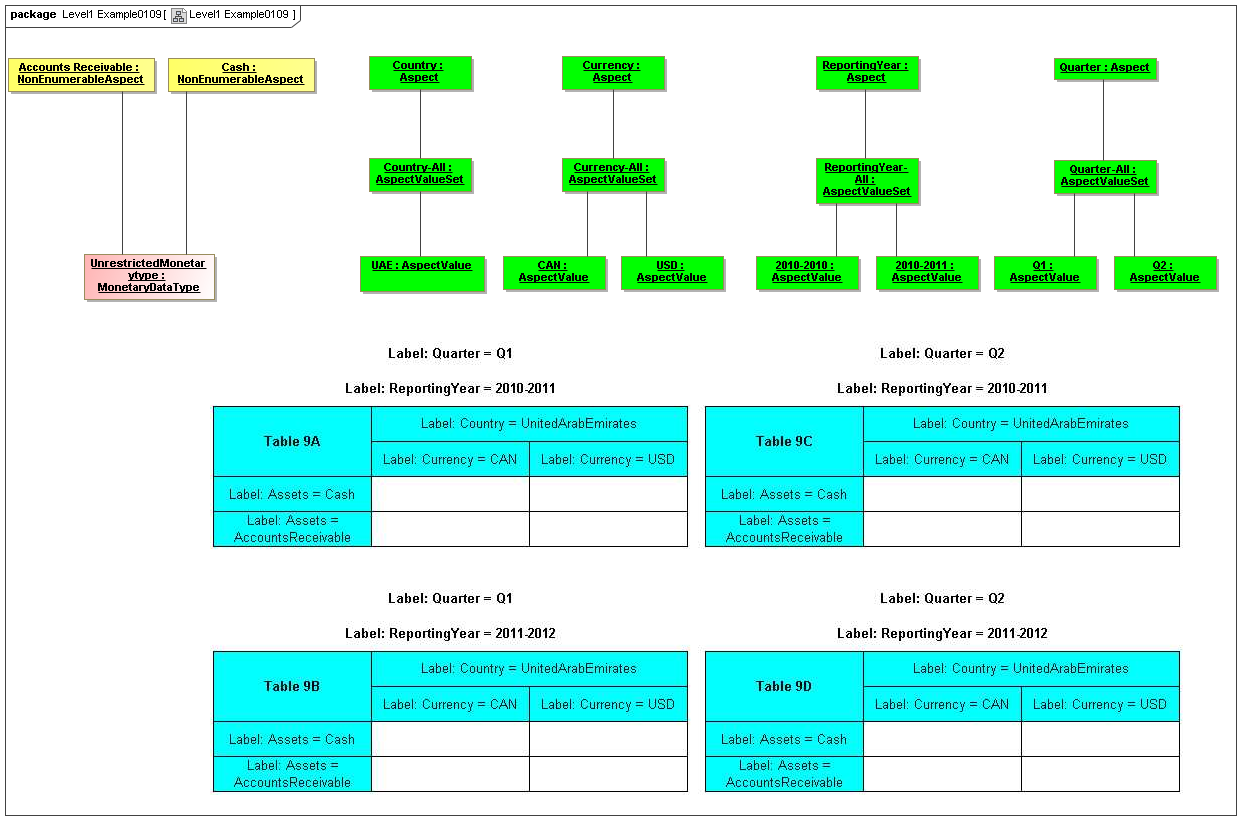
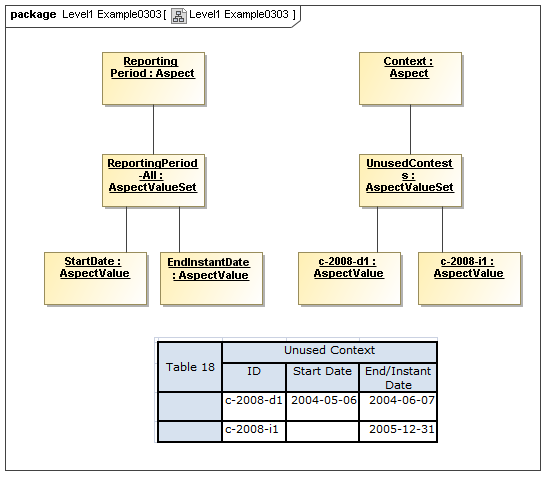
- Cross Model Elements - this package captures the tools used in meta modeling XBRL, elements that can be abstract named classes, and used for data points, aspects (classes of descriptions of data points), aspect values (specific descriptive values), and axis ordinates (points in a view bound to descriptive values).
- Data Dictionary Model - this package defines aspects which describe and identifying data points. Aspects may be enumerable or non-enumerable. This package describes relationships, between aspects, aspect values, aspect values and aspects, and between data points. It describes resources, that may be used in secondary models for labels, documentation, computatational elements, and semantic references. For those aspects participating in aspect and aspect-value relationships, these aspects and aspect-values form an ontology. If the aspect values, of aspect-value relationships in such an ontology are formally described, such as by structured description labels, they form an internal semantics model for the ontology. Aspect value descriptions may also be external, such as by use of XBRL references to external citations of defining regulations and by references to external semantics (such as OWL/RDF or SBVR).
- Instances Model - this package captures how data points, are each bound to a set of contextualizing aspect values, and a single data point value. The contextualizing aspect values, and the data point's own value are each modeled as a value of an aspect, that is typed. Data points may, through the data dictionary relationships model, have datapoint-to-datapoint relationships.
- Valid Combinations Model - this package captures how groupings of aspect values relate to cubes and cube regions of allowed (or by subtraction, disallowed) values. The valid combinations models may be implemented by hypercubes of XBRL Dimensions or by features of OLAP implementations.
- Data Points Semantic Grounding - this package captures how data points, whether instantiated or missing, relate to cube regions of the valid combinations model. This implements the constraints on data point fact instances of allowed/disallowed aspect-value combinations in cube regions.
- Table Model - this package captures how tables provide views of valid combinations of data points by relating aspect values to coordinates of viewing axes. It forms a meta-model for presentation views including those of traditional XBRL instance rendering
- Document Model - this package captures the packaging of facts (realized instances of data points) with their data dictionary model instances (representing accompanying ontology and semantic descriptions), valid combinations model instances, and table model (view definition) instances. Formulas may be included. In present XBRL realization, a document may be an XBRL financial report filing with its accompanying taxonomy and linkbases.
- Typing Model - this package abstracts the underlying types that have been defined by XBRL 2.1, for use in data points (fact) values, and the types for values of aspects of those facts.
- Secondary Model - Based on XBRL 2.1 XML syntax
The XBRL 2.1 secondary model provides a mapping for the primary model to the concrete realization technology provided by XBRL 2.1 syntax elements of instance documents, taxonomy schemas, linkbases, and extension modules.
- XBRL Instances Model - this package captures the concrete syntax forming a realization of the primary model elements by XBRL 2.1 facts, their composition, and their aspects (context elements, fact relationships and footnotes).
- XBRL Inline Instances Model - this package captures the realization of the primary model elements by XBRL 2.1 inline html rendering elements, transformations, and effective instances model.
- XBRL DTS Model - this package captures the XBRL concrete syntax Discoverable Taxonomy Set, which form a realization of model elements from the primary layer, contributing typing, structuring, ontology, and semantics that are represented by relationships, dimensions that produce aspects, labels and references, table model views, formulae, and versioning.
- Dimension Model - this package captures the realization of cube regions by the XBRL dimensions concrete syntax.
- Table Model - this package captures the realization of table view models and their axis coordinates by the XBRL table linkbase syntax.
- XBRL and XML Typing Model - this package captures the realization of the typing models provided by XML, as used by XBRL, for both data points value and aspects declaration. The model commingles atomic typing and structure by the XML particle models, whereas in the abstract model structural and typing are separated.
- XBRL Formula Model - this package captures the realization of the computational features of XBRL formula (assertion sets, variable sets, and filters).
- Versioning Model - this package captures the realization of XBRL Versioning.
- Secondary Model - Based on XBRL 2.1 Global Ledger
The Global Ledger secondary model provides a mapping for the primary model to the concrete realization technology provided by Global Ledger palette taxonomies and their instances.
- Secondary Model - Based on MOLAP Database Implementations
The MOLAP secondary model provides a mapping for the primary model to the concrete realization technology XBRL meta model realizations using database technology implemented by MOLAP technology.
- Secondary Model - Financial Reporting
The financial report secondary model provides a mapping for the primary model to the concrete realization of a financial report filing such as to the U.S. SEC.
2 Colour Schemes
A color-coding scheme has been applied to the packages, and this scheme has been propagated throughout the classes in the class diagrams. To reinforce how the packages are related to each other there has been an effort made to ensure that at least one class from each of the packages appears in the relevant class diagrams.
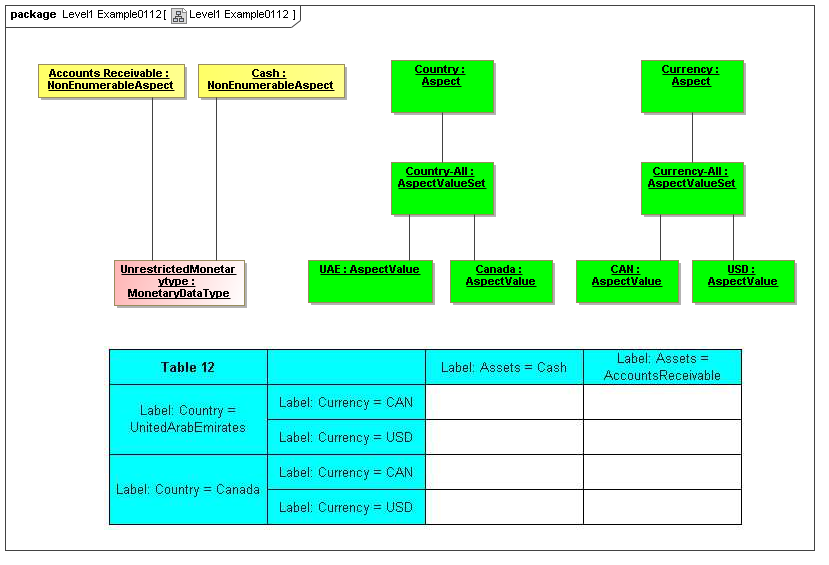
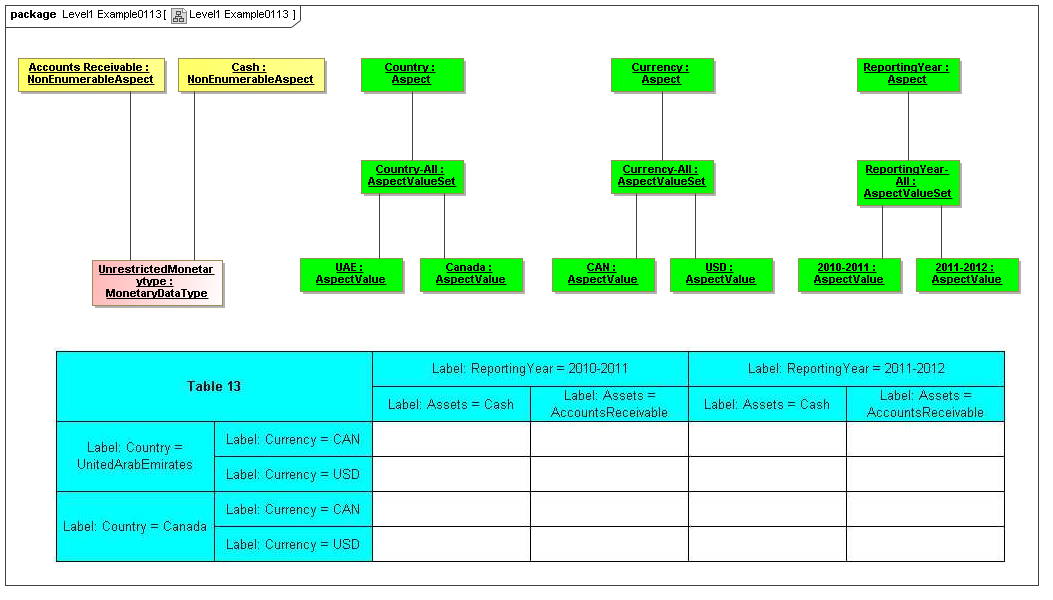
- Goldenrod - NonEnumeratedAspects (Data point values, typed dimensions)
- Green - Aspects and EnumeratedAspects (Explicit dimensions, enumerations)
- Cyan - Relationships
- Peach - Cubes
- Beige - Datapoints
3 Primary model
3.1 Model Elements
Captures the tools used in meta modeling XBRL, elements that can be abstract named classes, and used for data points, aspects (classes of descriptions of data points), aspect values (specific descriptive values), and axis coordinates (points in a view bound to descriptive values).
The primary model classes are derived from OMG MOF elements and named elements. The named elements are those that have a human readable name (such as an XBRL concept label)
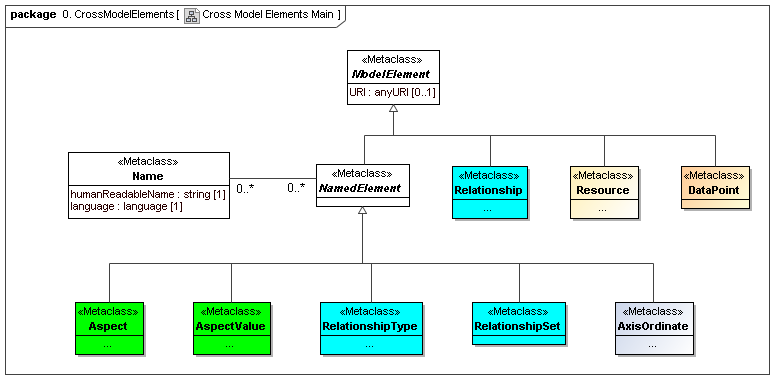
3.1.1 Class DataPoint
Semantics
The DataPoint metaclass defines a reportable item of business information contextualized by a set of aspects that identify or describe the item (this is an XBRL primary item fact), and a corresponding data point value (the reported item of business information).
Rationale
Data Points model reportable business information as classes of facts definable by the type of the data point value (including structure), and aspect values that contextualize the data point in the aspect model of the contextualization.
Properties
An DataPoint has a set of aspects values that identify or describe its instances, and an aspect value that is the data point's value.
A DataPoint has a base item aspect and Type, given by the data point value's aspect model to aspect relationship. This specifies its StructuringRelationship with other DataPoints (if any).
3.1.2 Class Aspect
Semantics
The Aspect metaclass defines an identifying or describing characteristic of a business information item data point (which is instantiated as a Fact's AspectValue, and may be organized into an ontology and internal or external semantics model).
Rationale
Aspects are identifying or classifying properties of data points, such as dimensions, names, date and unit of measurement.
Properties
A human-readable name (of the class of aspect).
An optional Type (prescribing its value and structure), and an optional explicit known-values set. Its AspectValues set may be enumerable. AspectValues may be organized into relationships (forming an ontology and possibly a semantics model).
An optional reference to a semantic vocabulary entry.
3.1.3 Class AspectValue
Semantics
The AspectValue metaclass defines a specific instance of value of an Aspect. The value is an identifying or classifying characteristic that a potentially realizable (or excluded) data point may have. If values are enumerable and known in advance, they may be organized into AspectValueRelationships which may form an ontology for the Aspect. If they have associated internal or external descriptions, they may form a semantics model for a related data point.
An instance of AspectValue is also used to model the data point's value.
Rationale
Values of aspects may form an ontology for those aspects that are classifying in nature, and in turn form a semantics model for data points associated to the aspect metaclass.
Properties
The value, which may be scalar (atomic), or structured.
A human-readable name.
An optional reference to a semantic vocabulary entry.
3.1.4 Class RelationshipType
Semantics
The RelationshipType metaclass defines a classification of relationships.
Rationale
Relationships must be identifiable and validatable.
Properties
A human-readable name.
The relationships of a RelationshipType may be limited to directed relationships.
The relationships of a RelationshipType may be restrict cycles.
3.1.5 Class RelationshipSet
Semantics
The RelationshipSet metaclass defines a collection of relationships.
Rationale
Relationships collections are manipulable for presentation, validation and classification purposes.
Properties
A human-readable name.
3.1.6 Class Relationship
Semantics
The Relationship metaclass defines a logical relationship between pairs of Aspects, AspectValues, DataPoints, Resources, and between Aspect and AspectValue, Aspect or DataPoint and Resource.
Rationale
Relationships are used to model reported data, metadata, and supporting features (such as labeling and computation).
Properties
A relationship has a pair of related elements.
A relationship has a kind. Indicating whether its logical role is that of subtype, subset, part-whole, equivalence, near-equivalence, or user-defined.
A relationship may be ordered (by having an order number).
3.1.7 Class AxisOrdinate
Semantics
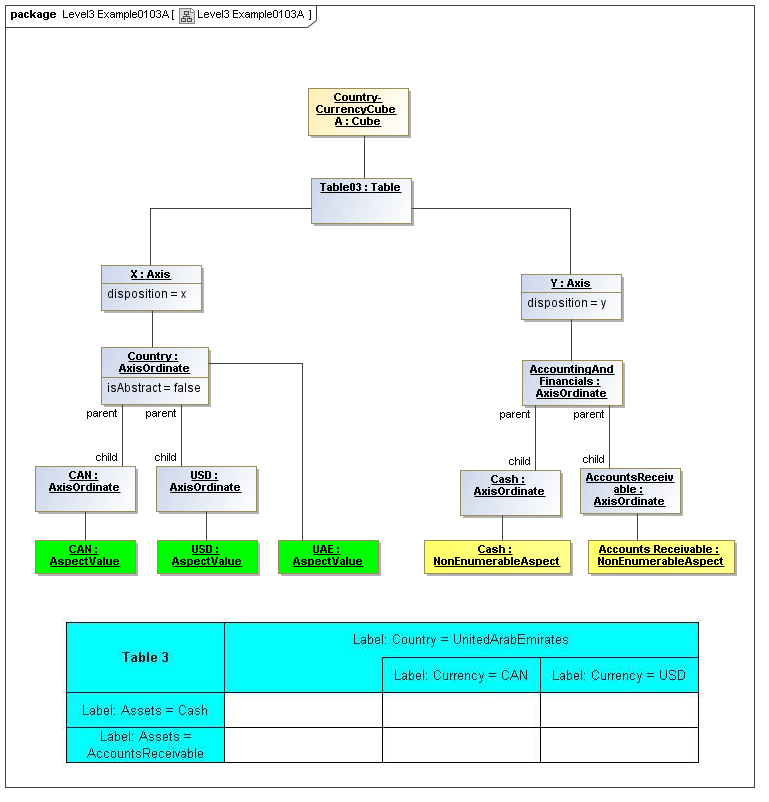
The AxisOrdinate metaclass defines a correlation between AspectValue and Table, representing a view rendering. In a Table, an AxisOrdinate of the x axis corresponds to an identification of aspect values partially specifying of data points that may participate in the column, and an AxisOrdinate of the y axis corresponds to identification of aspect values partially specifying data points that may participate in the row. An AxisOrdinate of the z axis corresponds to identification of aspects values specifying data points that may participate in the entire table (view). The intersection of table-wide (z axis), column (x axis) and row (y axis) AxisOrdinates (together called coordinates) specify and constrain the data point instance facts that may appear in a cell of a table on output (rendering) of existing facts to a table, or specify how to create a fact when a value is typed into a cell of a table-view grid control. For example if an x-axis coordinate selected aspect values corresponding to reporting period date of 2008 (for a column) and a y-axis coordinate selected an aspect value representing property type of farms (for a row), the cell of a table for these coordinates would display a fact for farms reported in 2008.
Rationale
View specification uses the notion of coordinates to select and filter data by their aspect values.
Entry forms use the notion of coordinates to specify aspect values for facts representing entry form cell values (such as XBRL instance facts and their corresponding context and unit).
Properties
Axis coordinates represent position in a view and aspect values specification for that position. In the primary model, values are represented abstractly. In a secondary model, such as the XBRL Table Linkbase, a declarator for an axis coordinate, may represent coordinate values by rules, declarative logic, reference to aspect value sets (ontologic and semantic models), and declarative expressions.
3.2 Data Dictionary
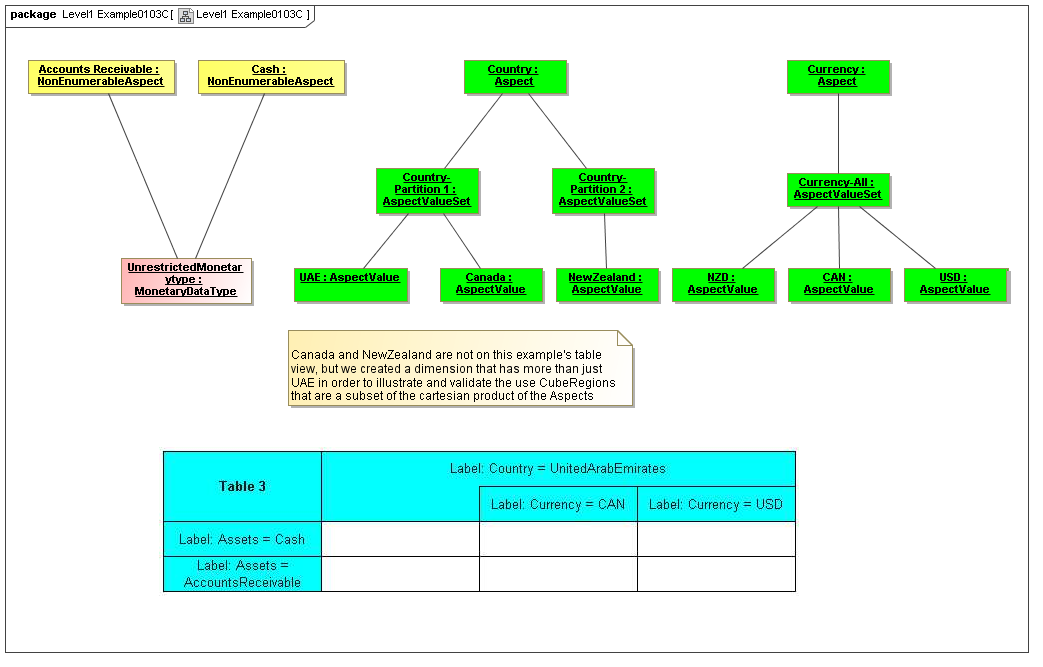
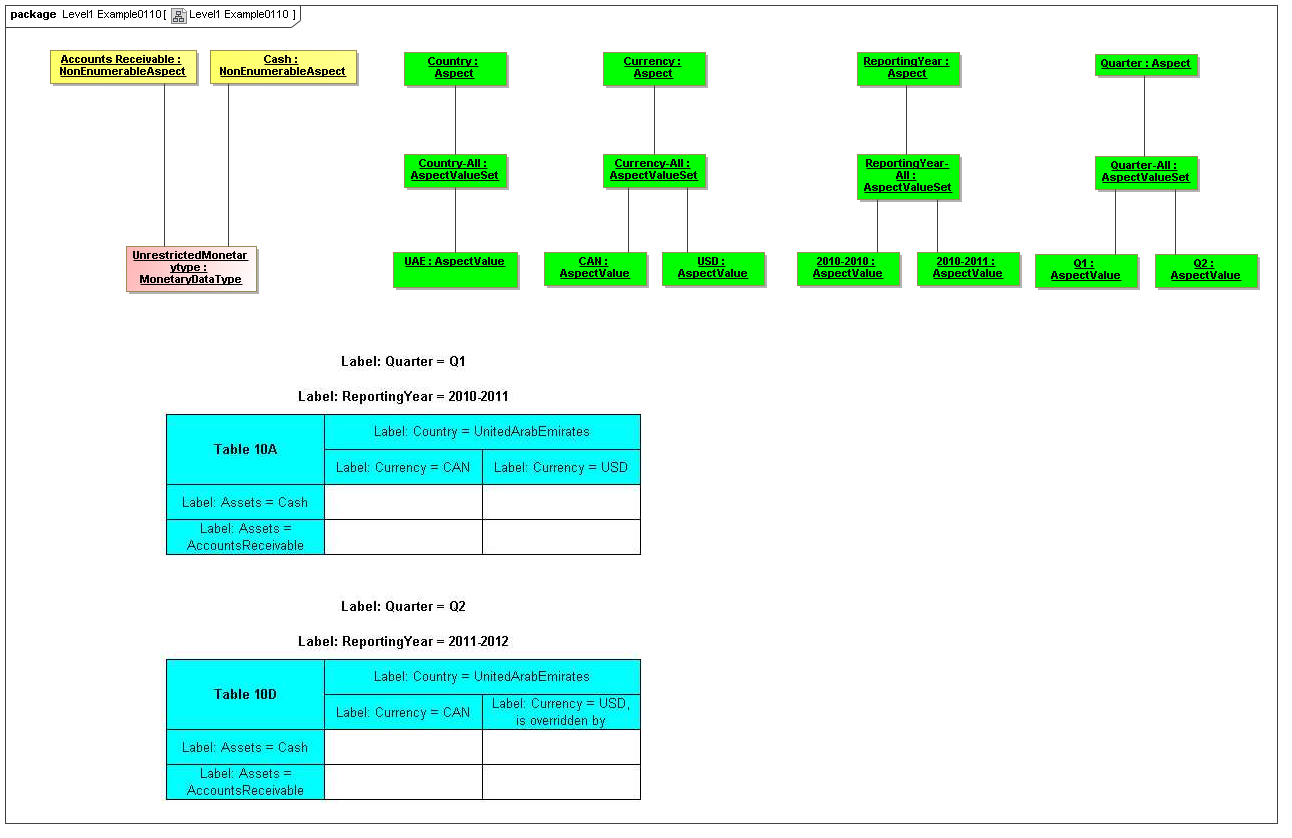
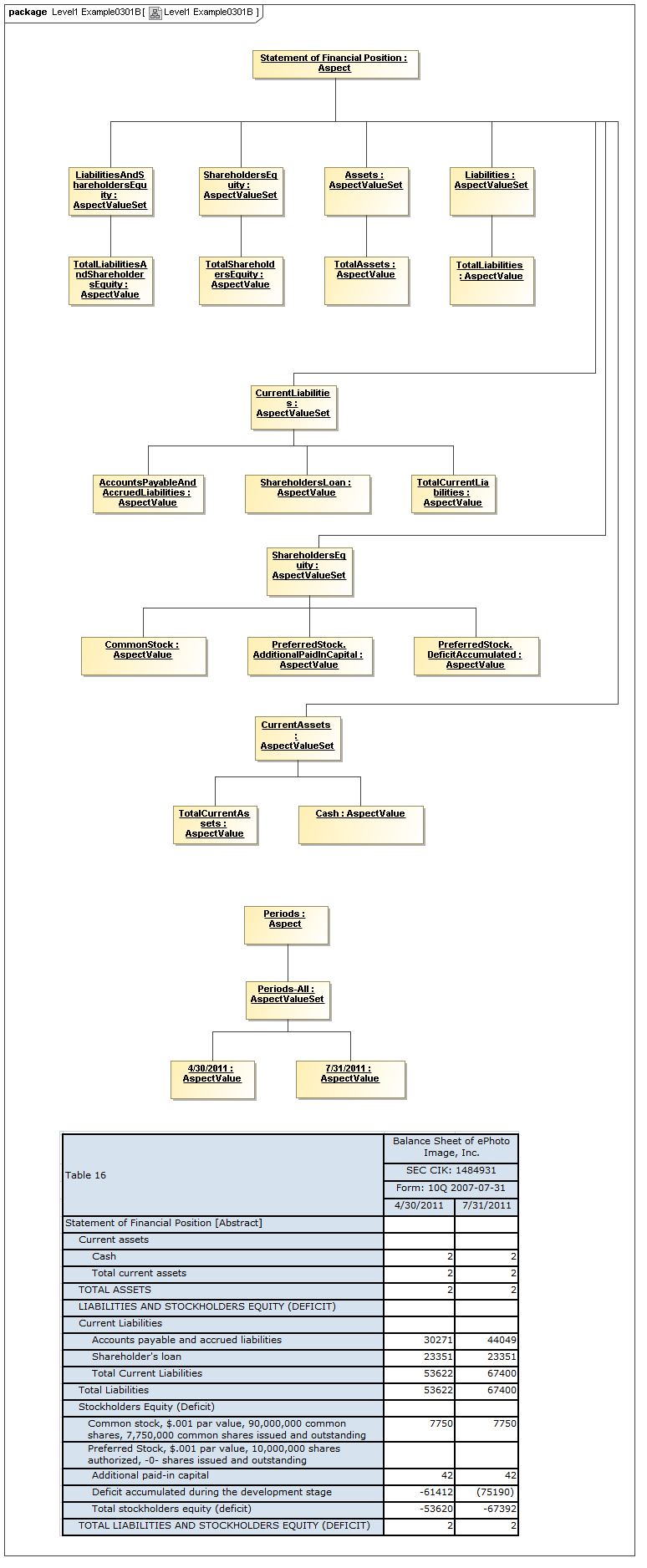
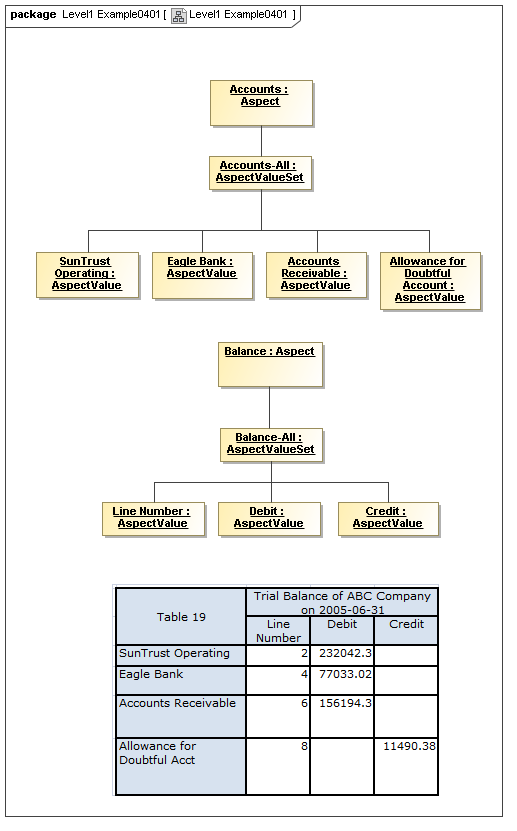
3.2.1 Aspects
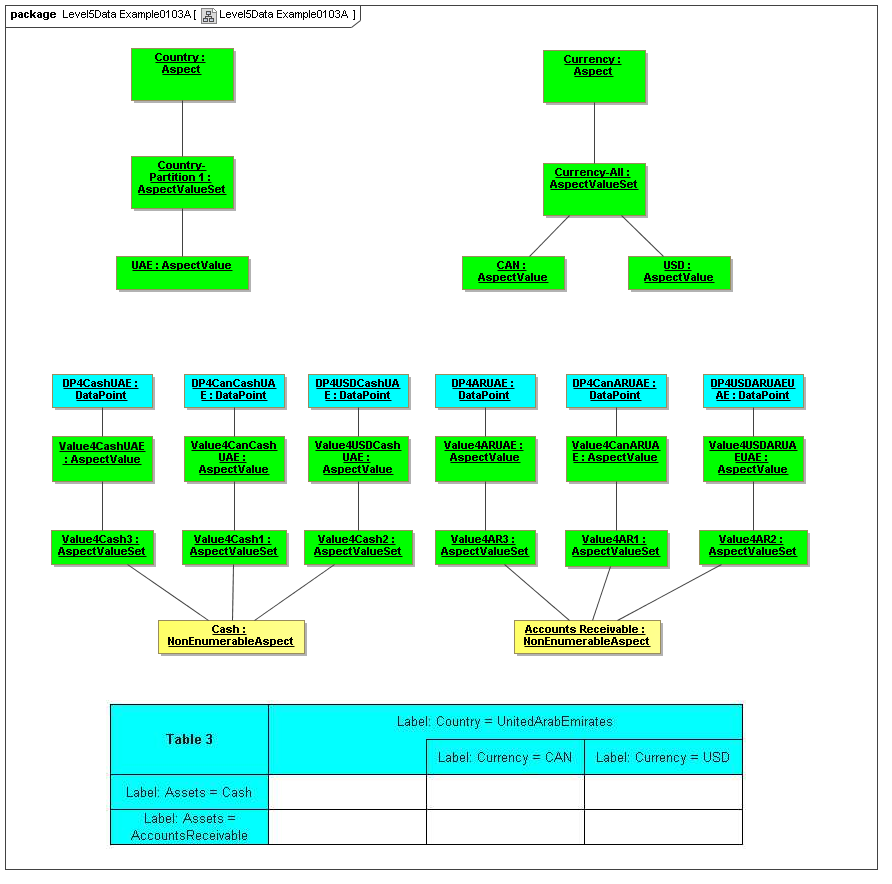
The Data Dictionary models Aspects that are the classes of identifying or descriptive characteristics of data points, which may be reported as business information items (Facts).
Aspects may be enumerable or non-enumerable. If enumerable there is a fixed, finite, and known-in-advance set of AspectValues. If non-enumerable, AspectValues are not specified within a data dictionary (class definition) and may be of a nature to be known only when business information is made available (such as from names, numbers, locations, and aspects whose instances are structured data).
For the case of enumerable Aspects, organized in AspectValueRelationships representing an identifying nature of a DataPoint (such as an element name or dimension) the AspectValueRelationships of that Aspect form an ontology (model of states of being), and may with other Aspects of the DataPoint, form a semantics model of the data point, if described formally (internally or externally). Otherwise, Aspects such as period date (such as when an account balance is taken), reporting entity (such as the business for whom the business information is reported), have no traditional ontological significance (they don't model states of the business information).
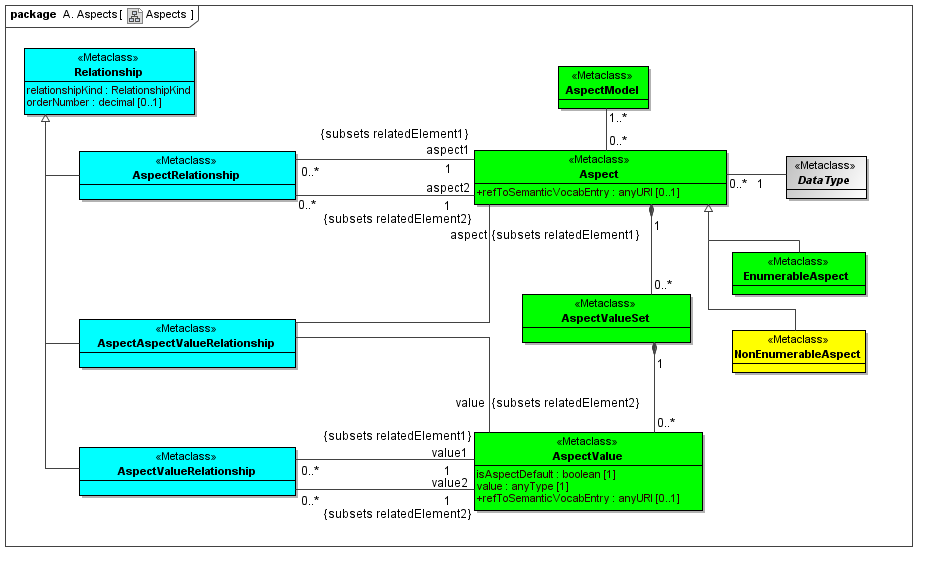
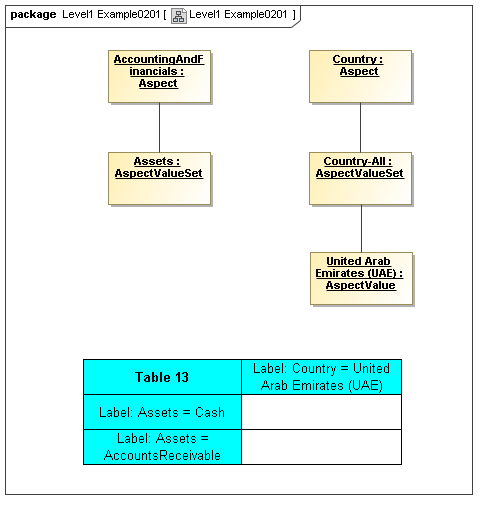
3.2.1.1 Class EnumerableAspect
Semantics
The EnumerableAspect metaclass defines aspects that have scalar values known when specifying the model, in terms of finite value sets (e.g., named values, versus infinitely large sets, such as taxpayer IDs).
Rationale
Aspects which are identifying in nature may have scalar values that are enumerable.
Properties
An EnumerableAspect has a Name and a Type specifying its values.
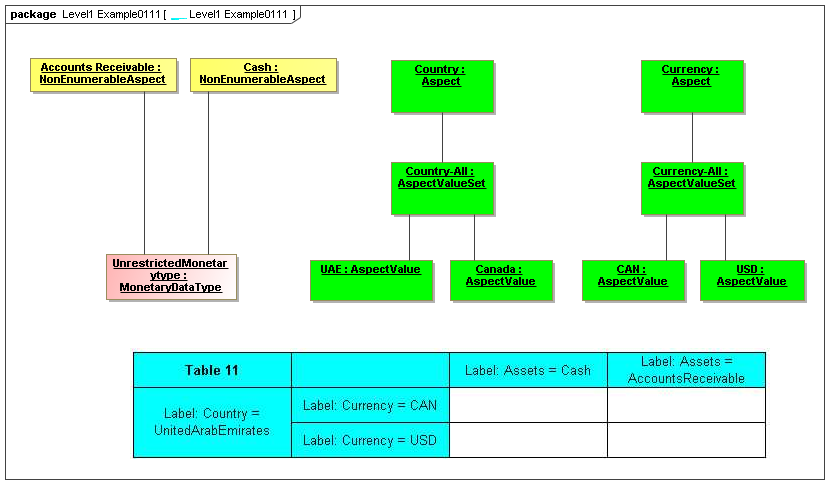
3.2.1.2 Class NonEnumerableAspect
Semantics
The NonEnumerableAspect metaclass defines aspects that have large value sets (such as taxpayer IDs, people's names, GPS coordinates, or structured data such as addresses).
Rationale
Aspect which are identifying can be treated as data, such as addresses or number sets.
Properties
A non-enumerable aspect may have a Typed value, which may have structure.
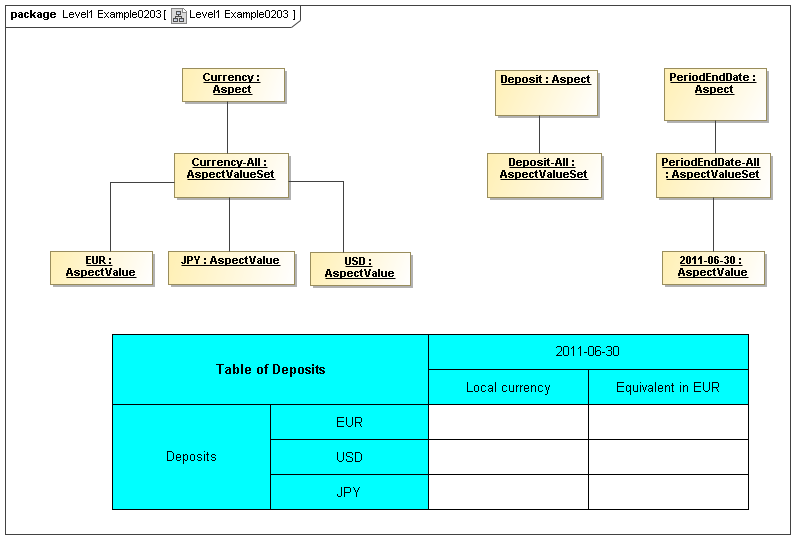
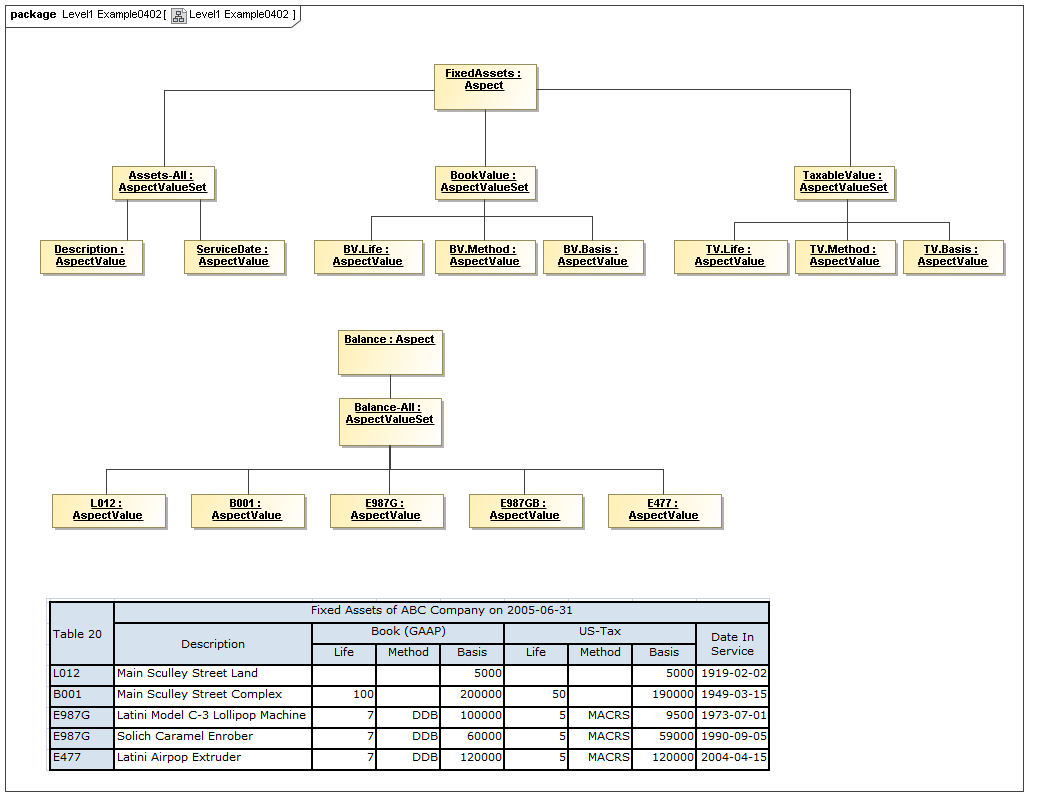
3.2.1.3 Class AspectValueSet
Semantics
The AspectValueSet metaclass defines known enumerable values that an aspect may have. These values may be organized in a hierarchy. The AspectValueSet may represent an ontology for the class represented by the Aspect. If the aspect values, of aspect-value relationships in such an ontology are formally described, such as by structured description labels, they form an internal semantics model for the ontology. Aspect value descriptions may also be external, such as by use of XBRL references to external citations of defining regulations and by references to external semantics (such as OWL/RDF or SBVR).
Rationale
Aspect Value Sets may represent hierarchical pre-specified values for an Aspect.
Properties
An AspectValueSet has AspectValues, possibly organized into a hierarchy (by AspectValueRelationships), and possibly defined by internal or external semantics definitions.
3.2.1.4 Class AspectValueRelationship
Semantics
The AspectValueRelationship metaclass defines a graph of values of an AspectValueSet, providing any hierarchy and organizational ontology.
Rationale
Aspect Value Sets may be hierarchical (or other style of) graph.
Properties
Set organization and membership.
3.2.2 Relationships
The Data Dictionary models Relationships that relate aspects, aspect values, resources, and datapoints.
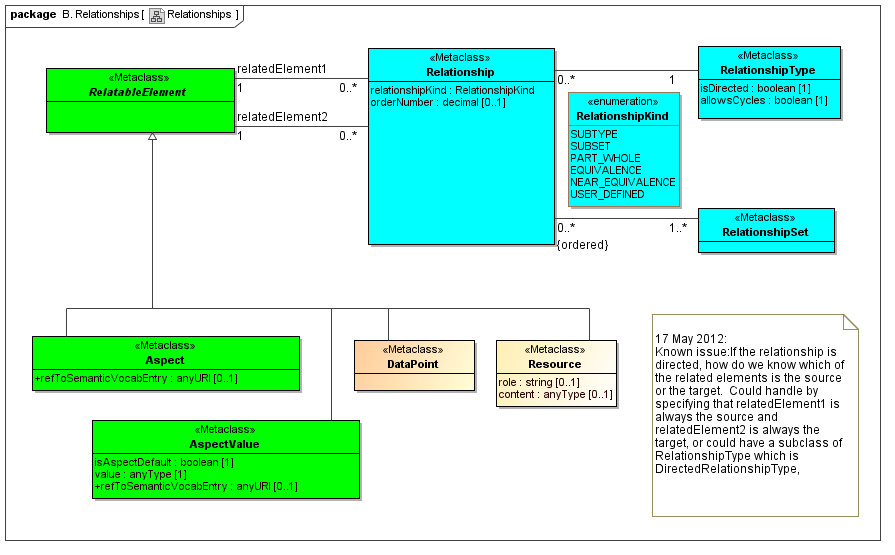
3.2.2.1 Class Relationship
Semantics
The Relationship metaclass defines a graph of values of a RelatableElement, providing any hierarchy and organization.
Rationale
RelatableElements may be organized in Relationship sets.
Properties
The relationshipKind specifies whether a Relationship is a subtype, subset, part-whole, equivalence, near-equivalence, or user-defined kind.
The order specifies an optional ordinal position of a Relationship in its Relationship set.
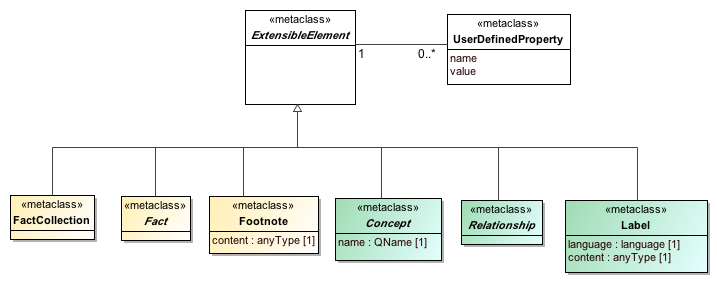
Resources are things that describe or specify Elements of the Abstract Model. Resources may be labels, documentation, references to specifications and legislation, and components of models that provide rendering and viewing, validation, transformation, documentation, and support of instances of abstract model features. Resources may be contextualized by a data type, may have a role and content (such as label).
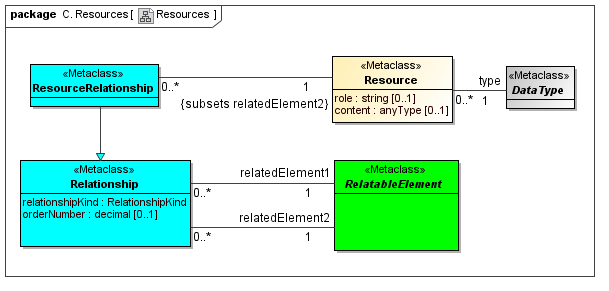
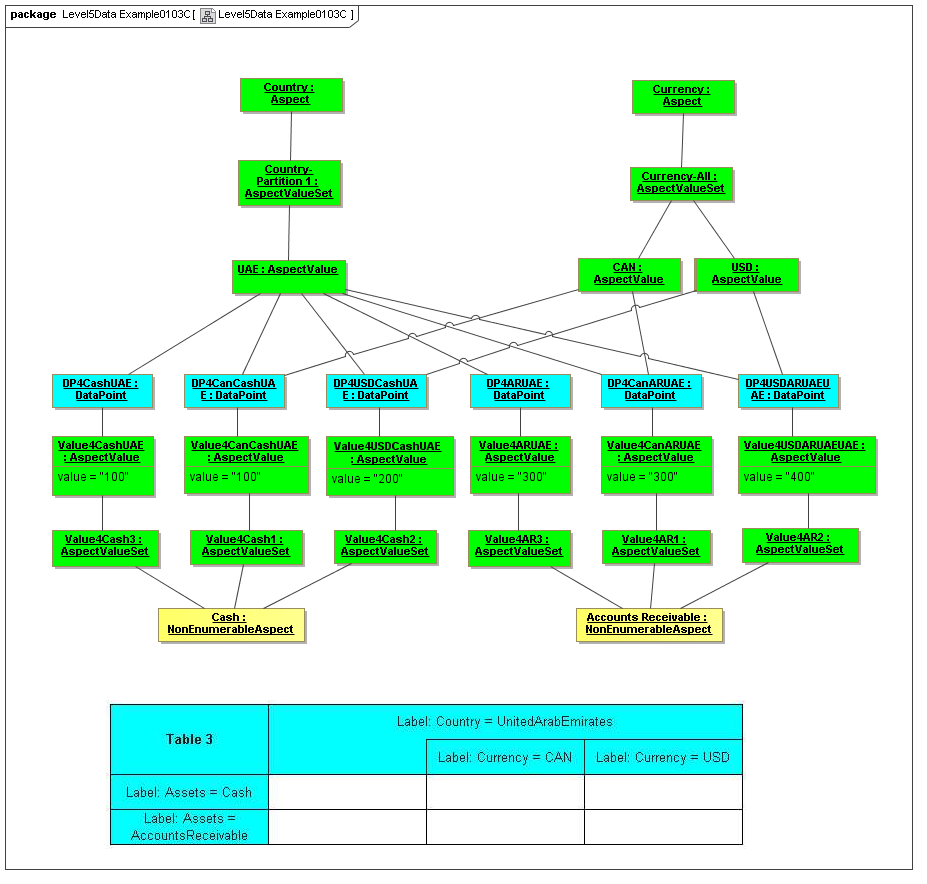
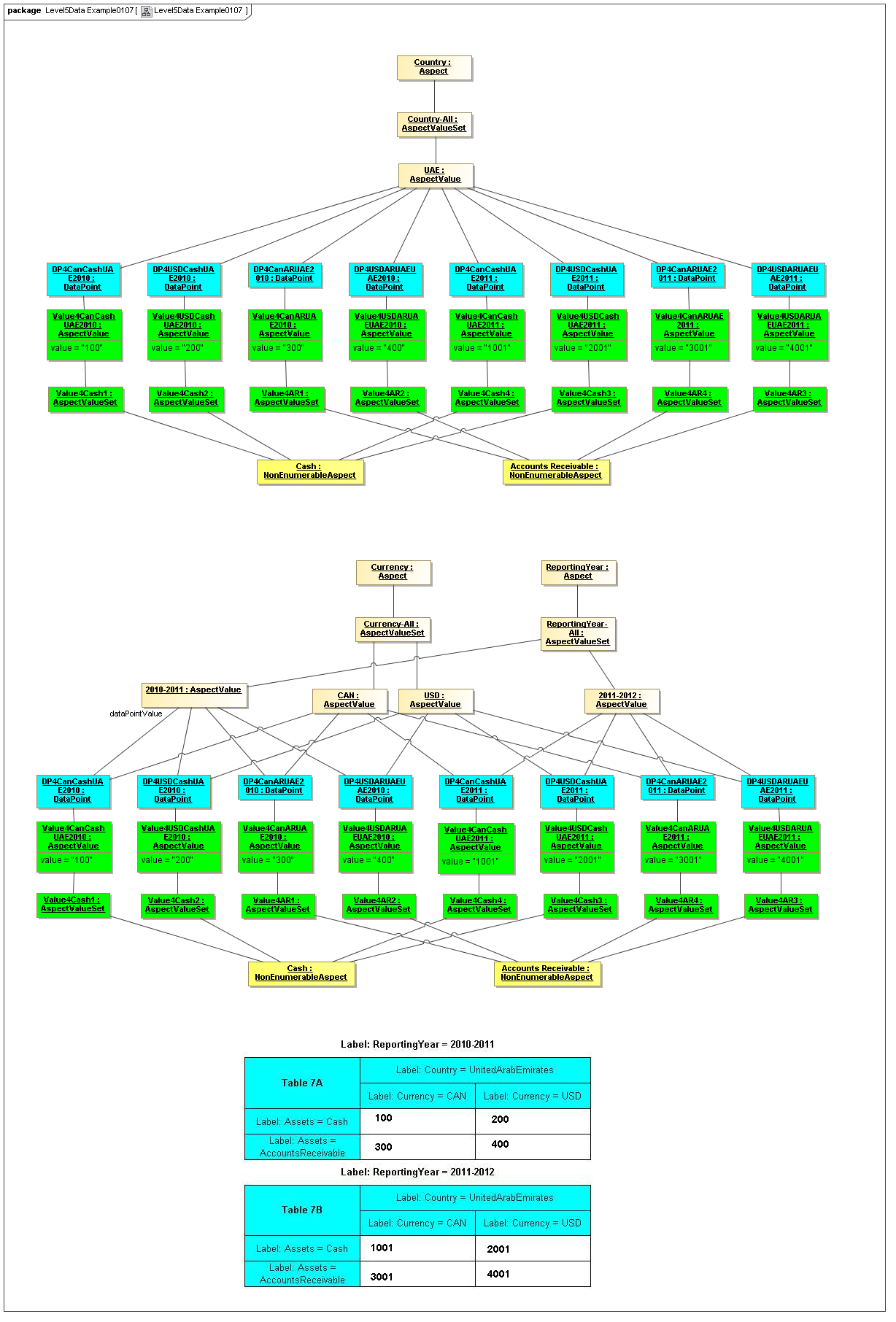
3.3 Instances Model
Captures DataPoint class instances that are facts (such as within a Document instance), that are related to the set of AspectValues that identify or describe the DataPoint (fact).
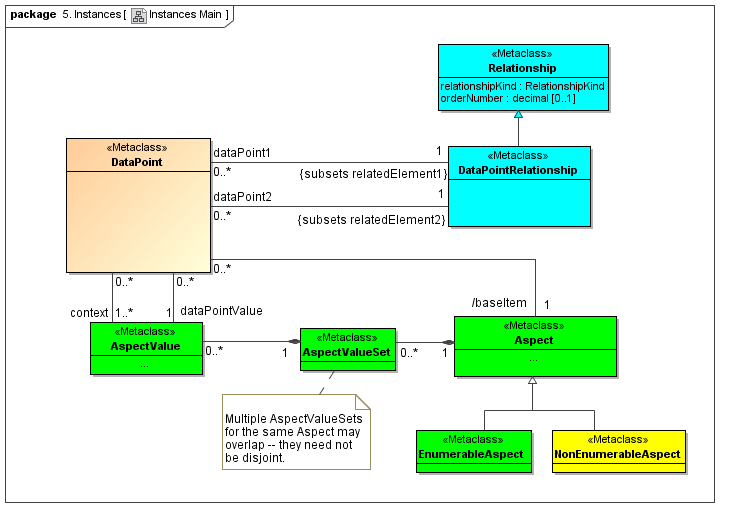
A DataPoint is a reportable business item (representing business item facts that are represented by XBRL 2.1 facts, by XBRL Global Ledger entry details, and by OMG CWM measures).
This model captures how instances of a DataPoint are identified or described by the value combinations of the identifying Aspects (from the ontology of the data dictionary model)
DataPoints may be modelled by Aspects in many ways, with Aspect modelling choices reflecting the architecture of a reporting system, politics of organizations and information technologists, opinions of the designers, and experience-set of the implementers. Earlier tradition has been to designate each ontologically identified Aspect class (such as a business reporting chart of accounts Aspect) as a DataPoint with a unique "primary item" AspectValue (e.g., a separate XBRL concept name for each chart of accounts entry). Aspect modelling provides flexibility in such approaches, allowing the architect to reduce a or expand a collection of AspectValues between aspect classes. From a legacy charts of accounts, one can re-model the model of chart of accounts by fewer primary item accounts with more dimensions, such as by designating a nominative Aspect class (like the XBRL primary item) to be "asset" for multiple classes of assets, and use dimensions (additional Aspect classes) for identification of "asset" ontology.
For example, parties reporting agricultural assets might have a separate classifying primary item AspectValue, such as an account code, for farms, wheat, corn, sheep, and cows, but in a highly dimensional reporting scheme, might identify as primary item AspectValue only 'asset', and then specify different Aspects (dimensions) for property, agriculture and livestock, with additional Aspects (dimensions) for type of animal, type of crop, and so on.
A Data Point may be related to formulas, using the Aspects pertinent to its definition, which may either be for validation purposes, informational purposes, or to produce derived information.
3.3.1 Class DataPoint
Semantics
The DataPoint metaclass defines a class that is a unit of reported information (either an element of such information with FactValue or a structured aggregate of such information).
Rationale
DataPoint instances of reportable business information are Facts.
Properties
A DataPoint may have an AspectValue instance that is its FactValue (reported business information).
Each DataPoint has a set of AspectValues that identify or describe the DataPoint. Each DataPoint is related to the AspectValues (that identify and describe it) whereas each DataPoint is related to the set of Aspects (that have AspectValues for the Fact instance).
A DataPoint may have a StructuringRelationship with other DataPoints according to its Type
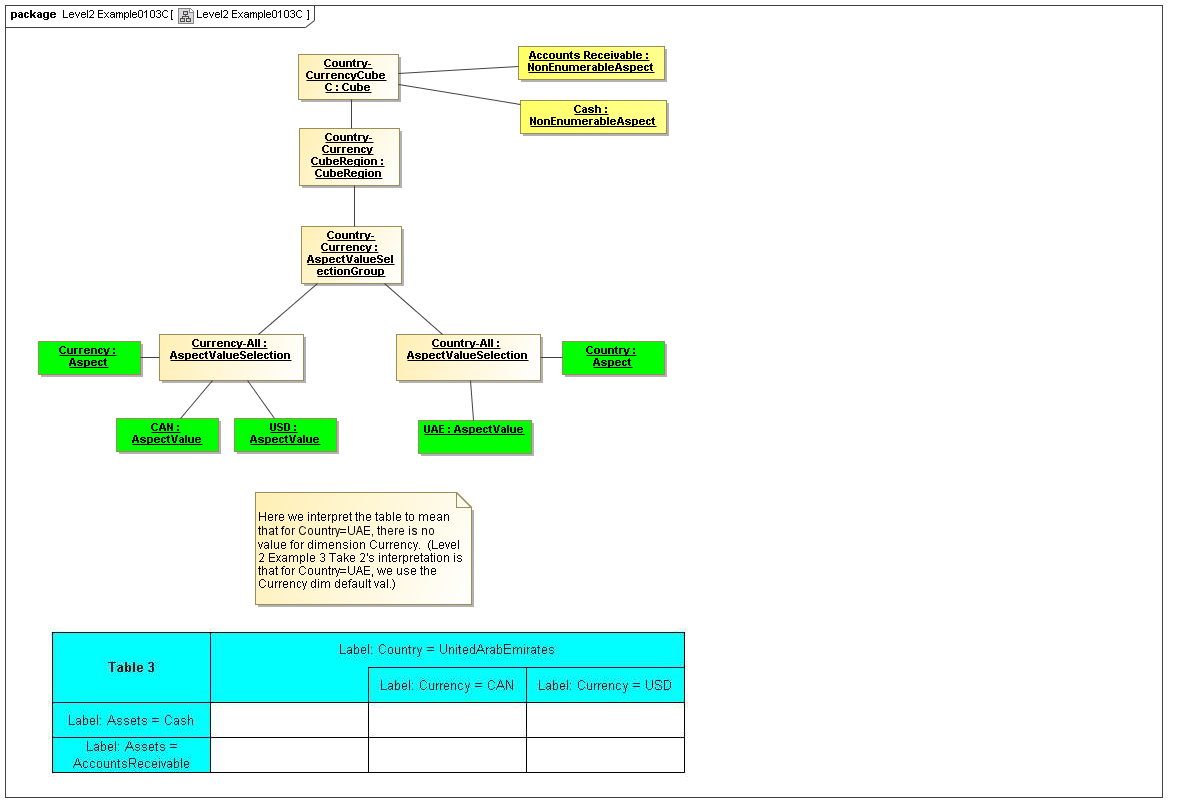
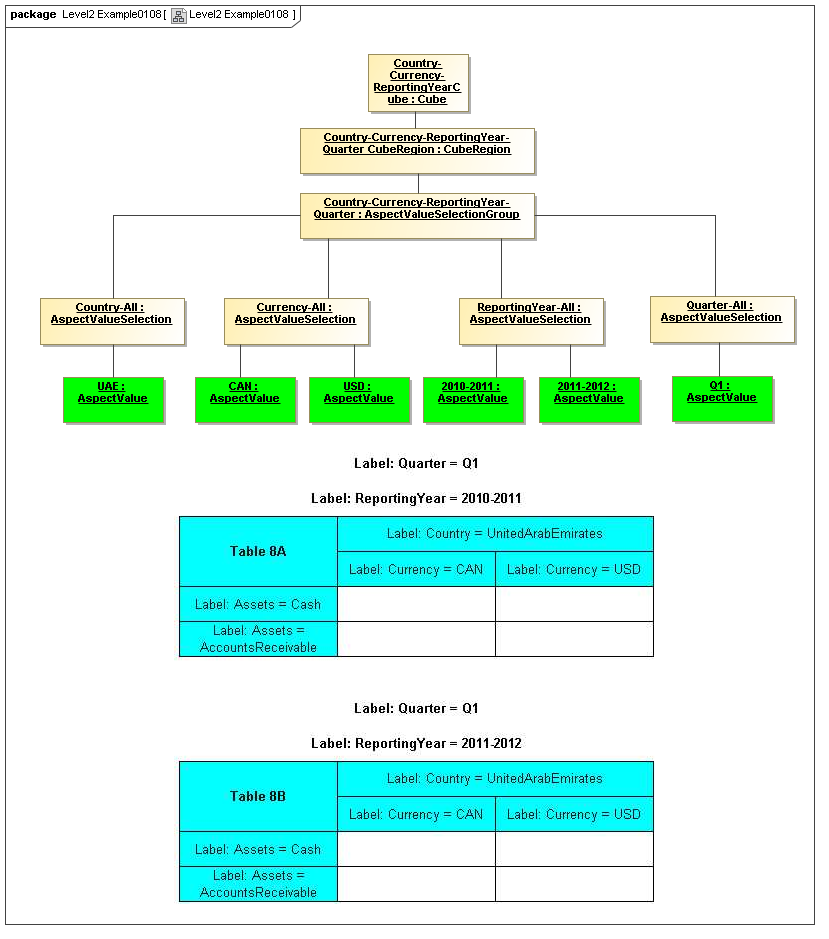
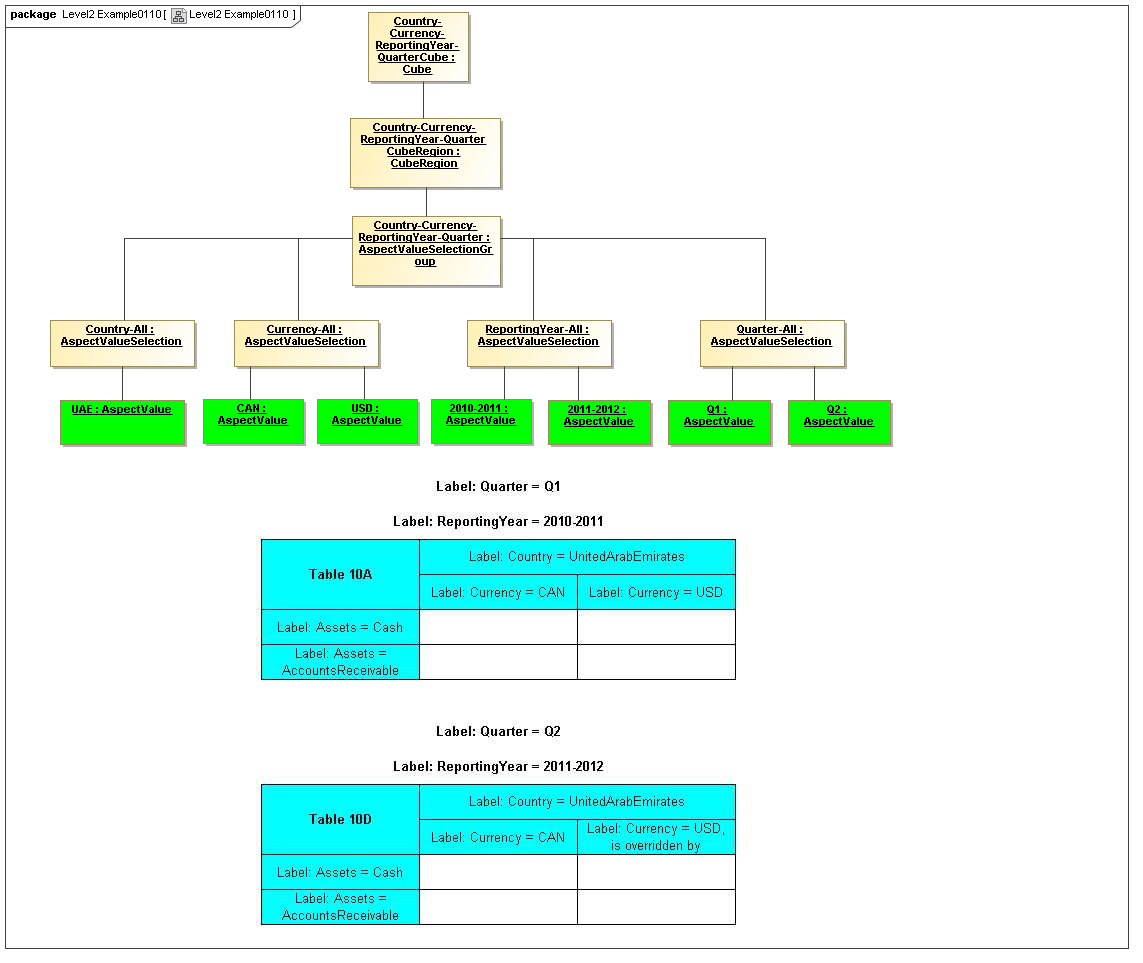
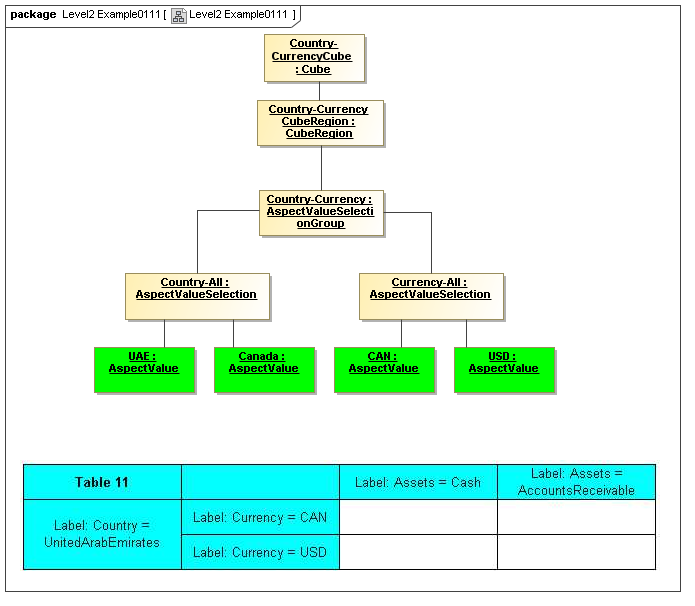
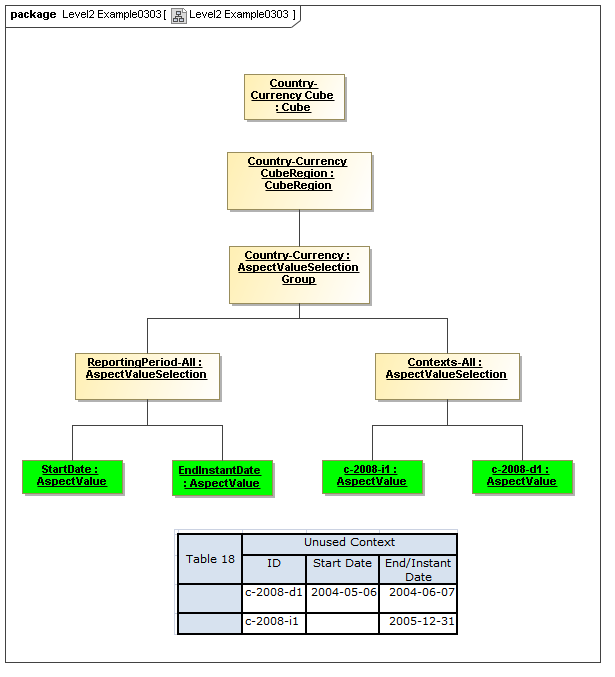
3.4 Valid Combinations Model
Between models of DataPoints and Tables of views of DataPoint Facts, is the model that
specifies which DataPoints are may exist as Facts, based on valid combinations of their
Aspects' AspectValues. From the term hypercube, representing dimensional aspects
of a DataPoint, the sections of value-space in the hypercube that may validly represent facts
is defined as a "Cube Region" (OMG CWM OLAP).
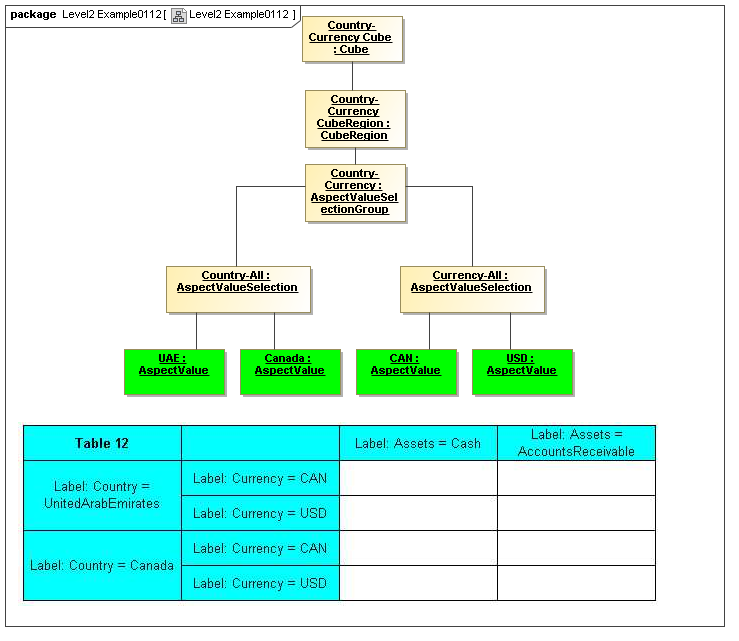
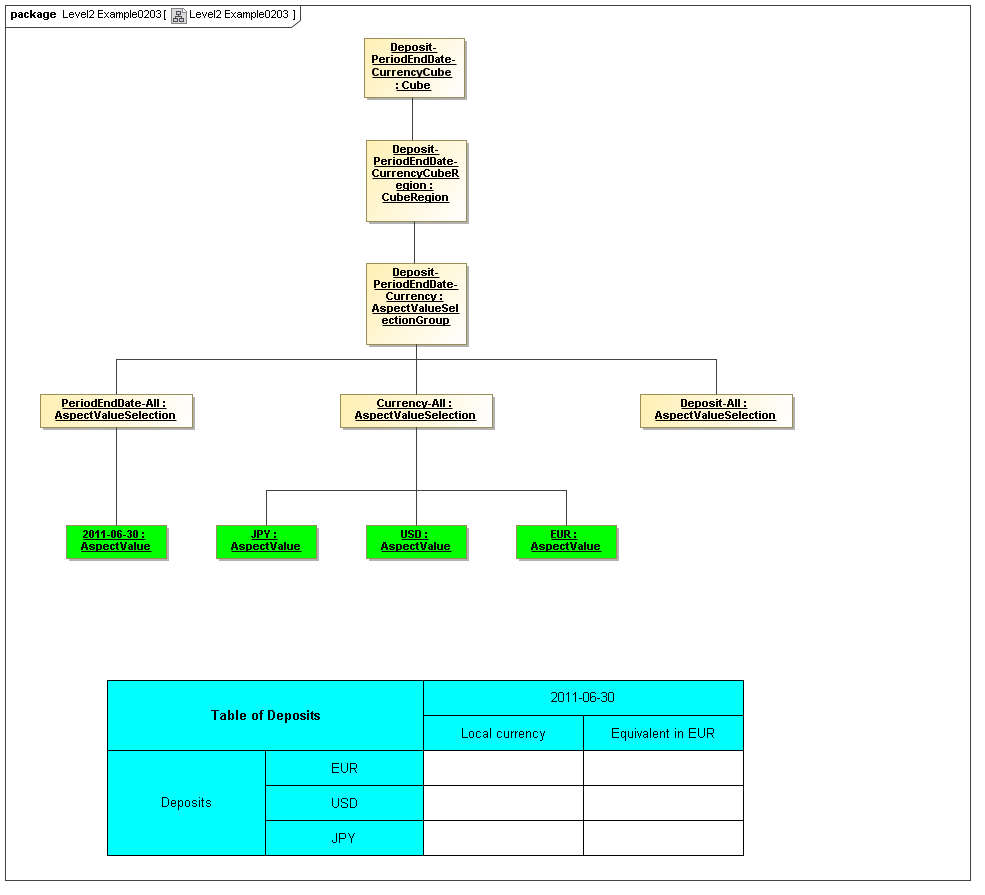
This model captures how groupings of Aspect AspectValues form Cubes and CubeRegions of allowed (or by subtraction, disallowed) AspectValues. When instantiated, valid combinations models hypercubes of XBRL Dimensions as well as equivalent realizations possible with OLAP technologies
This model is based on CWM OLAP, representing instances of AspectValues (not declarators of sets of AspectValues in the secondary model). This is where one can model XBRL's syntax to express hypercubes (that are aspect value selections specifying cube regions), whether they are declared by positive and negative hypercubes, OLAP, or any other kind technology.
[Herm Fischer: In this layer it has been difficult to get specific API of implementing OLAP products with both sparse and vast cubes (ROLAP vs MOLAP) and combinatorial (cross product) aspect selection groups. The OLAP product implementations seem to have neither API nor features for cross-dimensions-product area specification. They appear to implement single-dimension CubeRegion specifications only, as in the example of the CWM Developers Guide. A call with Christian Bremeau and his co-workers appears to confirm this issue. A way to think of it is that MOLAP is more like XBRL hypercube implementations, in that we're never going to completely enumerate the dimensional cartesian-product space (as ROLAP might), and as a MOLAP is implemented by dynamic queries, an XBRL engine is likely to implement XBRL dimensions by "assisted" dynamic DRS traversal at runtime (at least that's what Arelle does) instead of attempt to completely populate in advance the cube combinations (which might need Avigadro's number of RAM chips). ]
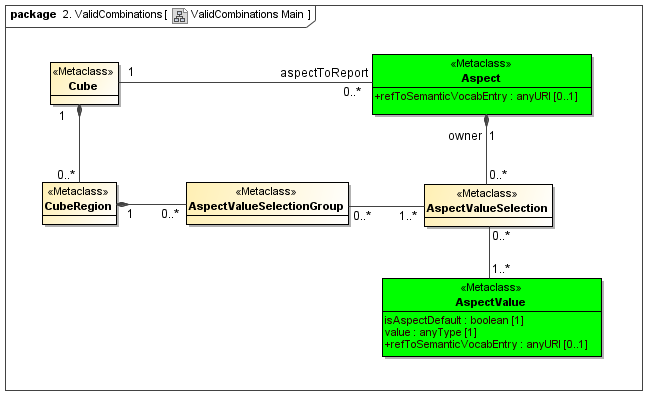
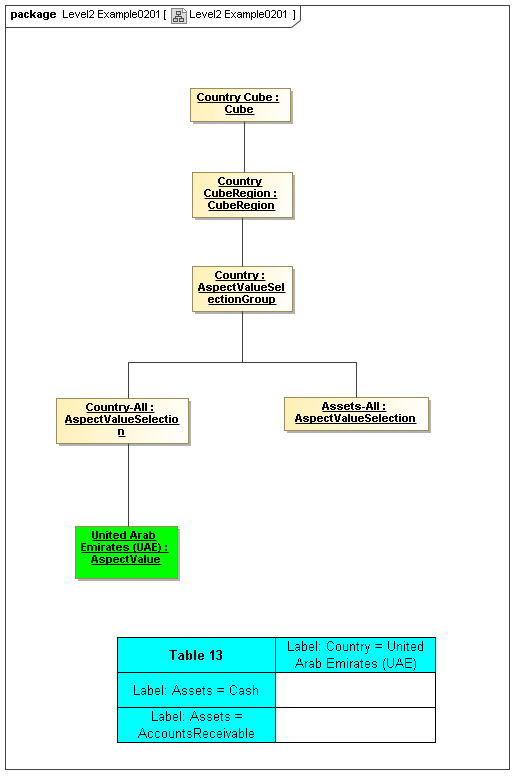
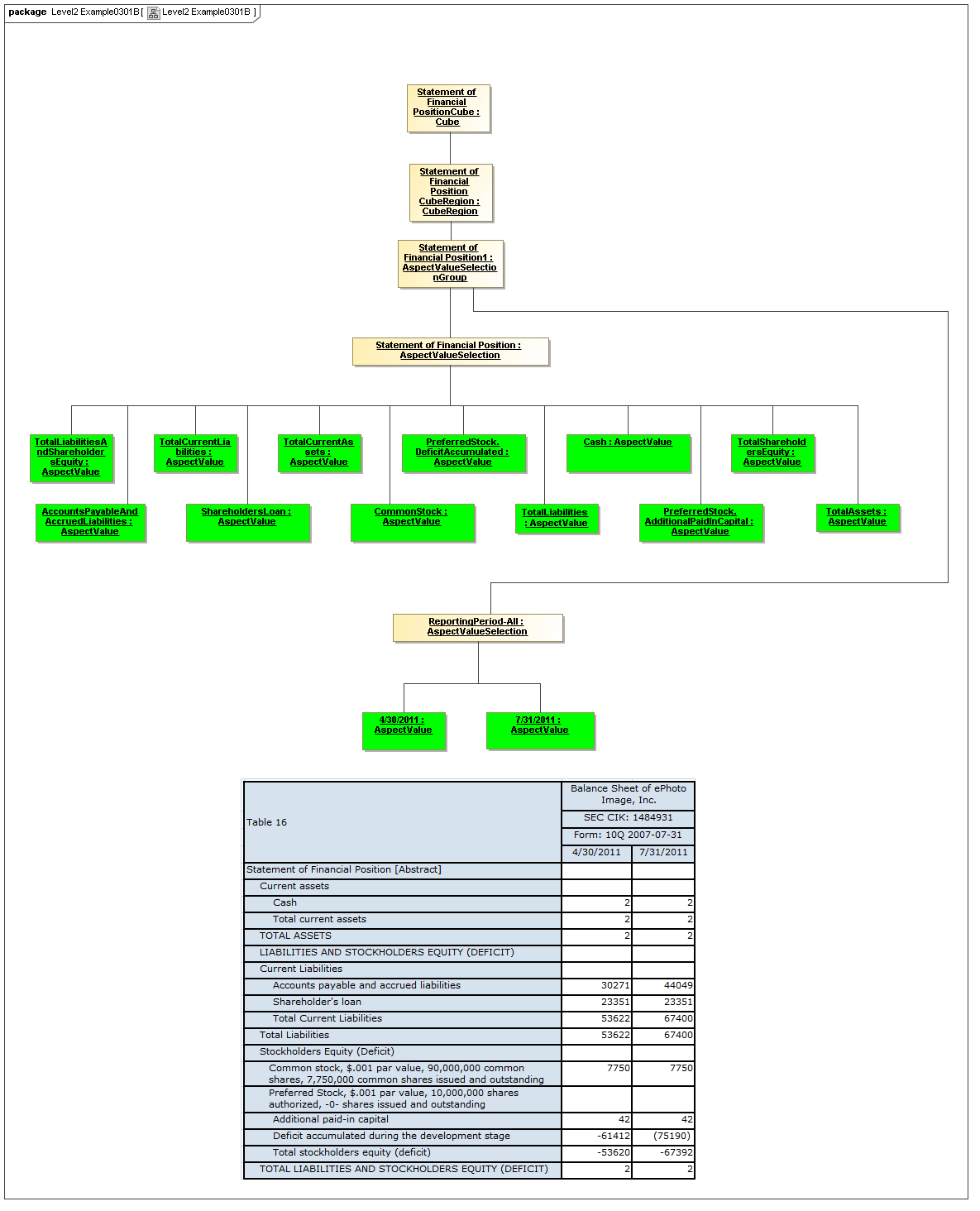
3.4.1 Cube
Cube
The Cube metaclass defines a collection of CubeRegions that are associated with specified aspects to report.
The Primary Model Cube meta class associates models of instance values with aspects to report (e.g., aspects that form the typed value of data points). The secondary model lower level classes may associate cubes with concrete syntax such as XBRL hypercubes, that associate dimensions to reportable base items (concept primary items).
Rationale
Reportable aspects (base items) are associated with reportable sets of AspectValueSets (cube regions).
Properties
A Cube is expressed by CubeRegions and AspectsToReport.
3.4.2 CubeRegion
CubeRegion
The CubeRegion metaclass defines a cartesian product, for a set of Aspects, of enumerable AspectValues (corresponding to XBRL hypercubes after subtraction of negative hypercubes from positive hypercubes).
The Primary Model CubeRegion meta class is a model of instance values. The secondary model lower level classes may use declarative techniques to specify CubeRegions compactly. Large dimensions of many members may have large cartesian product-spaces of the dimensions, which may be represented algebraically or by means other than by complete specification of all enumerable AspectValue combinations in the cartesian-product of AspectValues of each Aspect. The CubeRegion may thus be a PrimaryModel contrivance implemented in the Secondary Model by more efficient means (such as XBRL positive hypercubes subtracting XBRL negative hypercubes).
Rationale
AspectValueSets have specific sets of allowed values, by ontological modelling of specific aspects, legislative and prudential control of reportable values, etc. The set of potential values must be determinable when modelling AxisOrdinates that can correspond to DataPoint instance facts or are not allowed to have Fact instances. This is needed when displaying input forms, based on AxisOrdinate tables, for example.
Properties
A CubeRegion is expressed by AspectValueSelectionGroups.
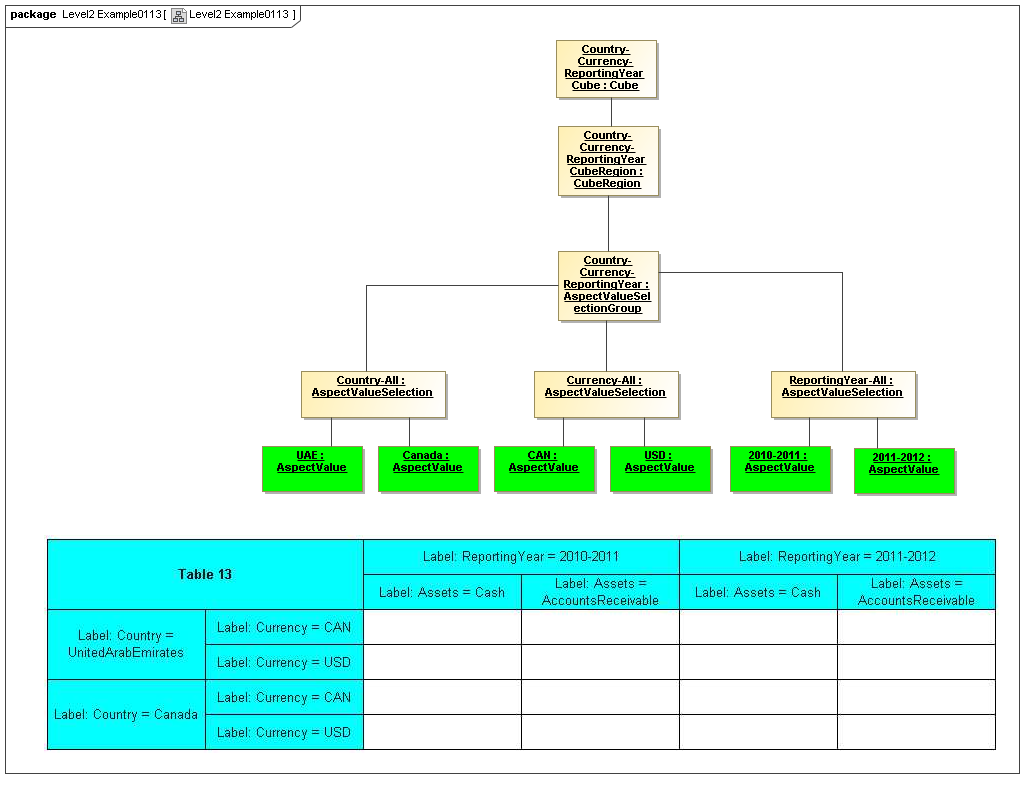
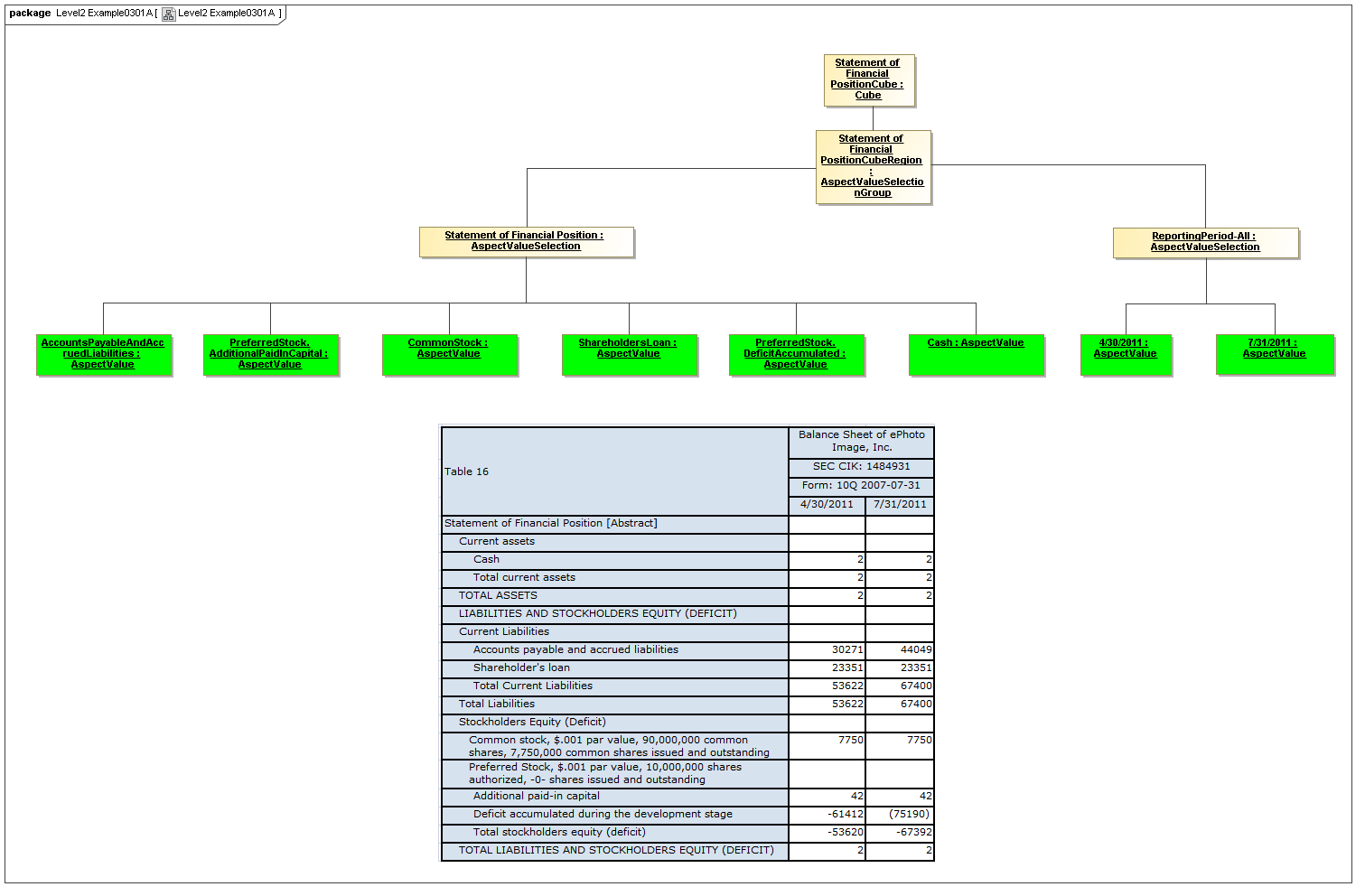
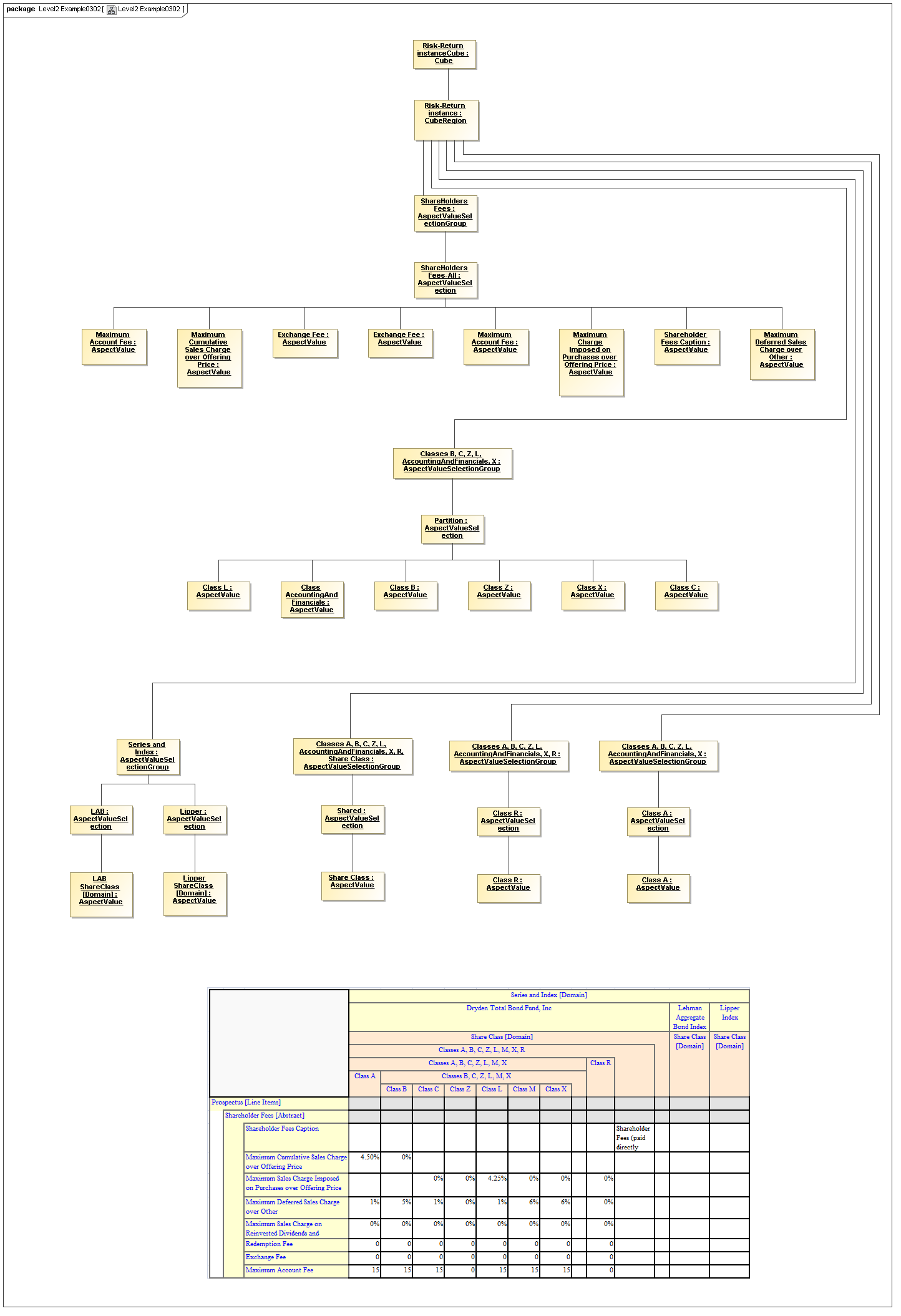
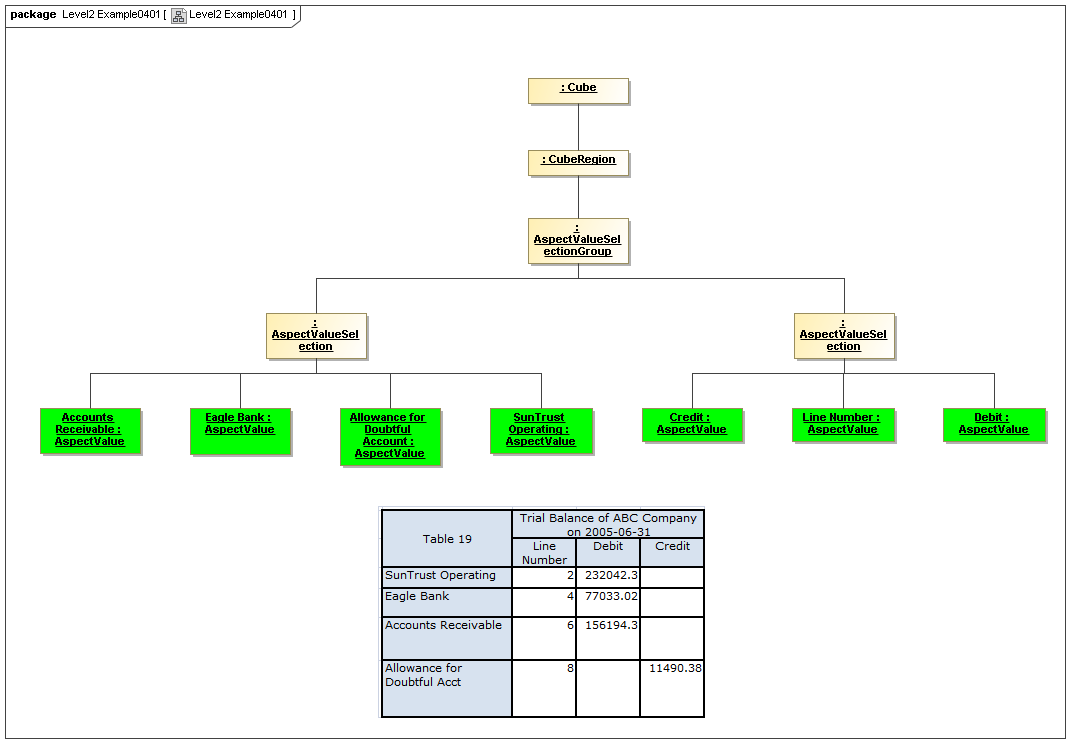
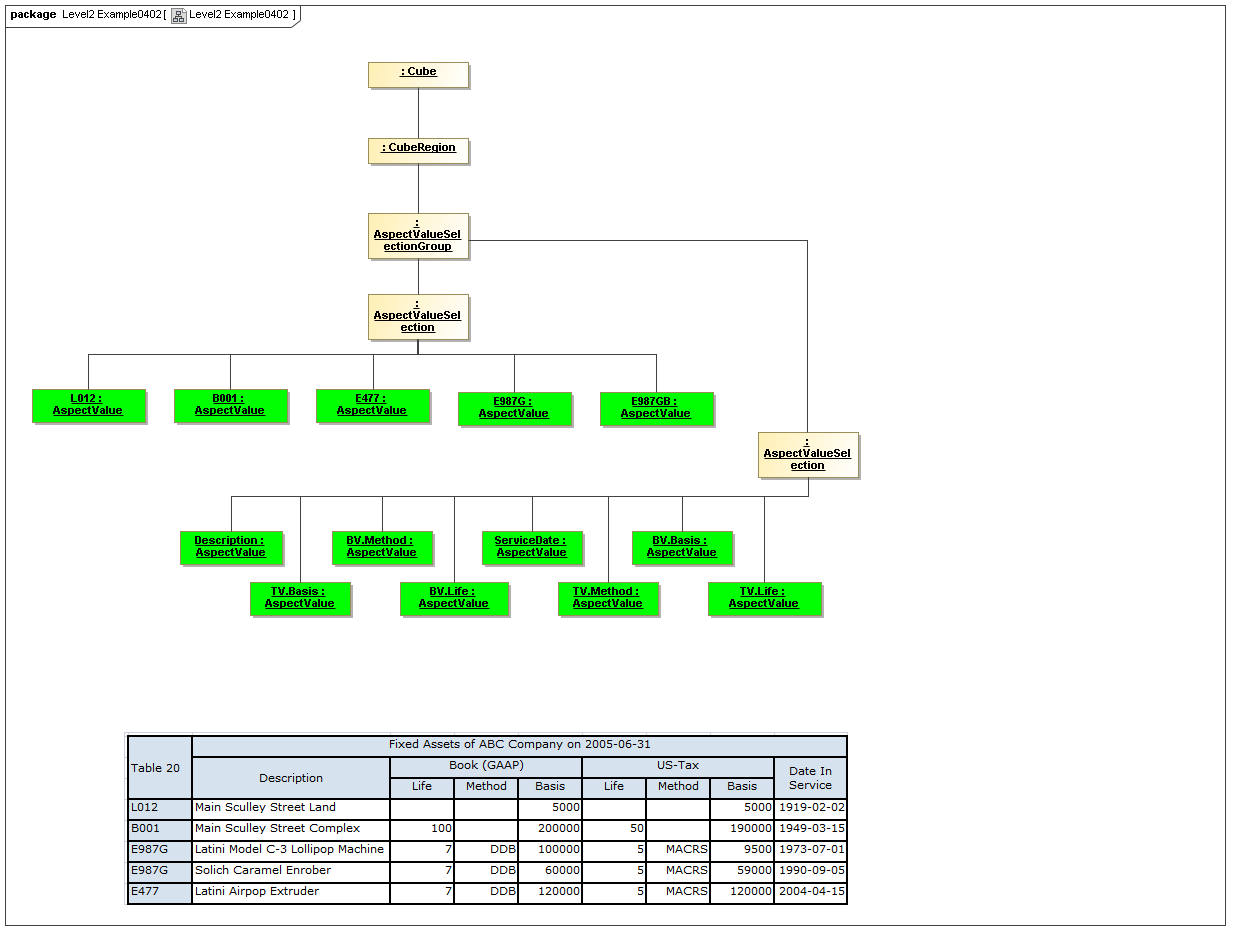
3.4.3 AspectValueSelectionGroup
AspectValueSelectionGroup
The AspectValueSelectionGroup metaclass defines a set of cartesian products of enumerable AspectValues.
Rationale
An AspectValueSelectionGroup is a set of allowed DataPoint AspectValues of facts that may exist in a CubeRegion.
Properties
An AspectValueSelectionGroup has a set of AspectValueSelections.
3.4.4 AspectValueSelection
AspectValueSelection
The AspectValueSelection metaclass defines a set of enumerable AspectValues that identify or describe a single DataPoint (Fact instance) to be allowed in an AspectValueSelectionGroup.
Rationale
An AspectValueSelectionGroup is a set of allowed DataPoint AspectValues for a Fact.
Properties
An AspectValueSelectionGroup has a set of Aspects and their AspectValue(s).
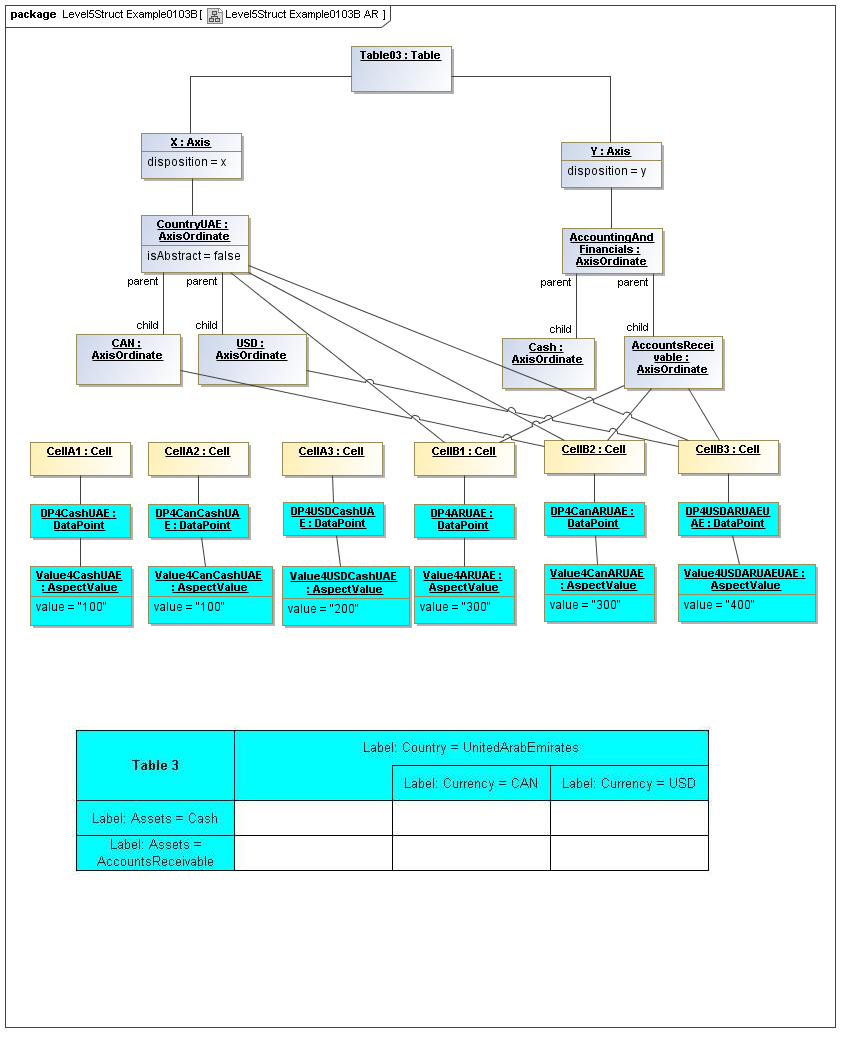
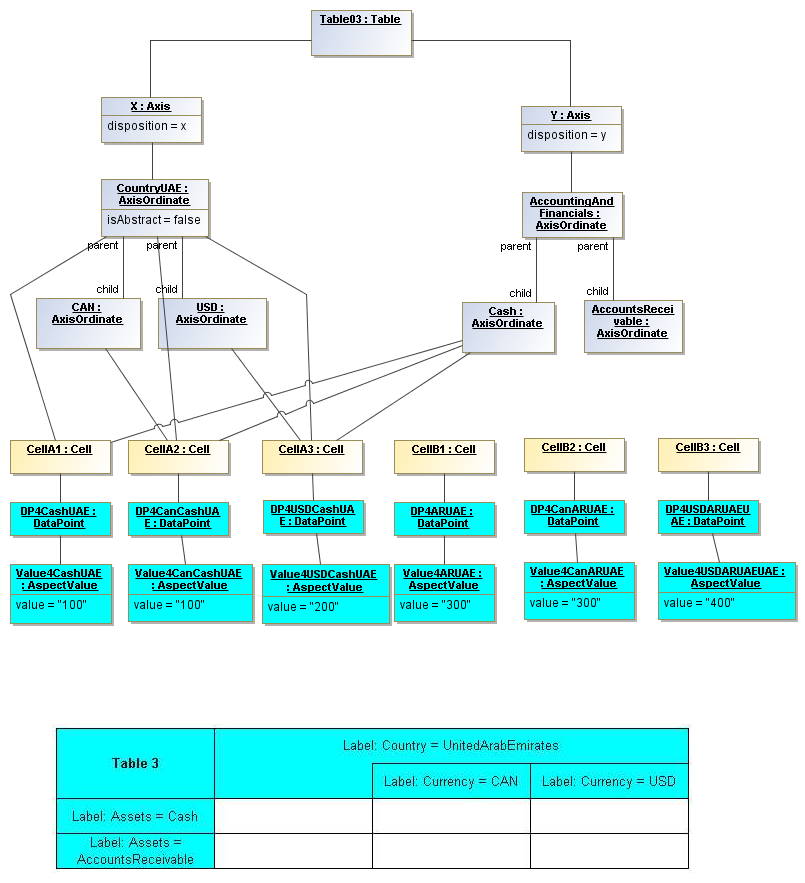
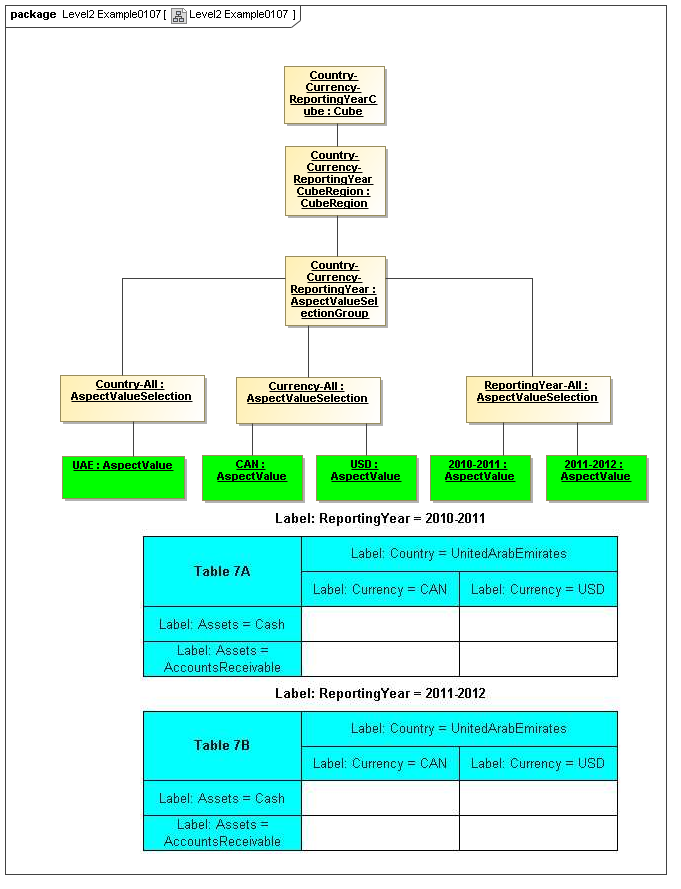
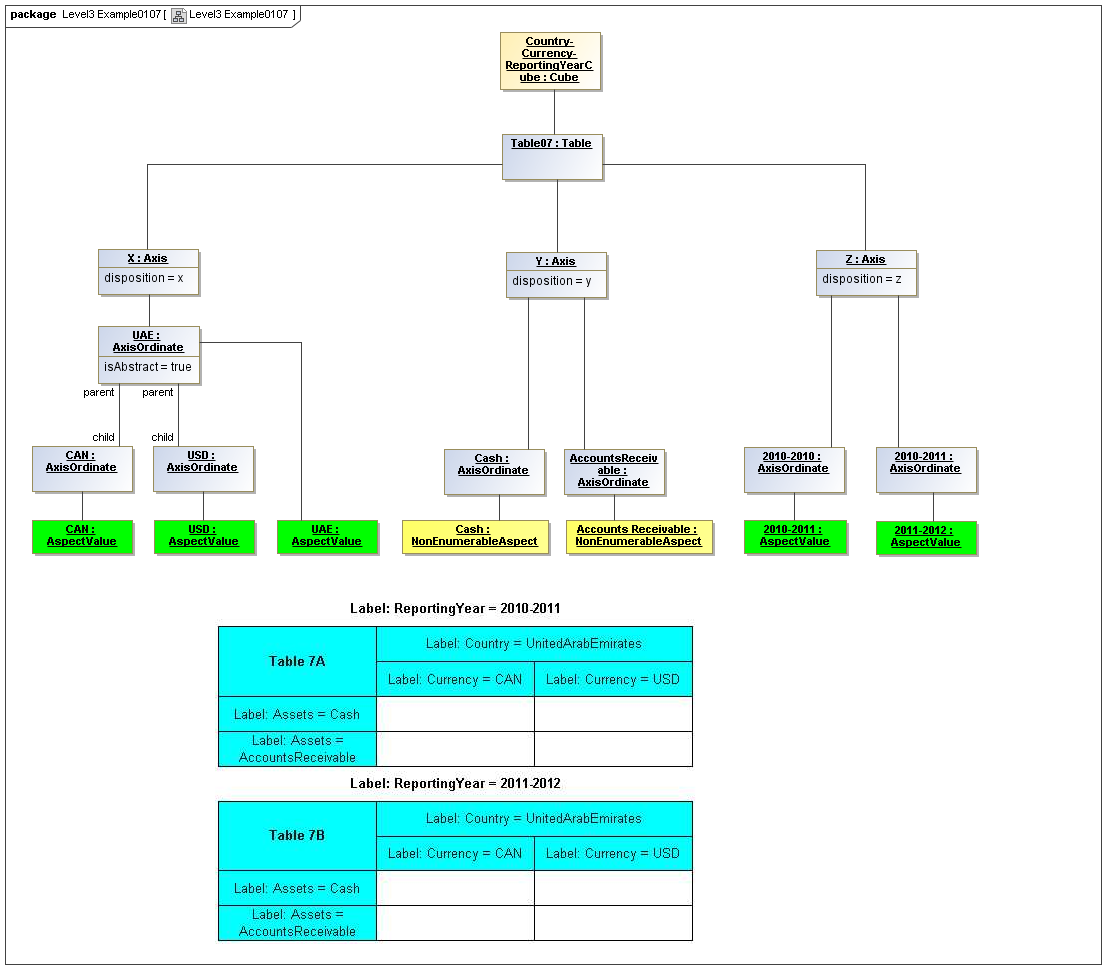
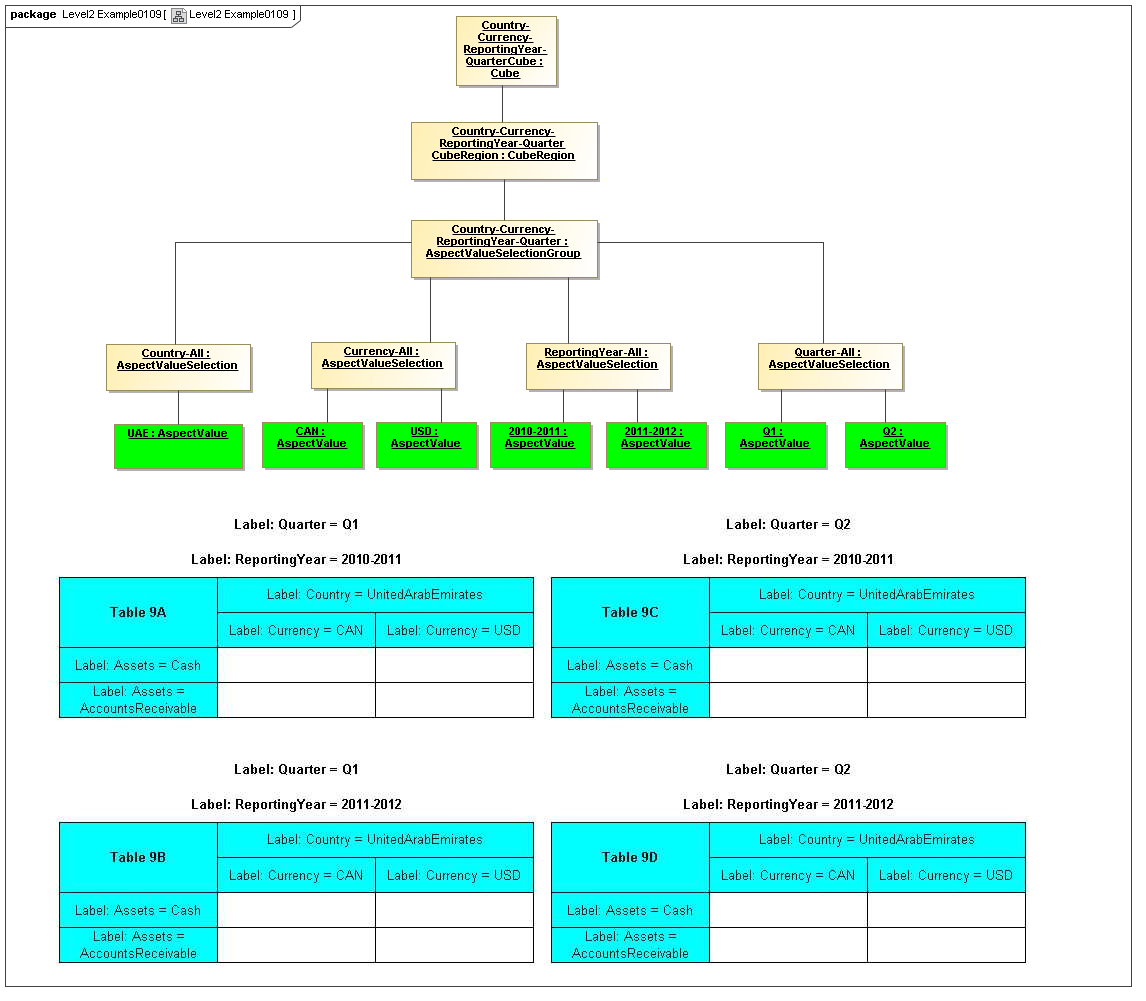
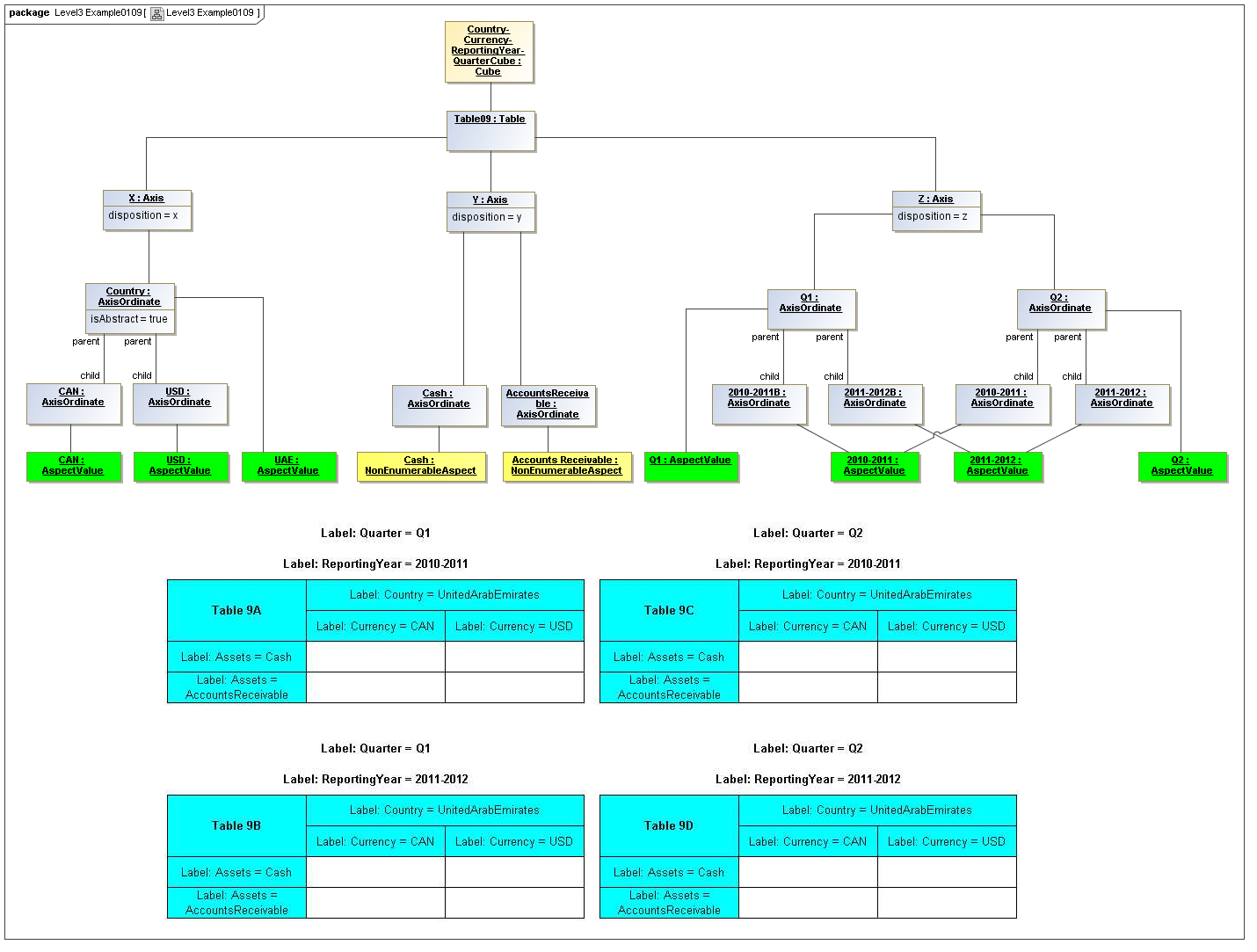
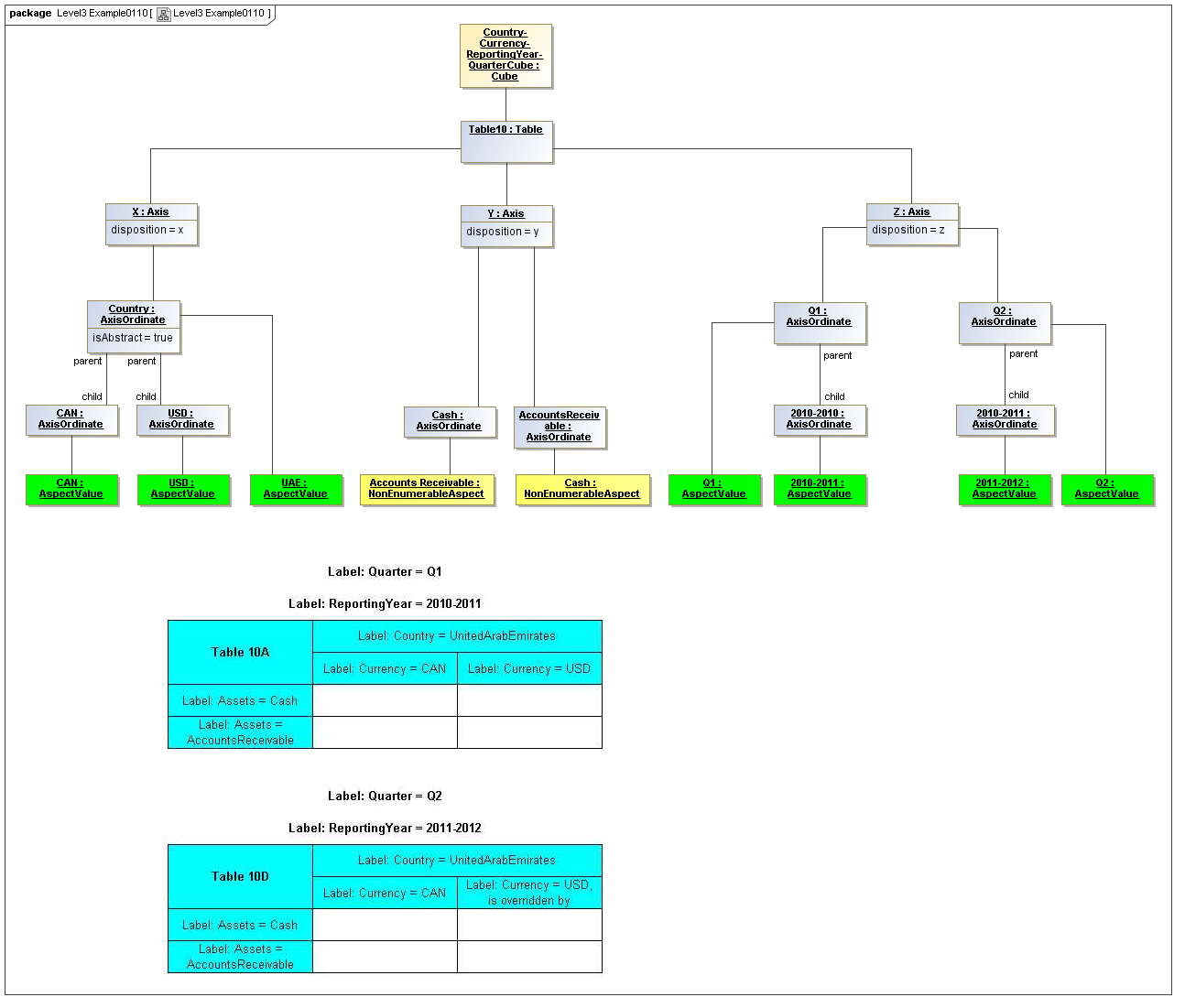
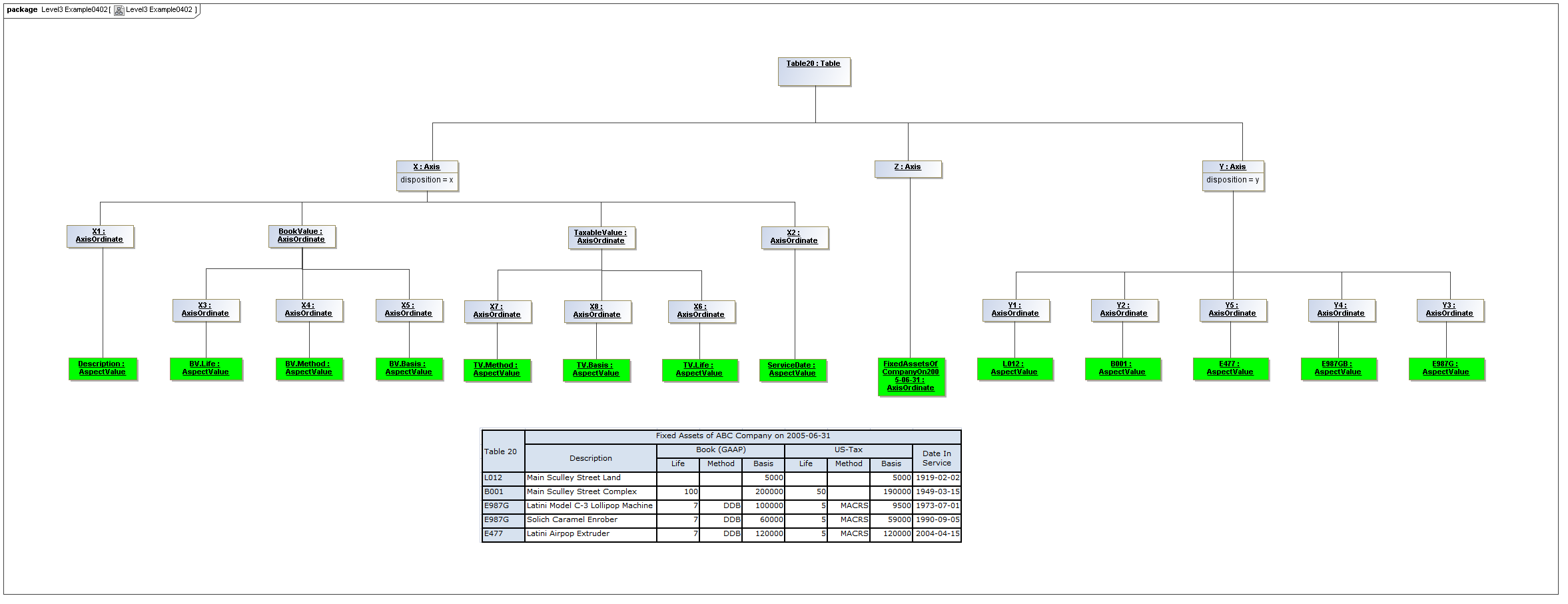
3.5 Table Model
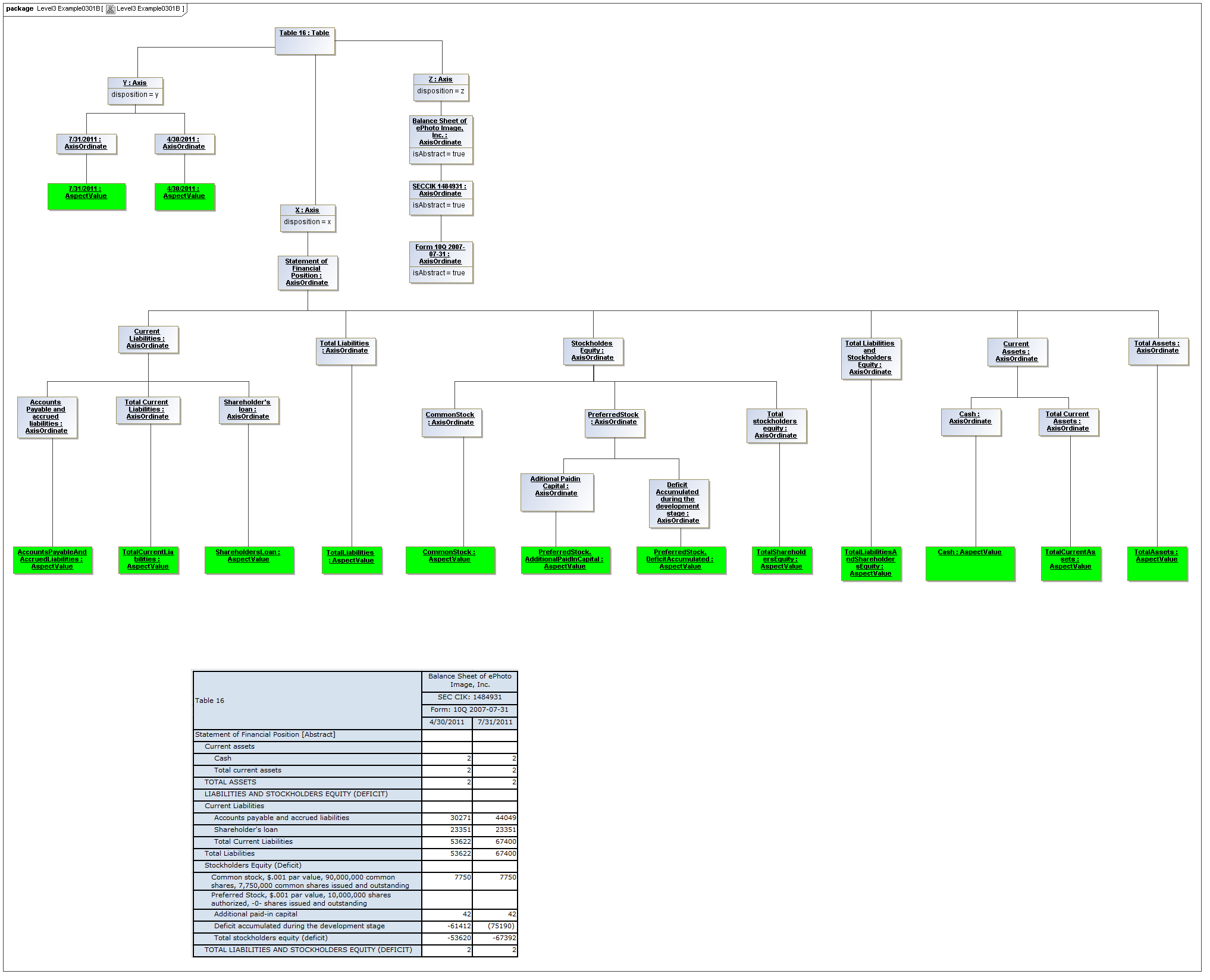
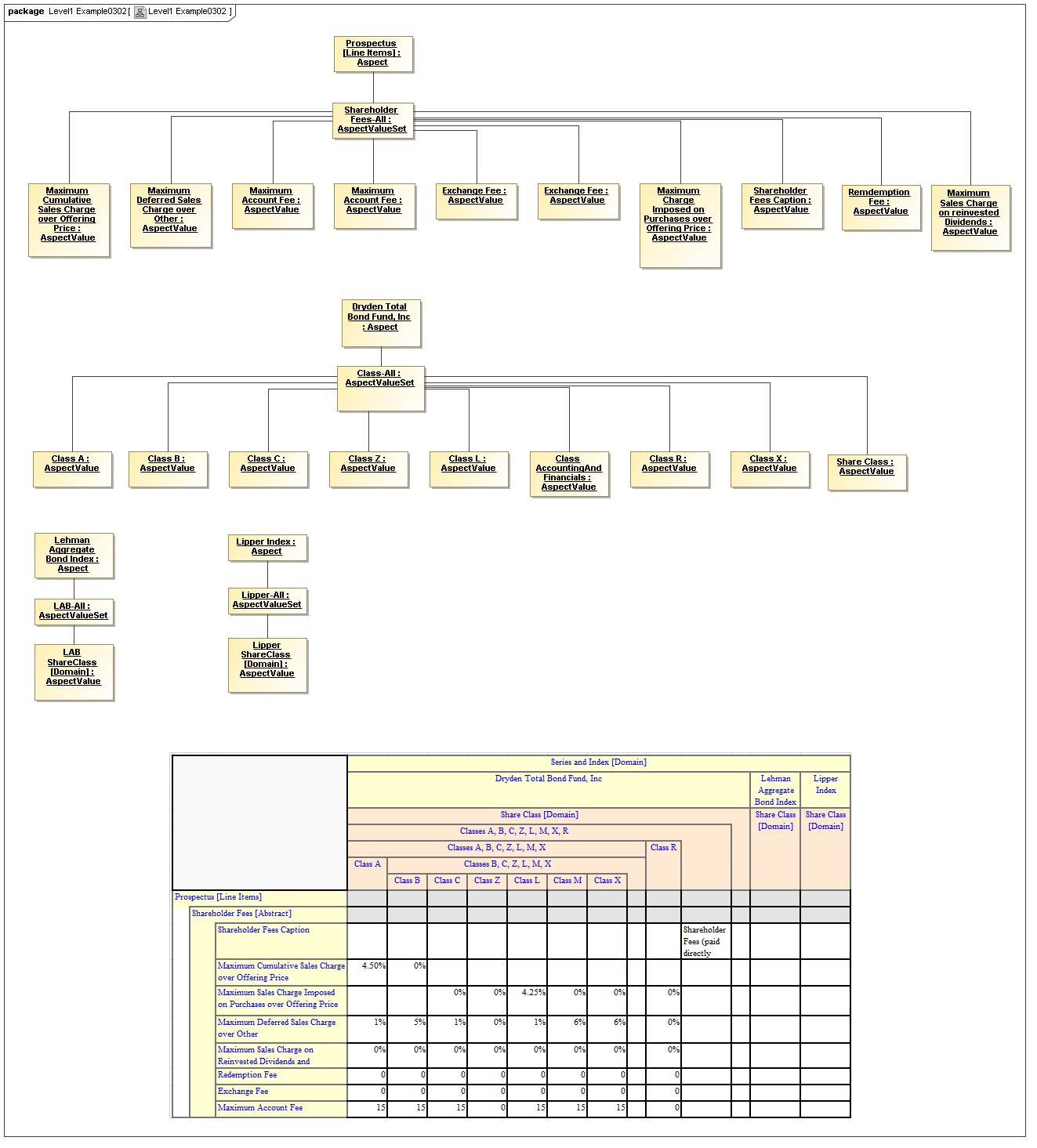
This is a view layer, taken from the Table ideas of Data Points Modeling. The source material is the XII website WGN table linkbase overview, which is a declarator for table linkbases. Here this model instead represents instances of table views, not declarators of table views. For declarators the table linkbase is still relevant (as secondary concrete syntax).
This model captures how tables provide views of valid combinations of data points by relating aspect values to coordinates of viewing axes. It forms a meta-model for various presentation schemes including those of traditional XBRL instance rendering.
[Warwick Foster: At this stage the relationship between the Cube and the Table will restrict the domain of the table to the associated cubes. If it is omitted the cube validity of the reported data is still achieved through the Aspects in the table.]
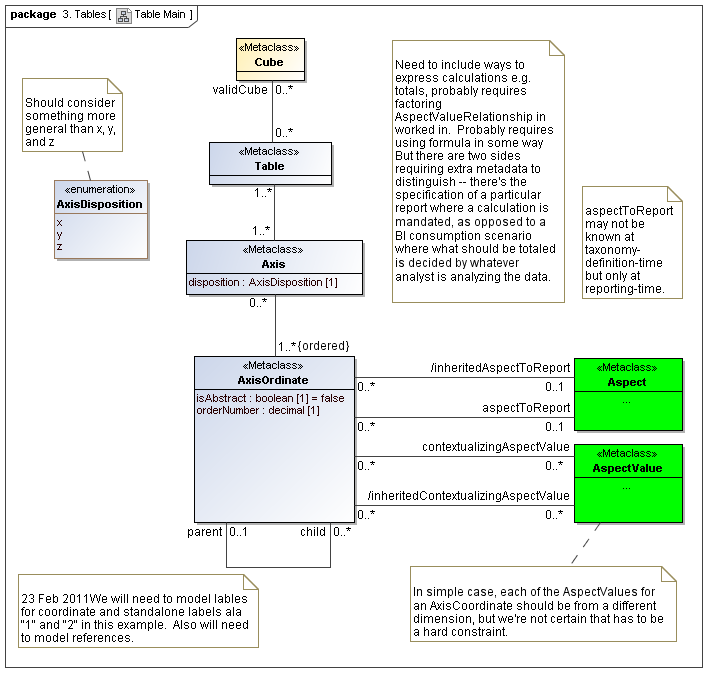
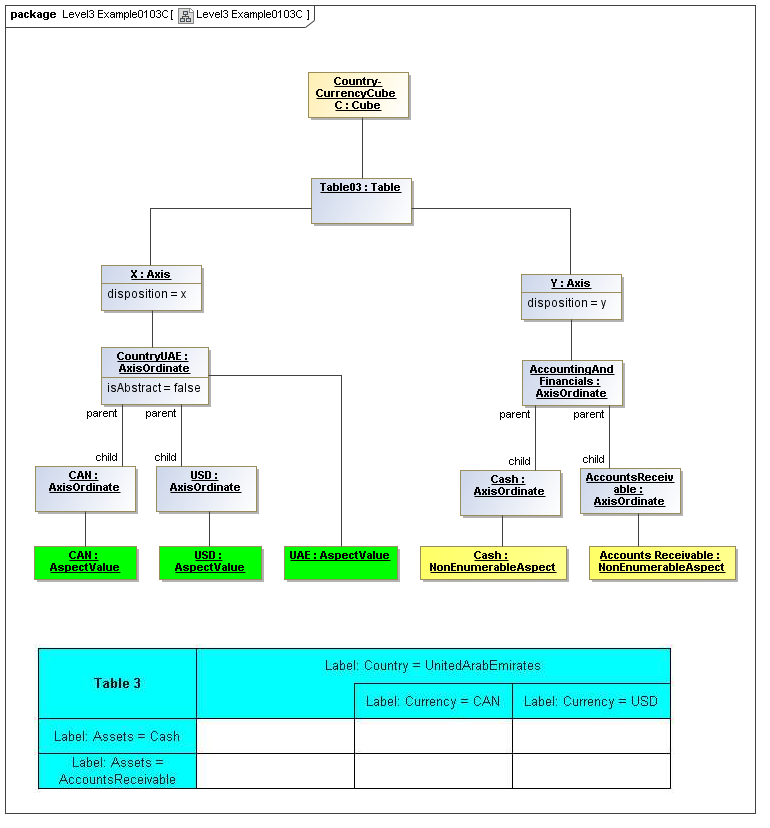
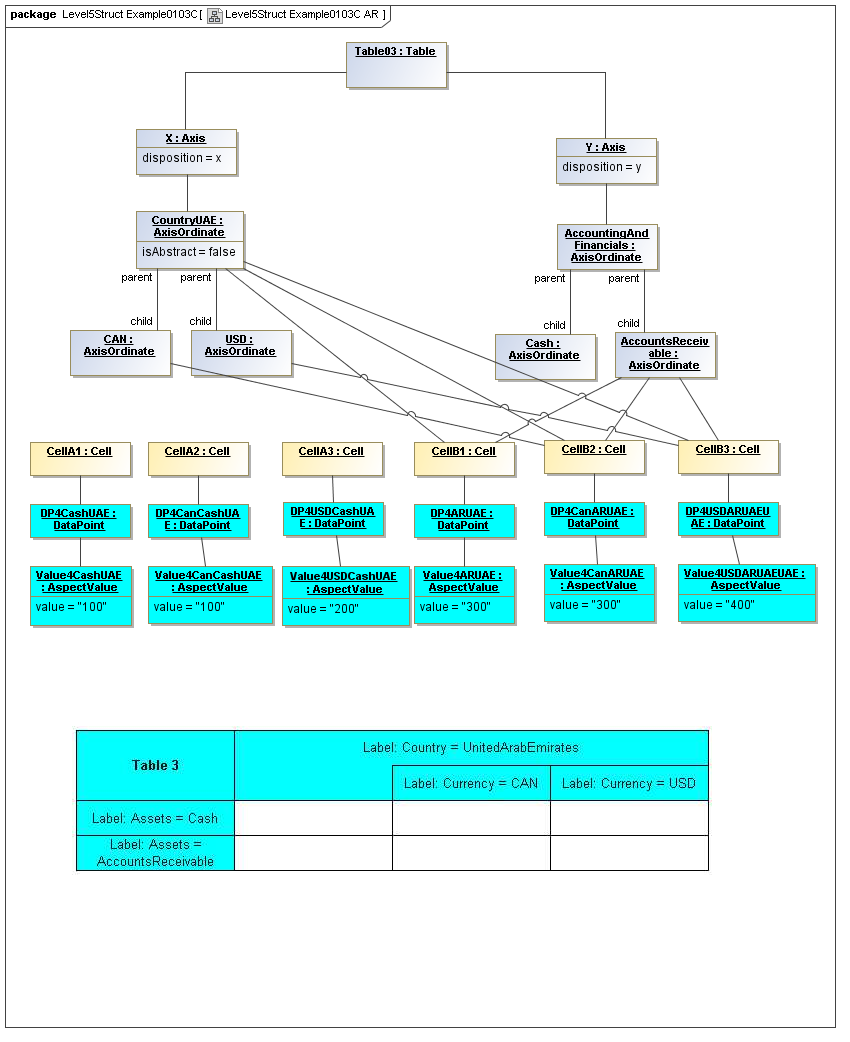
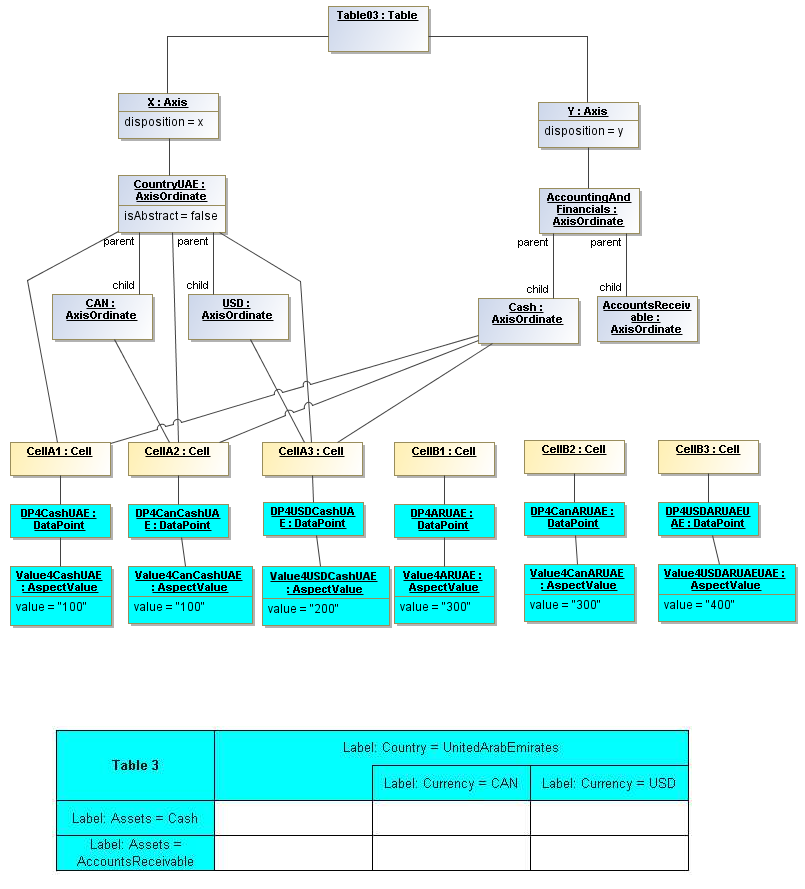
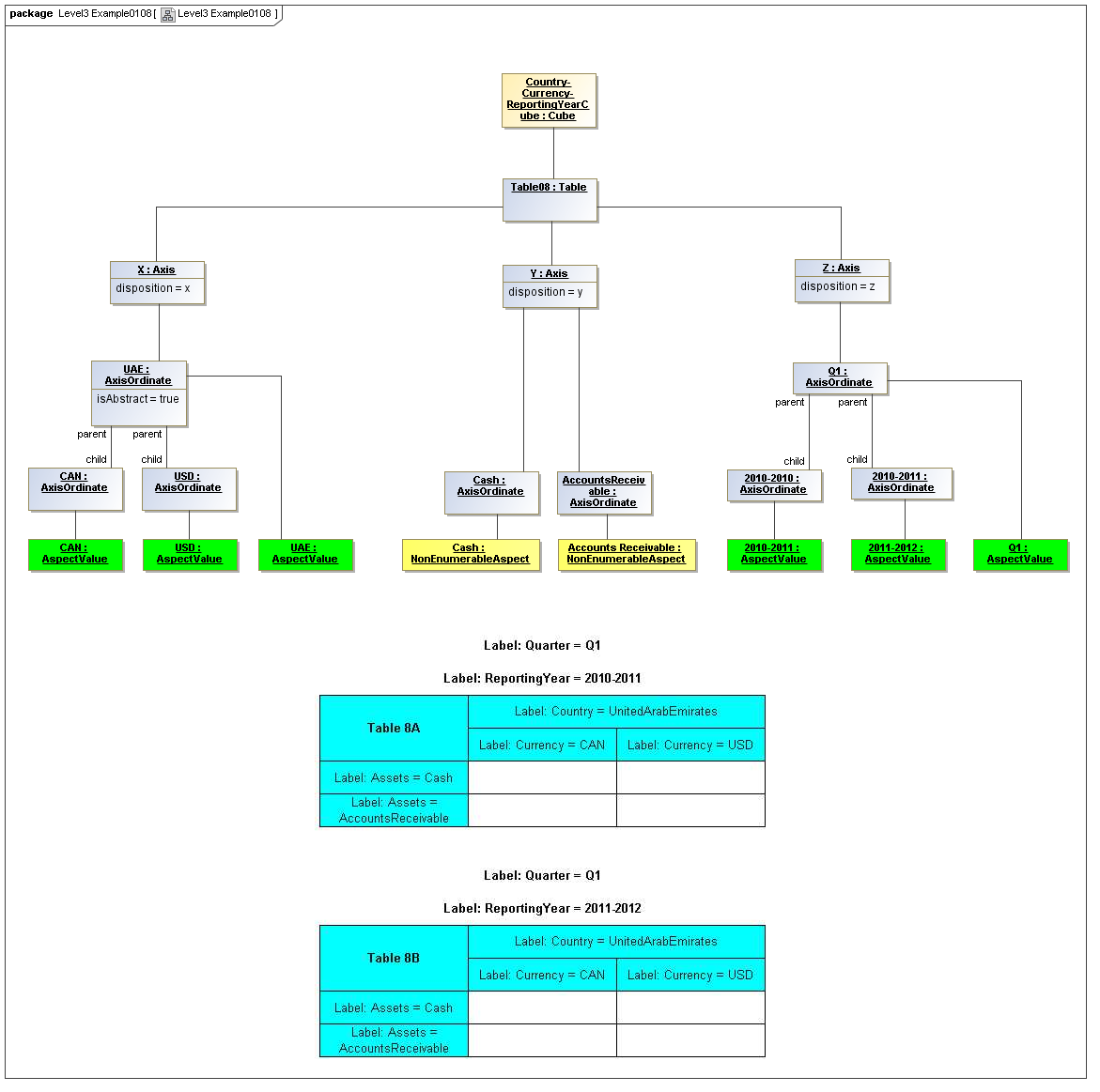
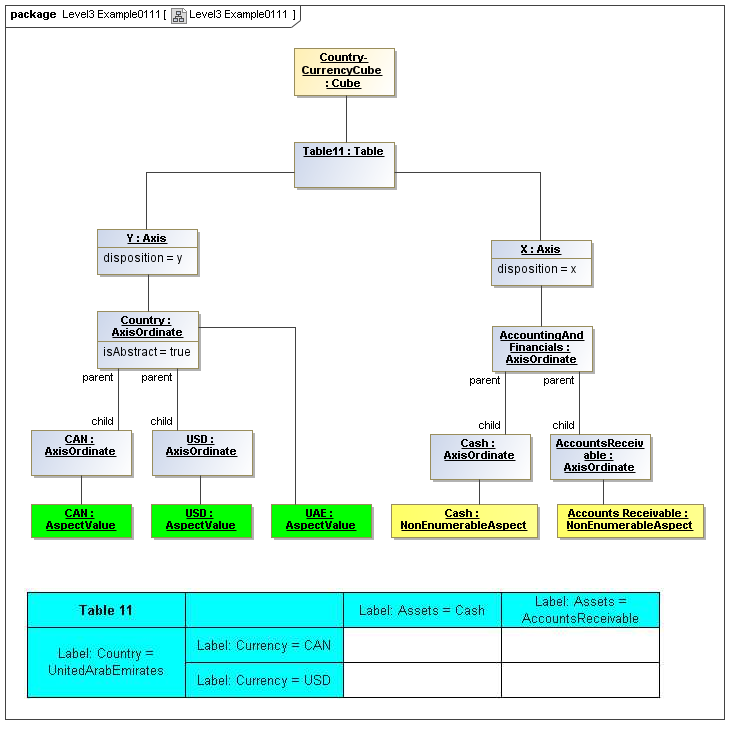
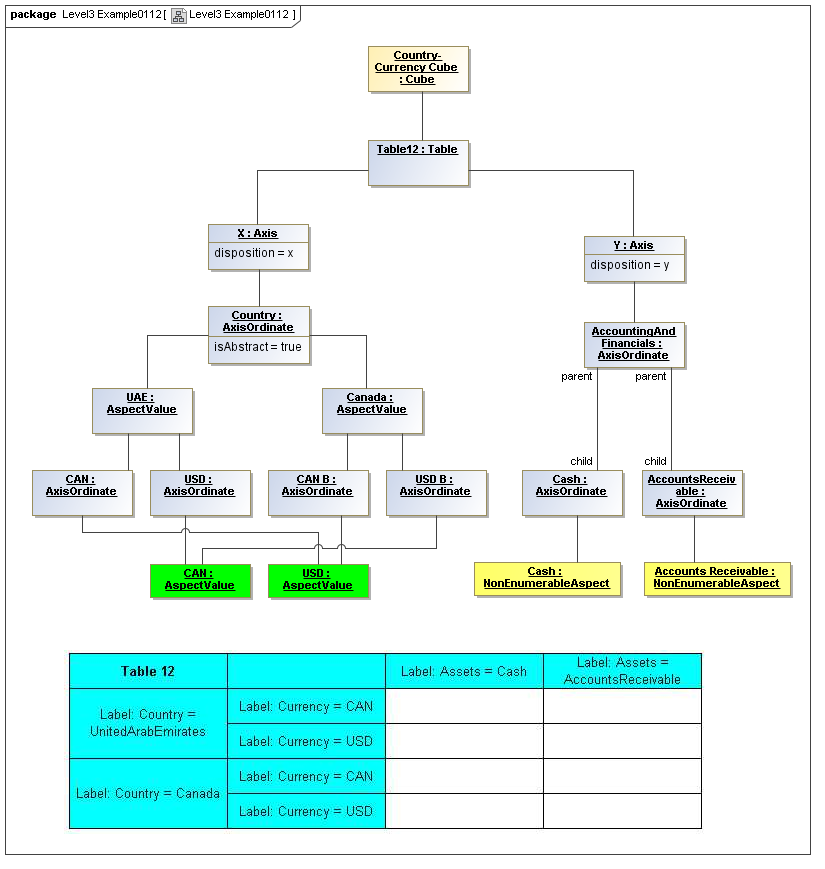
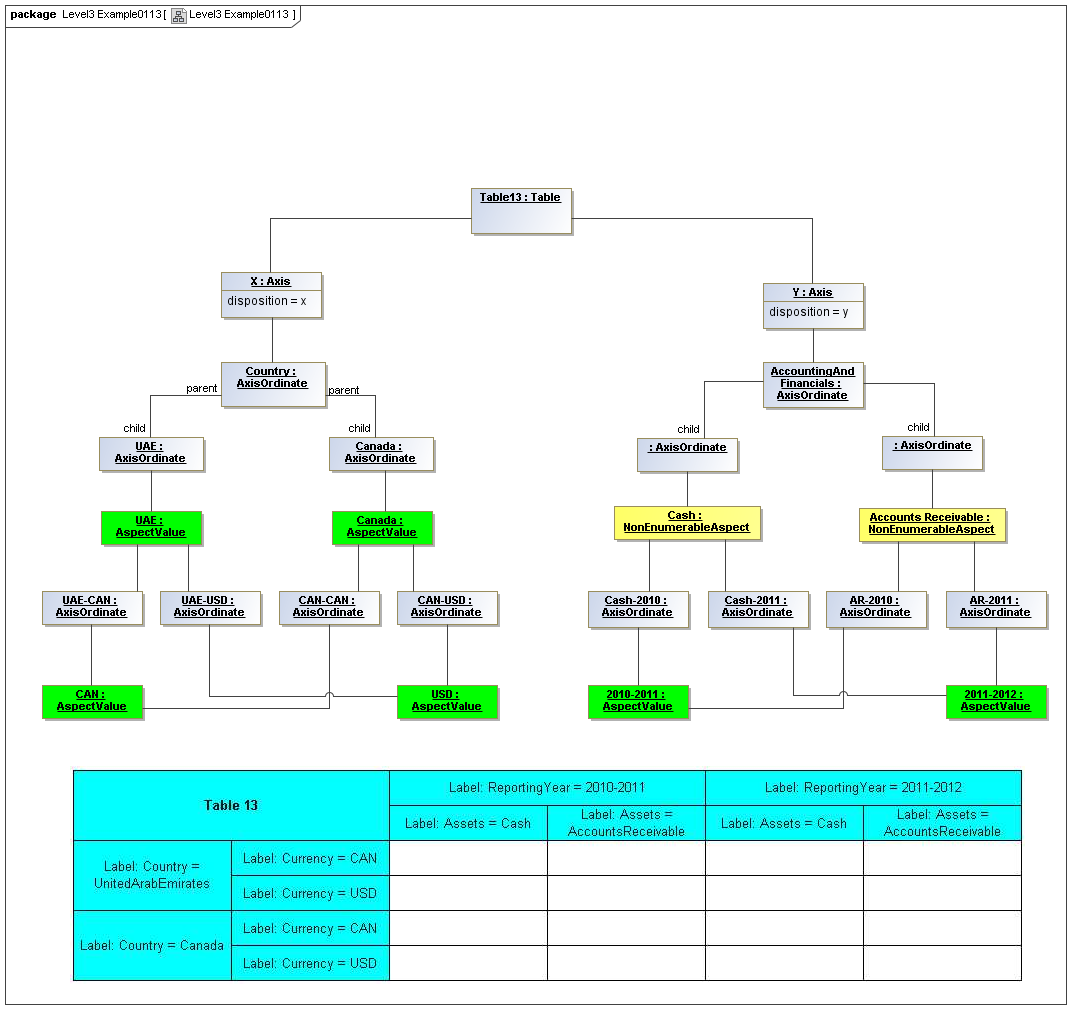
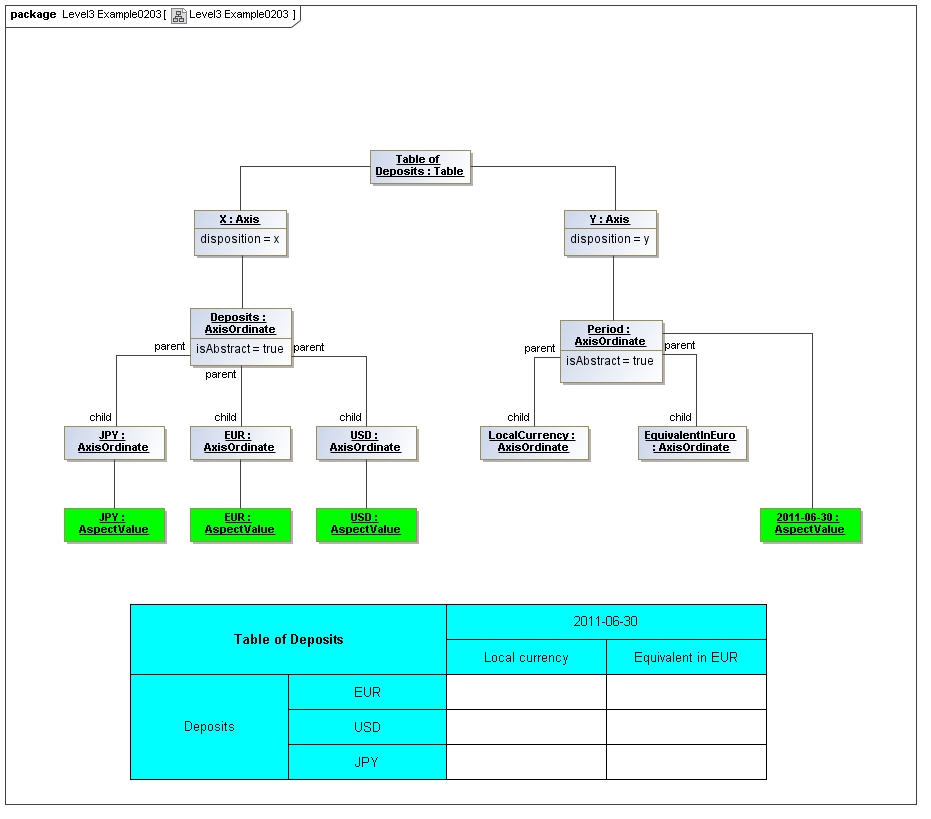
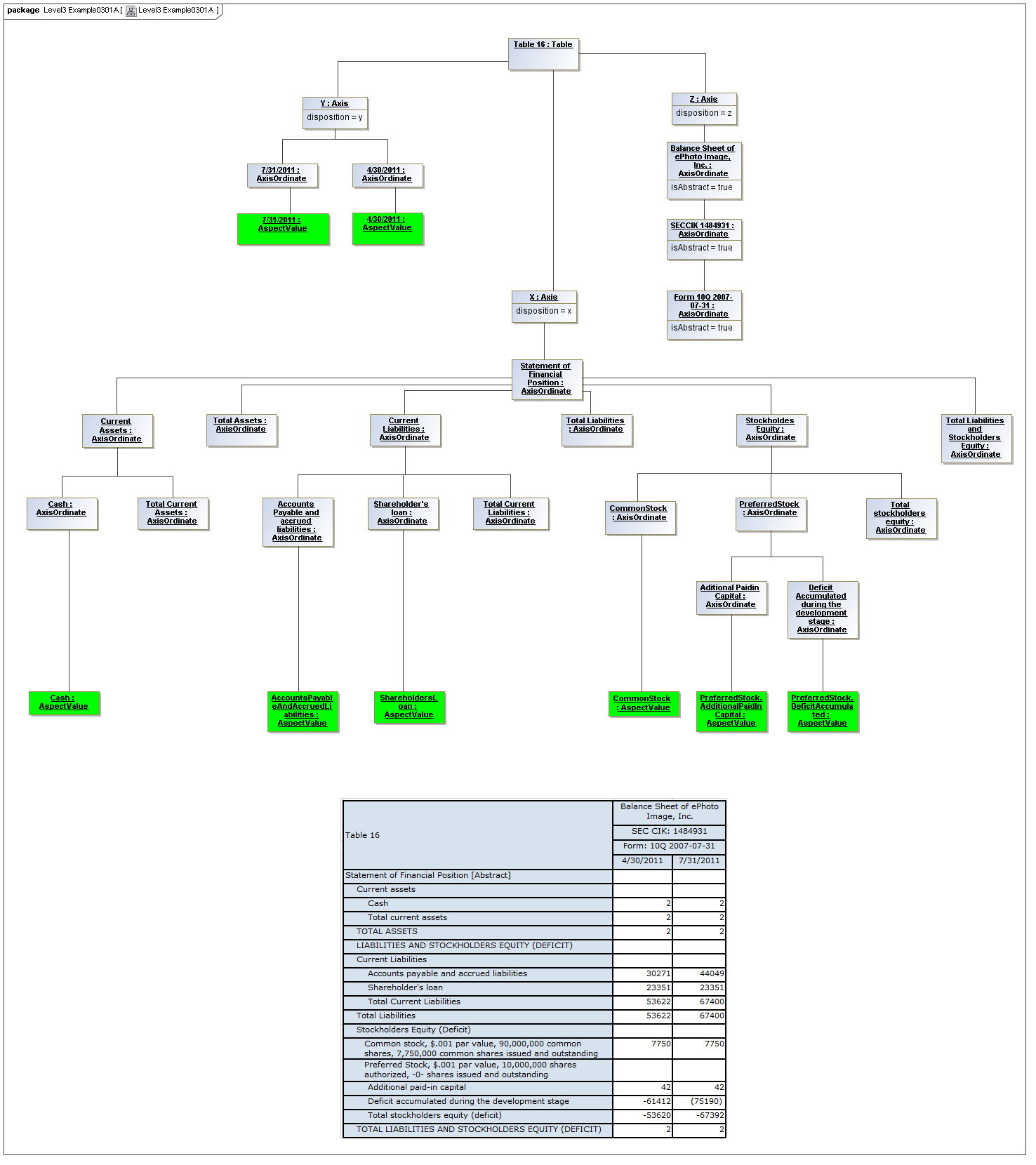
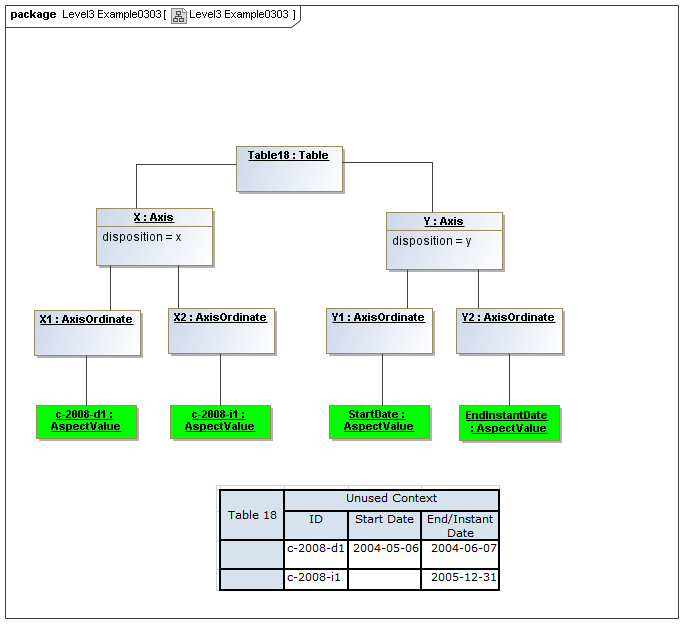
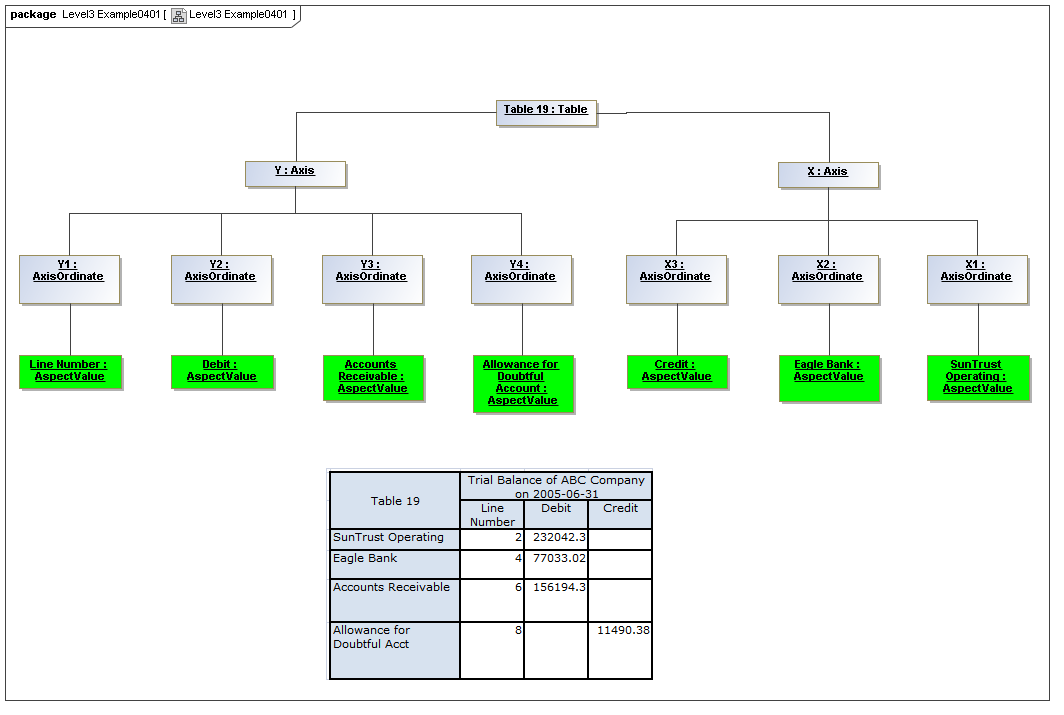
3.5.1 Table
Table
The Table metaclass defines a view of selected Facts in a matrix layout in a Cartesian Space of a determined number of Axes. Ordinates of each Axis specify by AspectValue which Fact may, by the intersection of coordinates, appear in each cell of the matrix. CubeRegions further specify which of such AspectValue combinations may have realized Facts.
Rationale
Tabular presentation of business reports information items, in matrix layouts, is generally required.
Properties
A set of Axes defines, by the AxisOrdinates of each Axis, sufficient AspectValue specificity, so that for each combination of axis coordinate, an ImpliedDataPoint can be realized, or the matrix cell can be recognized as being excluded from the CubeRegion (disallowed).
A set of CubeRegions may be associated with a Table (such as to specify the kind of accounting schedule to appear in the table).
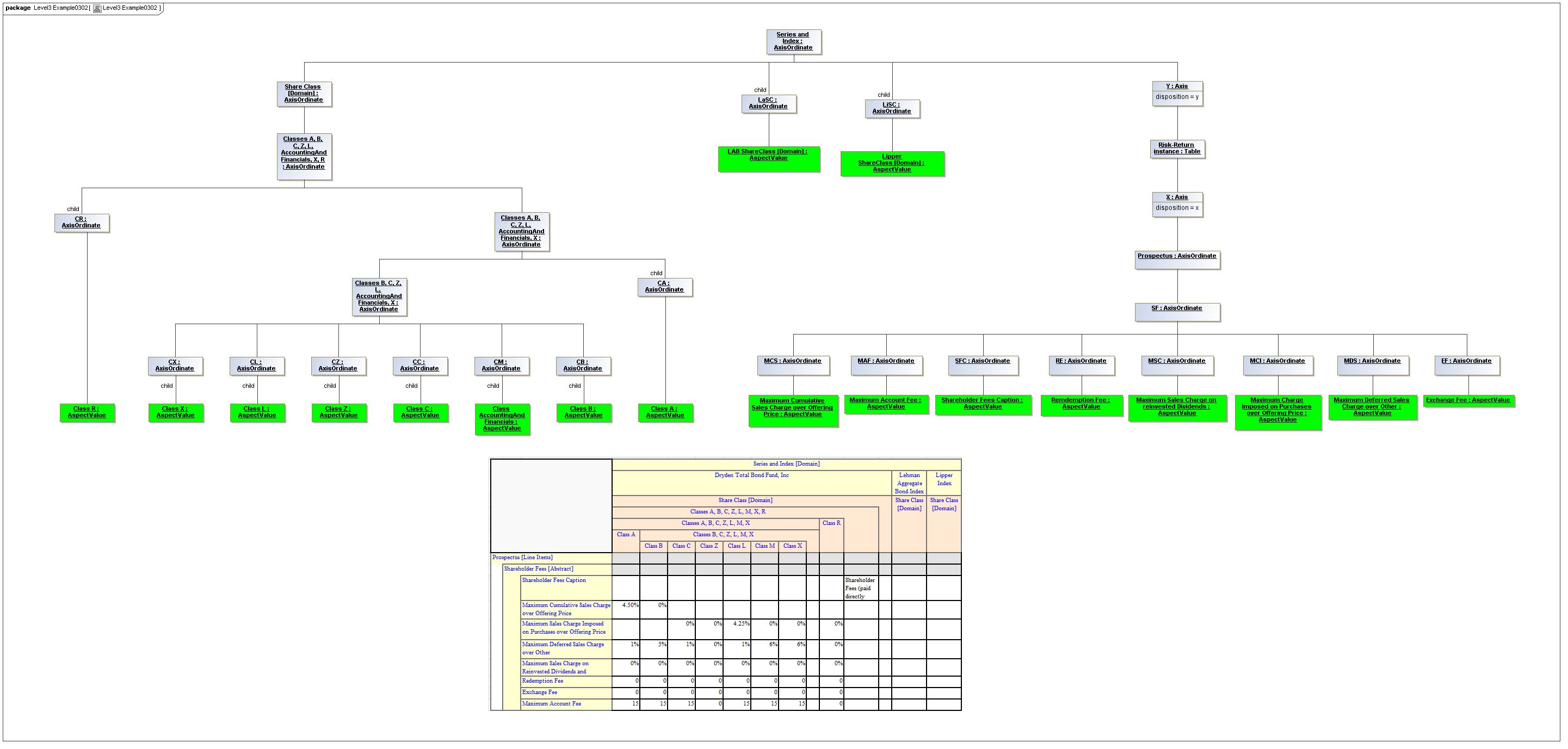
3.5.2 Axis
Axis
The Axis metaclass (plural: axes) defines a set of combinations of the AspectValues of a subset of the Aspects of viewable DataPoint Facts, and a certain arrangement of them along an imaginary line.
Rationale
Specification of a Table by the coordinates along each Axis may be more compact than specifying each cell in the matrix represented by the table (e.g., for a table of three columns and ten rows, thirty cells may be defined by thirteen coordinates, three by column and ten by row, instead of thirty by cell).
Properties
The axisDisposition specifies the display orientation of its coordinates. Typical two dimensional tables have three axis dispositions: x-axis, y-axis, and z-axis. The x-axis represents a horizontal arrangement of columns in a table, the y-axis represents a fourth-quadrant vertical progression of rows (except for right-to-left language cultures, where it is third-quadrant), and the z-axis represents an orthogonal axis of choices constraining the two-dimensional view. The x-axis horizontal column progression may be left-to-right, or right-to-left for tables in right-to-left language cultures (e.g. Arabic and Hebrew, to correspond to spreadsheet behaviour). The y-axis vertical column progression is always top to bottom. The z-axis may have multiple values, which can be used either for selection of display (such as by combo-boxes on a GUI) or for multiple tables (such as selected by tab, or output as successive document components).
Each axis has an ordered specification of AxisOrdinates that define tabular display along an imaginary line following a certain order. The position of a coordinate in a graphical representation of an axis is a monotonic sequence expressing where each coordinate from the axis lies in the ordered representation.
Axis headers, if provided, label the axes to communicate heading information about the cells at the intersection of rows and columns. Header information for a column is displayed at the top of a column. Header information for a row is displayed at the left of a row except for right-to-left tables, where it is displayed on the right of the row. The location to display z-axis and table headers is not constrained by this specification, but would usually be at the top of the table. Axis headers for axis dispositions that have multiple coordinate aspect values may use row and/or column spanning to graphically provide clarity of aspect coverage. Axis header information may be simplified when tables are rendered on media not meant primarily for human readability (such as CSV files, which lack a way to span or merge column headers).
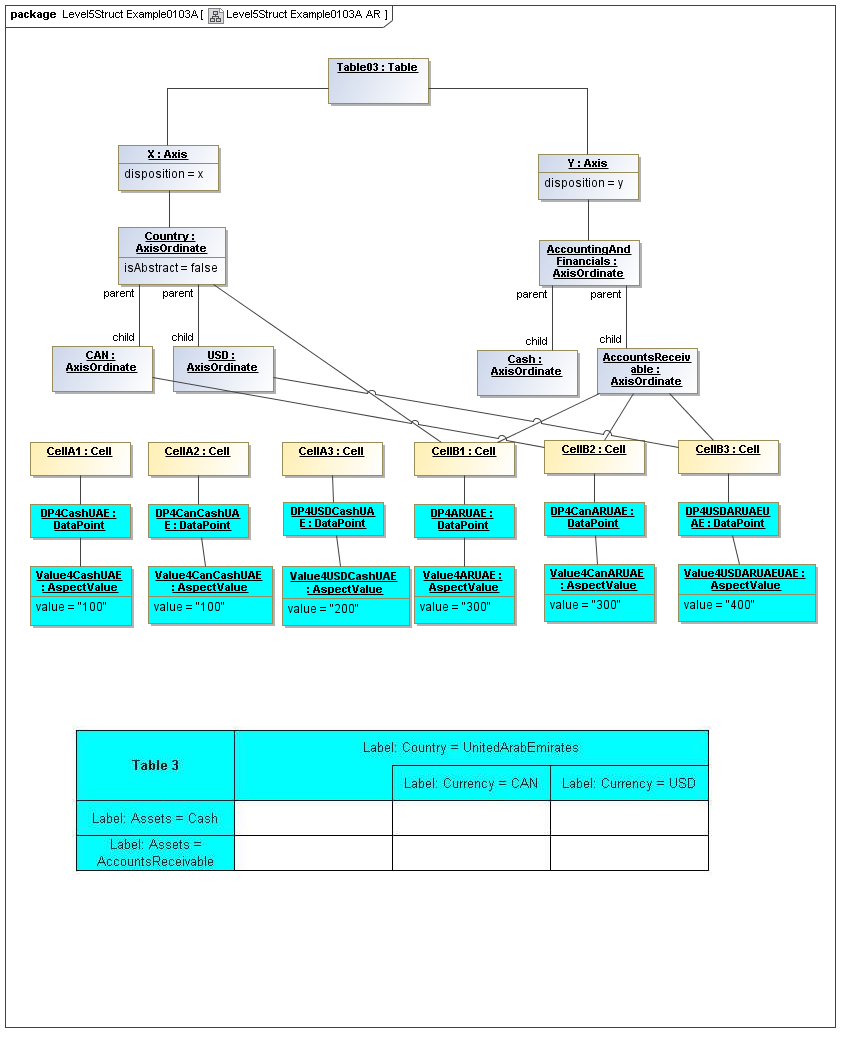
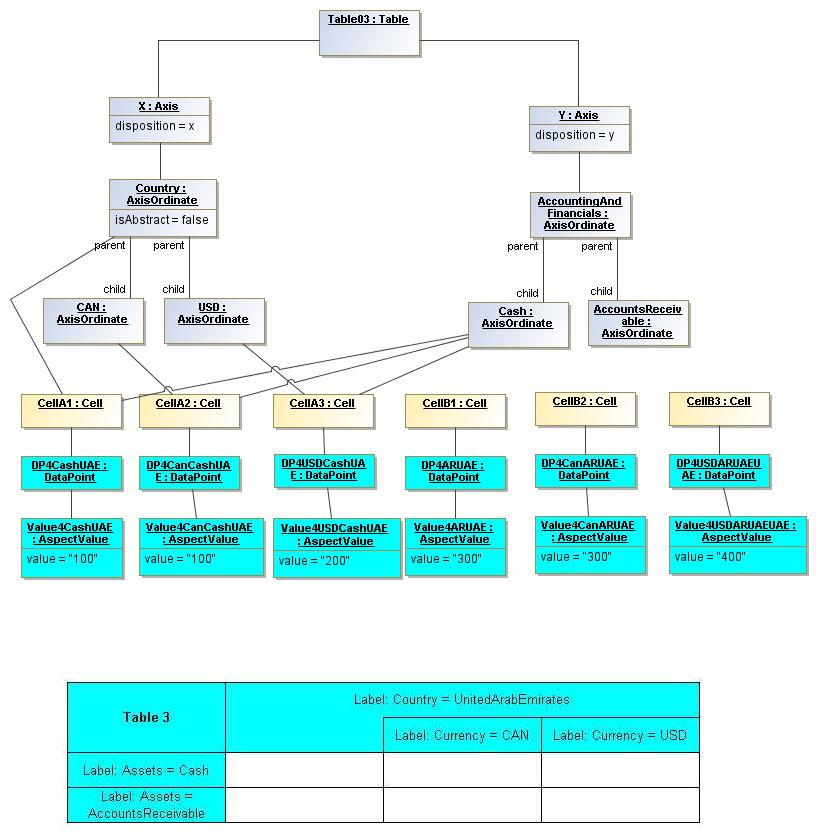
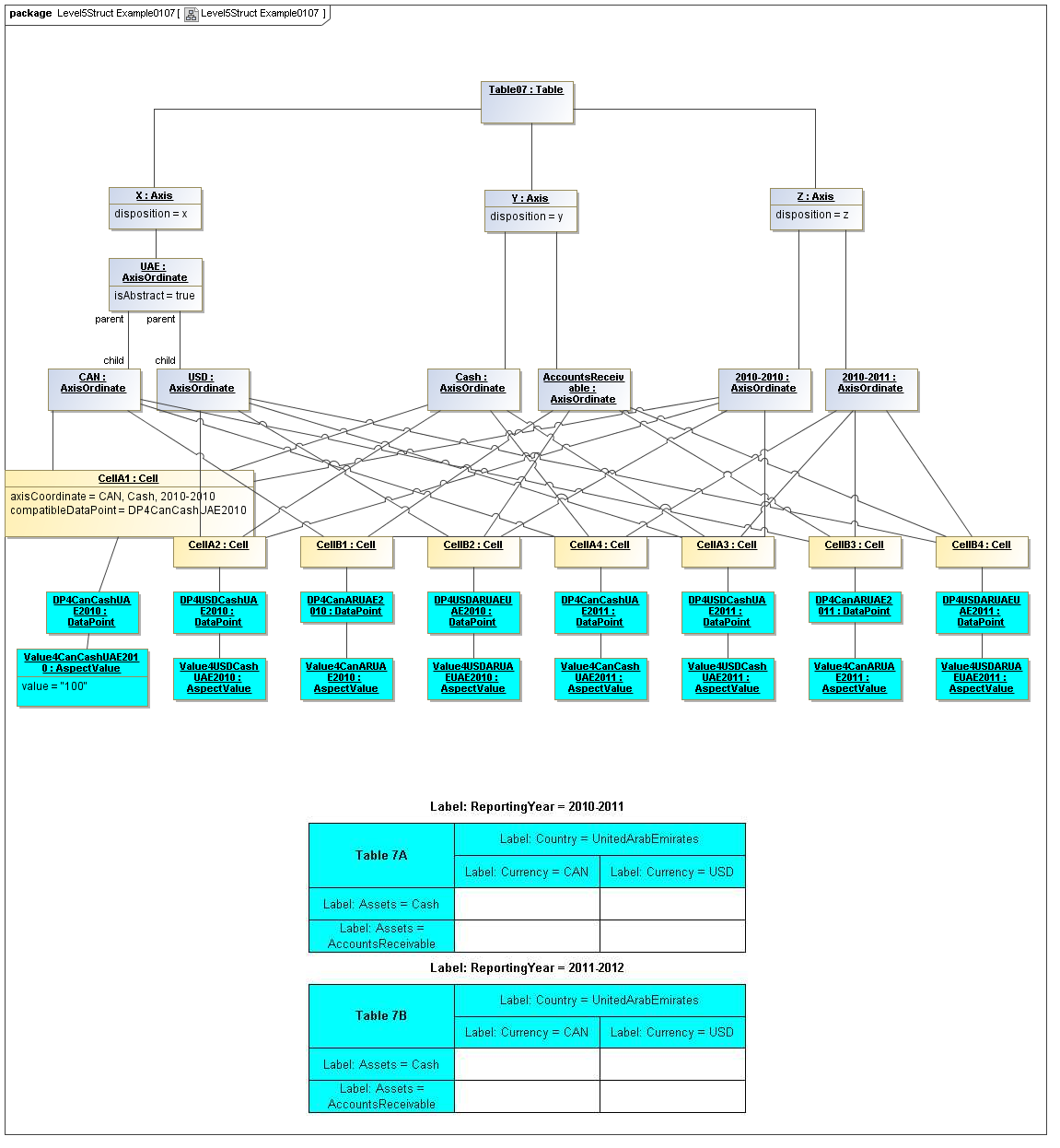
3.5.3 Table Cells
Instances of tables are shown, to illustrate how the coordinate locations map to cells (as on a spreadsheet or grid). Each cell may have a compatible DataPoint that would render in a view, be editable, or if the cell were empty, be created by entering into a cell.
A DataPoint is compatible with a cell if its aspect values match all the aspect values associated with each axis for the coordinate position of the cell
If a cube is associated with a table by a validCube relationship, the aspect values of coordinates of a cell must be valid in the cube in order for any DataPoint to be compatible with the cell. Otherwise the cell is disallowed (no data presented, and not editable for entry).
If no validCube relationships are provided, but Cubes are specified, at least one must allow the aspect values of coordinates of a cell in order to be presented or entered. If no Cubes exist in the current model, then any DataPoint aspects are allowed and cube-compatibility is not checked.
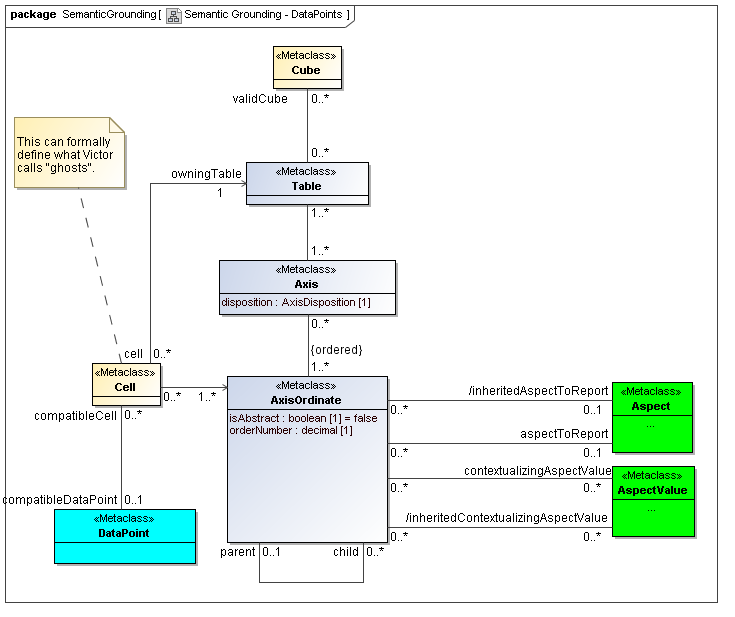
3.6 Document Model
Captures the packaging of realized instances of data points with their data dictionary model instances, valid combinations model instances, and table model instances. In present XBRL realization, it may be an XBRL instance document filing with accompanying taxonomy and linkbases.

3.6.1 Manifest
Manifest
The Manifest metaclass defines what is packaged in the Documennt.
Rationale
Specification of document contents includes Facts (e.g., their AtomicAspect value and identifying Aspects AspectValues, with reference to or inclusion of DataDictionary, Typing model, CubeRegions, Table model, and any Formulae. In the cases such as Inline XBRL the manifest also includes a rendering of the Facts.
Properties
Facts contained in the document.
DataDictionary representing contents of the document.
CubeRegion representing contents of the document.
Tables representing view(s) of contents of the document.
Formulae representing validations and derived information for the document.
3.7 DTS Model
Captures labels and references, abstractions of prohibition/override, formula, and validation.
[Dave Frankel: We are not clear that labels and references will be first class objects in the metamodel. RAS-like stuff can go here. Not clear yet on relationship between the Document and DTS packages.]
[Herm Fischer: Labels that comprise formal internal semantic definition, and references that comprise formal external semantic definition, to such extent as that, do belong perhaps in the data dictionary.]

3.8 Typing Model
Captures the underlying types that have been defined by both XBRL 2.1, for use in data points fact values and aspect values.
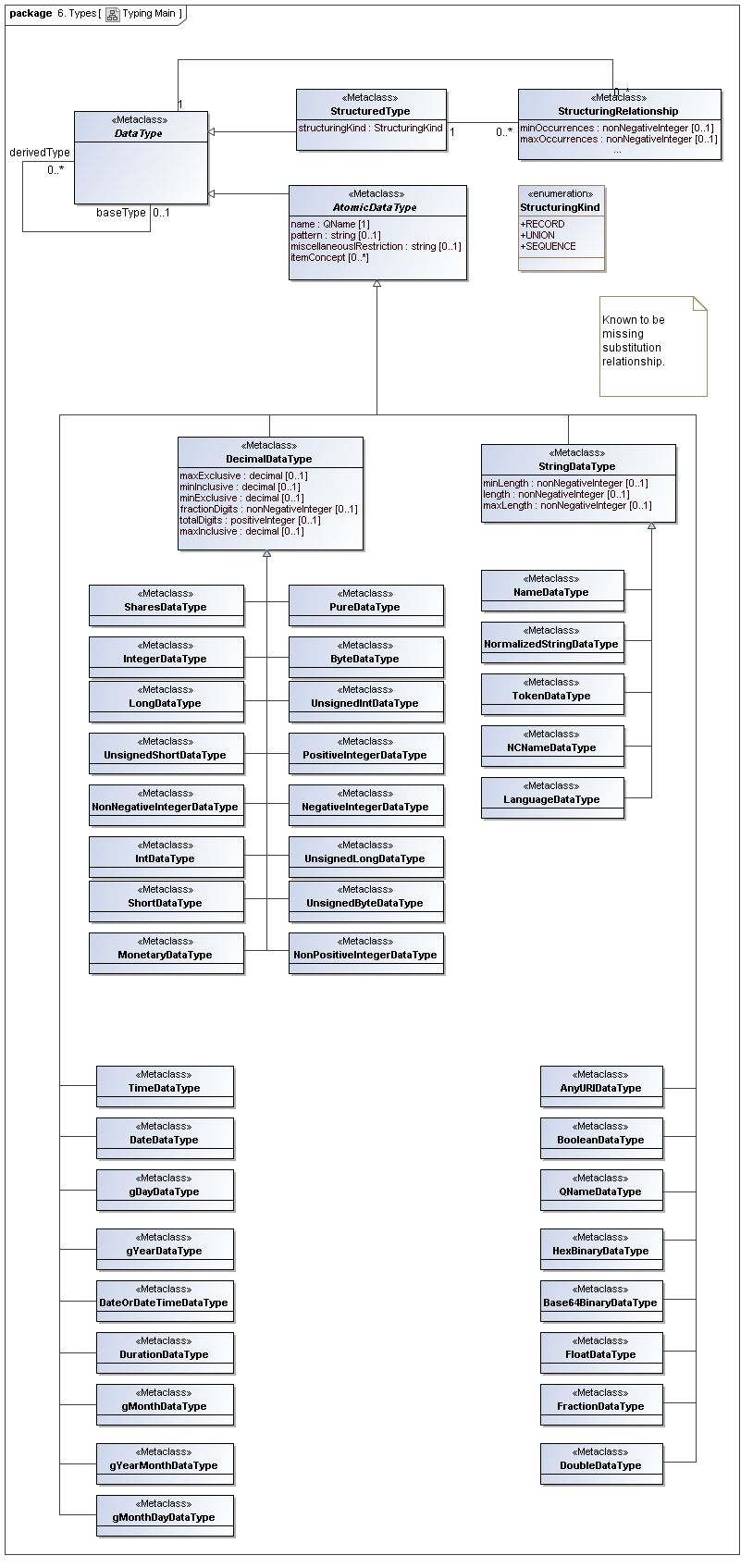
3.8.1 AtomicAspect
AtomicAspect
The AtomicAspect metaclass defines an atomic value that a singluar instance of its structure may contain (such as number type, date, or string contents, or entries in a list).
Rationale
A fact may have FactValue (of its AtomicAspect) and an AspectValue of each of its DataPoint Aspects, each according to its DataType.
Properties
DataType describes the atomic value constraints.
3.8.2 StructuredAspect
StructuredAspect
The StructuredAspect metaclass defines an composition structure for a FactValue or AspectValue.
Rationale
DataTypes may be composed of structures, such as lists and hierarchies of specified atomic content.
Properties
StructuredAspect describes the compositional constraints of a DataType.
4 Secondary model - XBRL
The secondary XBRL model represents a layer of XBRL realization of the primary model, representing instances, discoverable taxonomy sets of taxonomies and linkbases, supporting type and particle model declarations of XML constructs for elements, attributes, and concepts, and extension models of formula and versioning. Starting first are an "ordinary" financial reporting instance, an inline XBRL instance, an XBRL discoverable taxonomy set (of schemas and linkbases), XML element and concept Types (including particles because they are the elements that are all over the instance model), atomic types (which mirror the primary model types layer but as concrete XML types), Dimensions, and for completeness Formula, filters (sort of), and Versioning.
[Warwick Foster: At this stage our primary focus has been on the primary model. As such, at this stage, the primary model is more advanced than the secondary model with regards to our current thinking about XBRL.]
4.1 XBRL Instance
[Herm Fischer: This model represents a secondary layer of XBRL Instances, as using top layer meta model constructs. The ordinary instance seems substantially different from that of PWD 1.0 but I think it maps nicely into data points (and DTS). It also ties some stuff of great interest to auditors to the semantics (the document, or serialized XML media)]

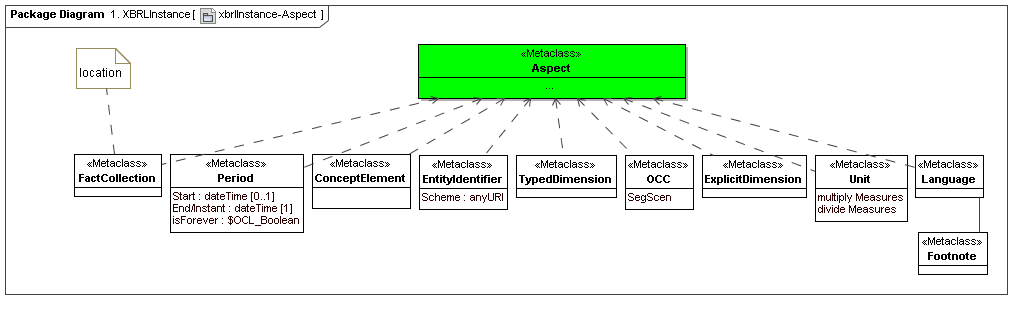
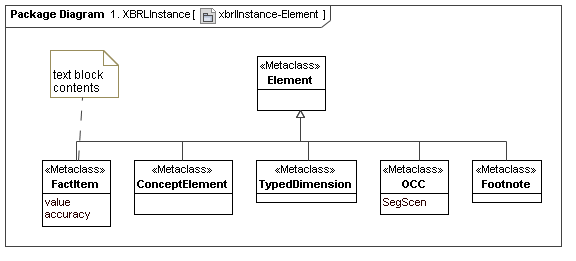
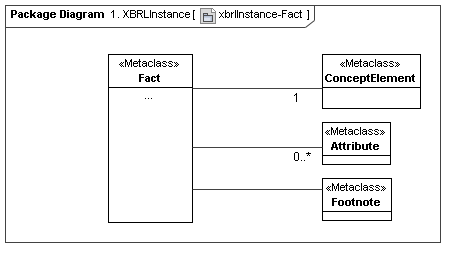
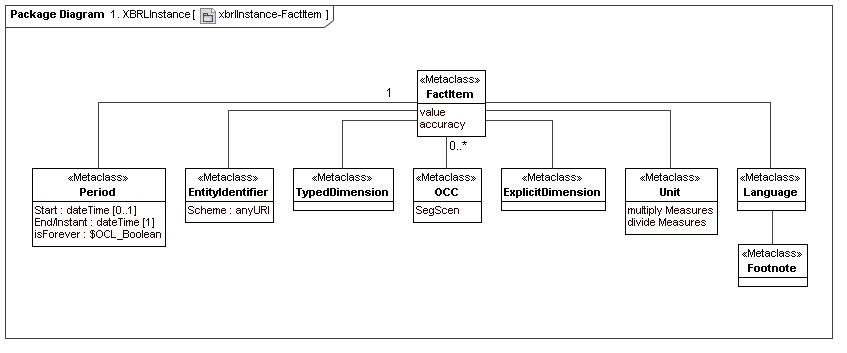
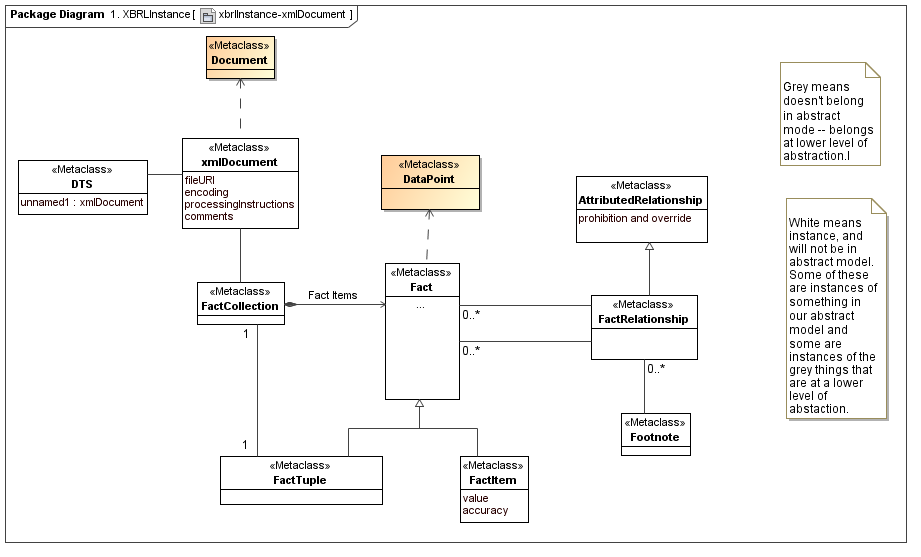
4.2 XBRL Inline Instance
The inline instance ties the document (serialized instance and elements) "above the transform" that are of interest to auditors, to the data points (and sort of obfuscated aspects) that are of interest to the business analyst
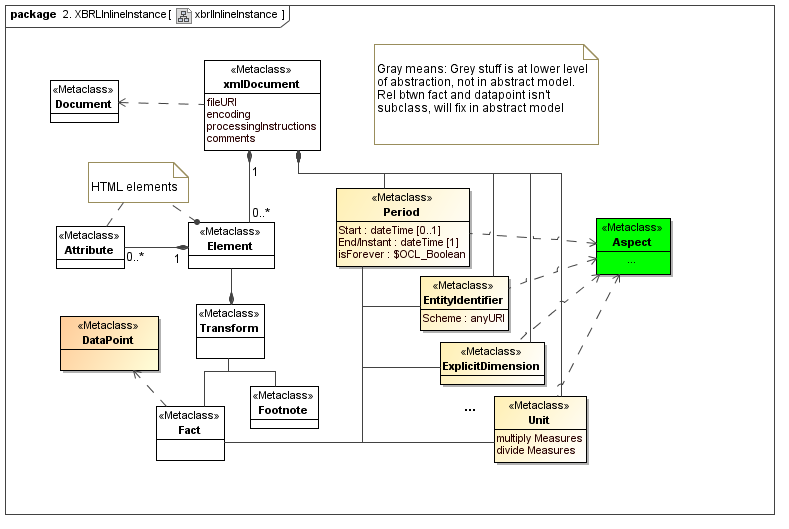
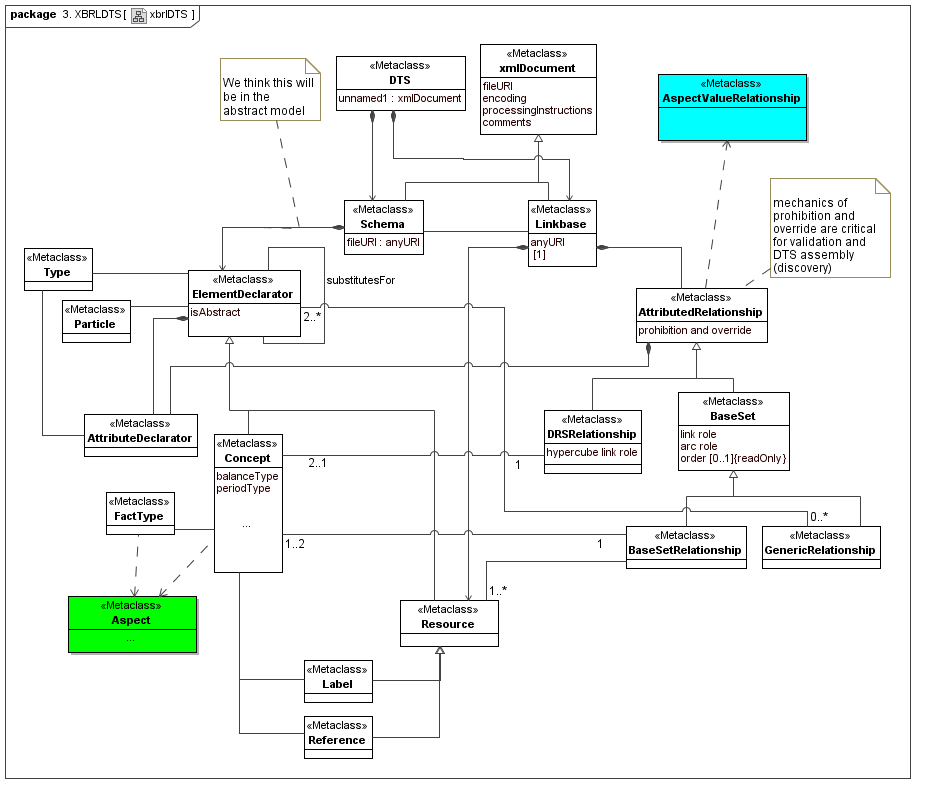
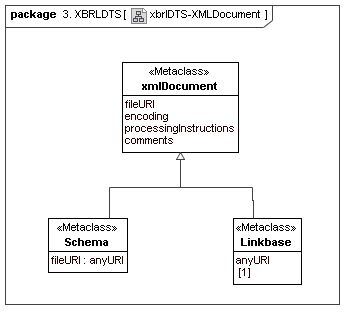
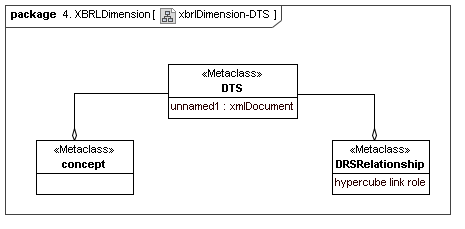
4.3 XBRL DTS
This secondary model represents how XBRL declares its structural and ontological semantics. A lot of XBRL DTS concrete implementation is not part of data points or aspects, but is how the aspect to aspect relationships and aspect value selection cube regions are mechanized. They represent both typing (structural and atomic) and ontological semantics (via aspect values relationships hierarchy).
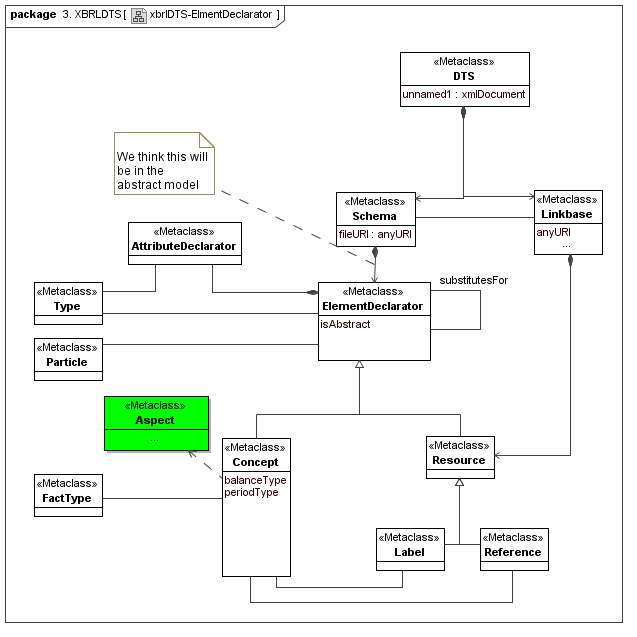
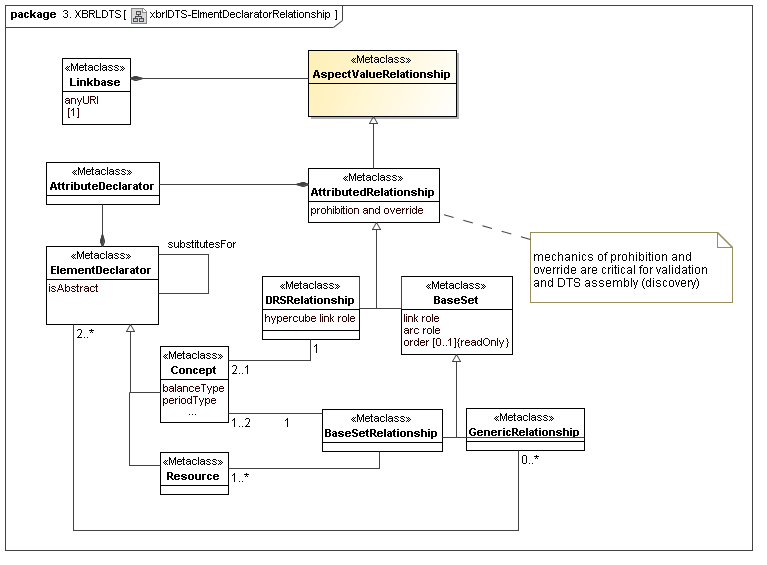
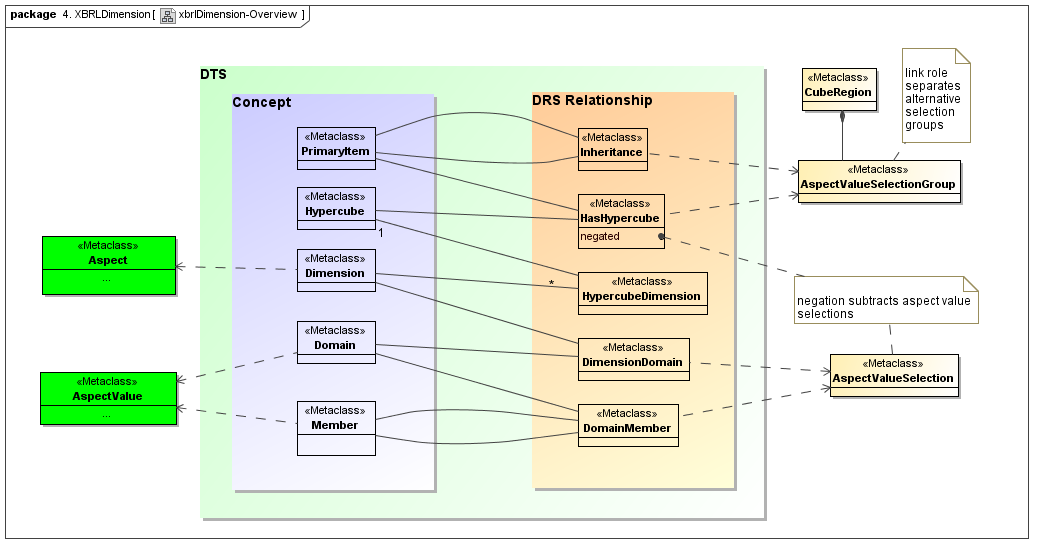
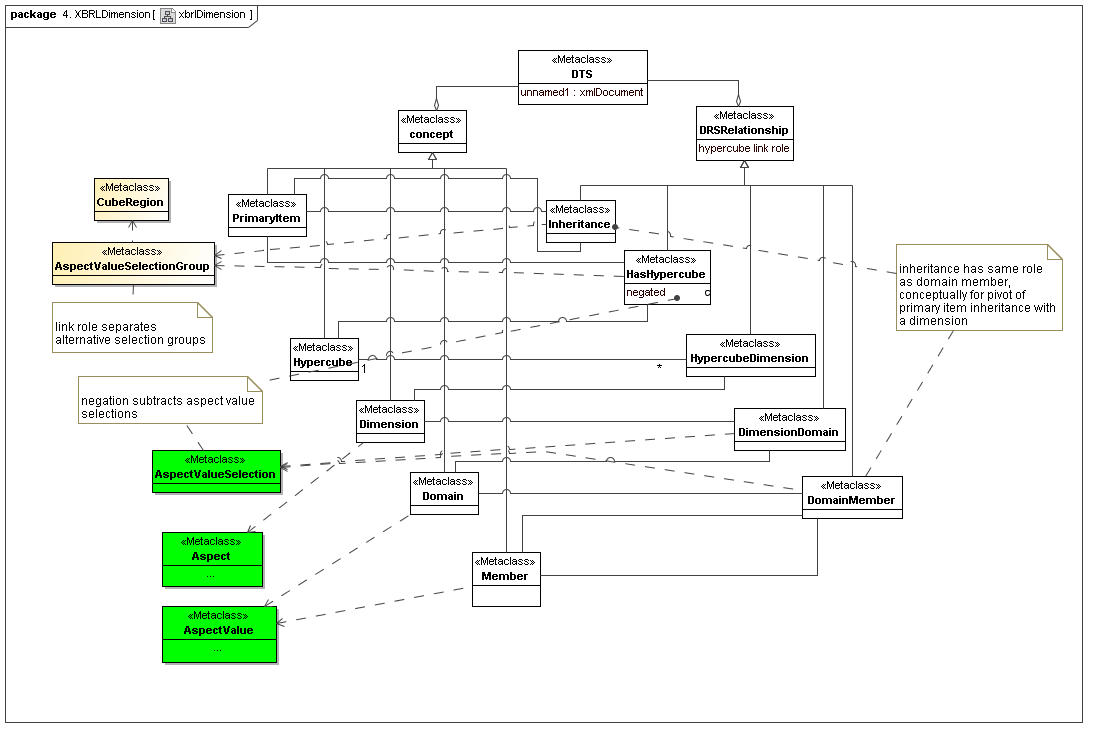
4.4 XBRL Dimension
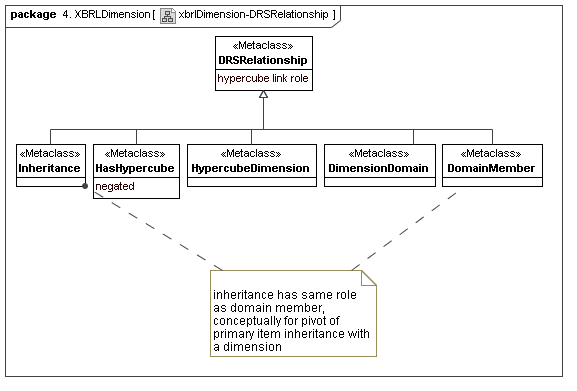
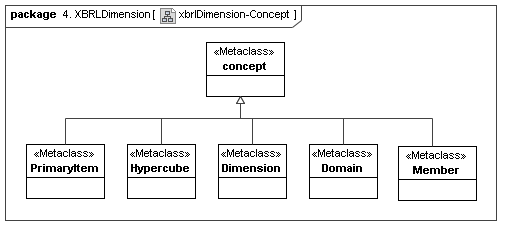
This secondary model represents how XBRL declares its dimensions. They correspond to three primary model elements, aspects (that are dimensions), aspect value relationship sets and hierarchies (that represent both allowed values, and usually provide a concrete model of ontological semantics), and they provide a concrete means of implementing cube regions. The cube region implementation is by substraction of cross products of dimensions from very large and sparce multi-dimensional spaces.
4.5 XBRL Table
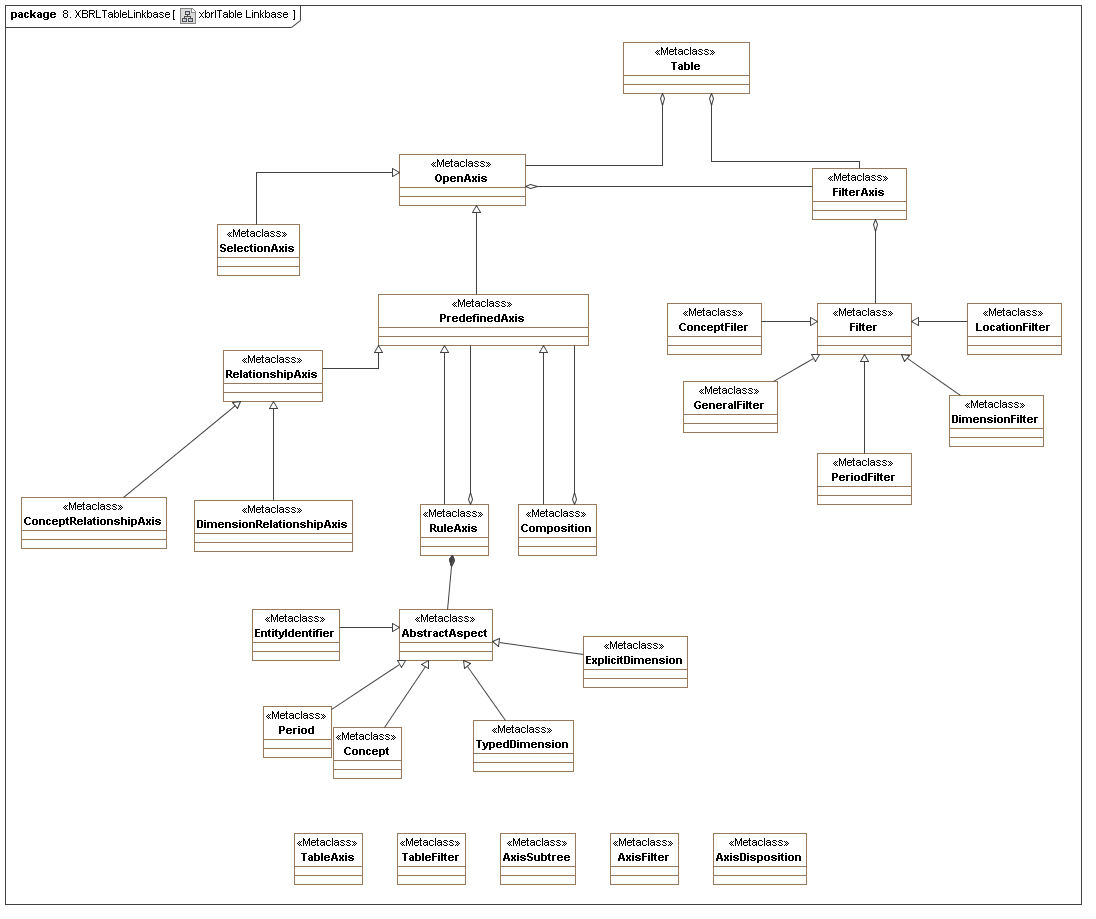
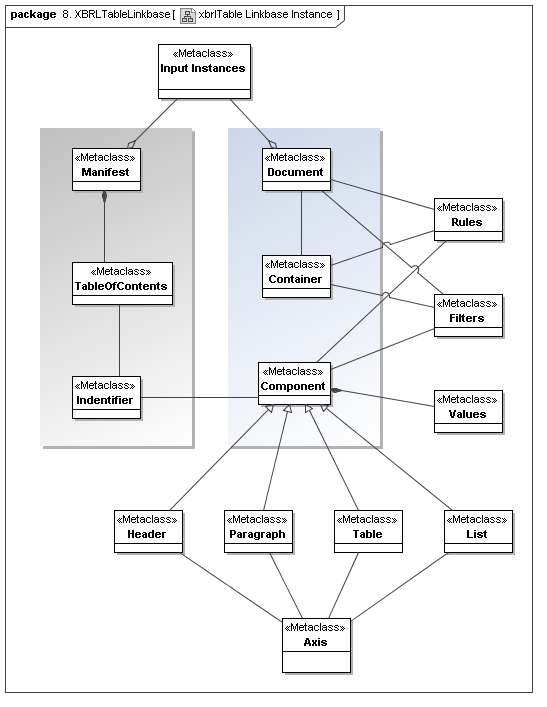
This secondary model represents how XBRL declares tables, their axes, filters, and coordinates.
4.6 XBRL and XML Typing
This secondary model represents how XBRL declares its typing and structural semantics in dual-interwoven models (XML's typing model and XML's particle models). In effect they implement the primary typing model, but the concrete issues differ.
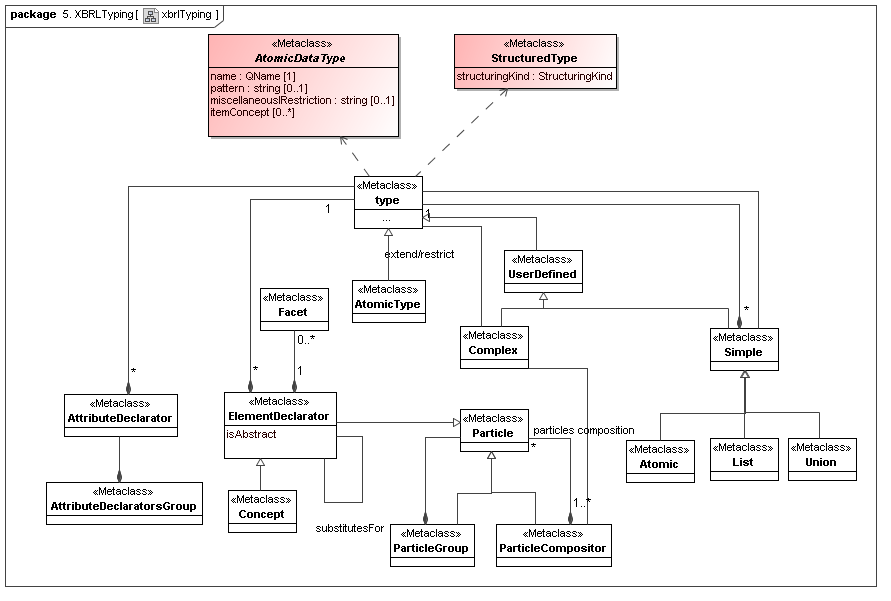
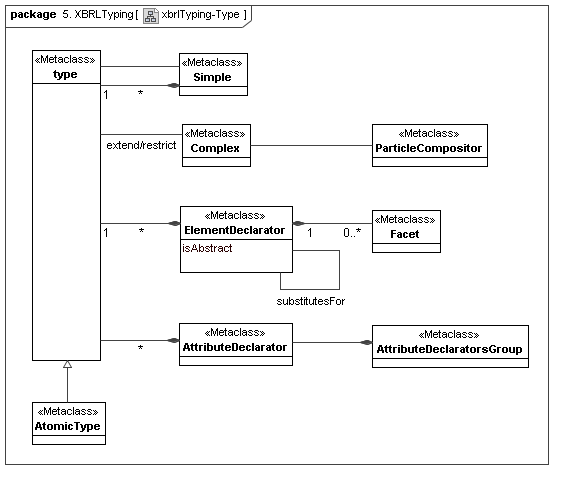
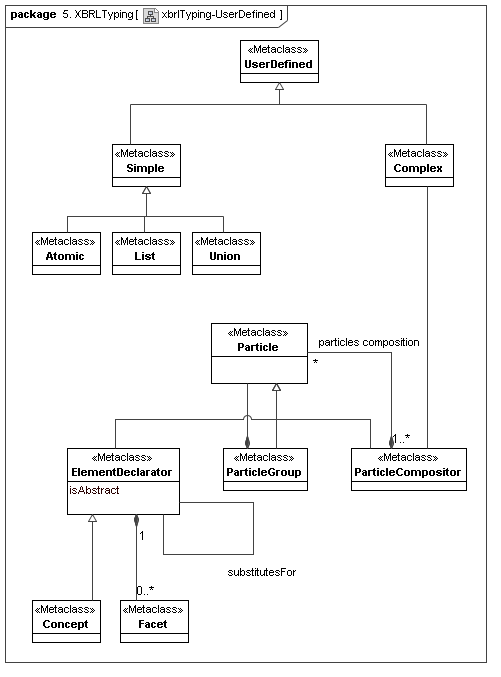
4.7 XBRL Formula
This secondary model represents how XBRL declares its assertion sets and variable sets (representing the managed result-producing constructs of XBRL formula).
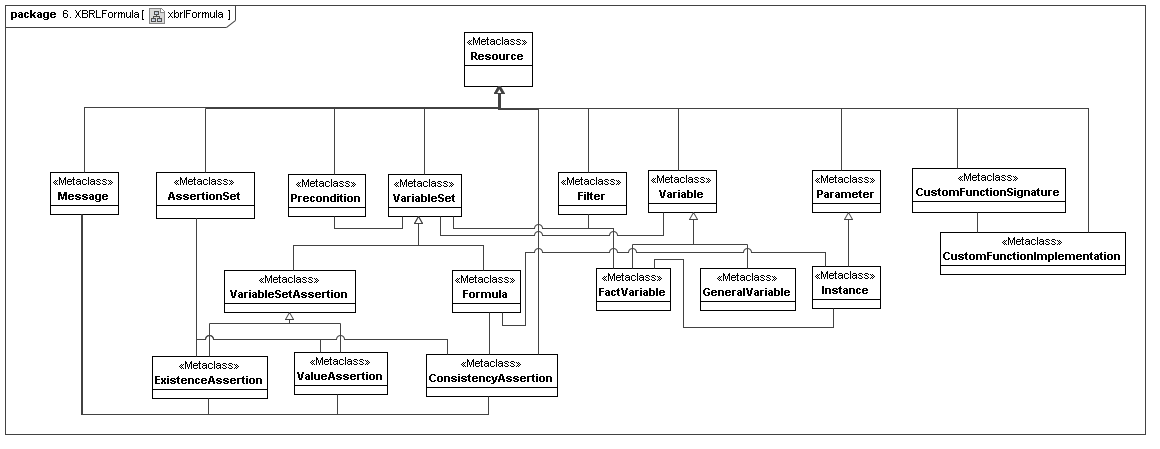
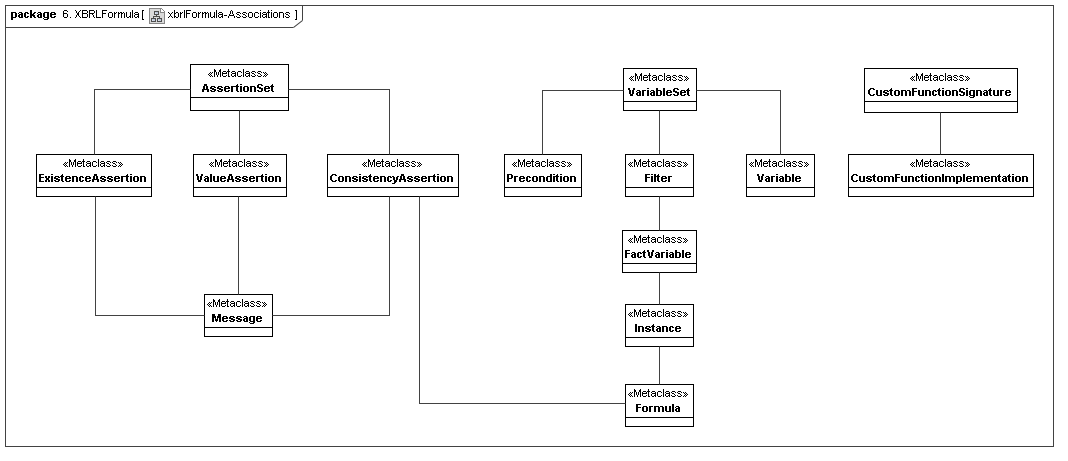
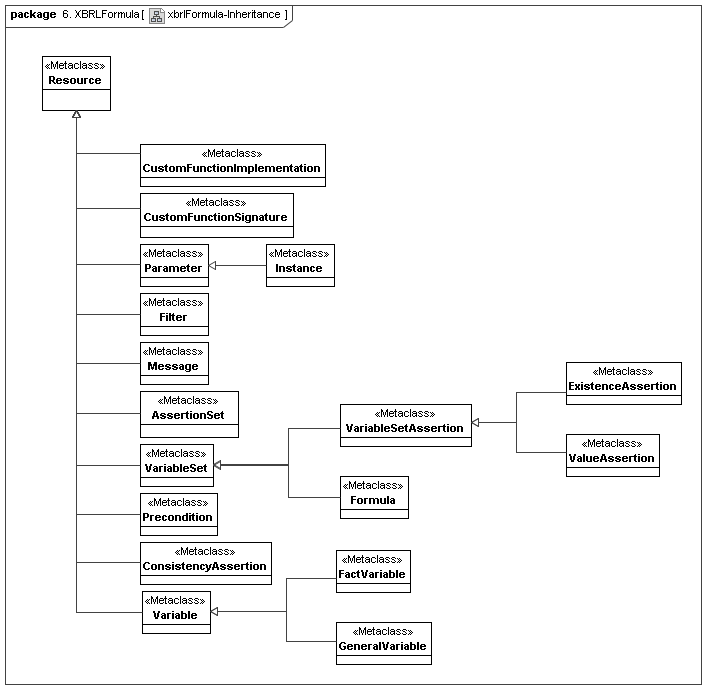
4.8 XBRL Versioning
This secondary model represents how XBRL reports versioining events. They are based on notions of XBRL concept and inter-concept changes, as well as aspect model issues. Only the aspect modeling reporting directly represents primary layer issues. [Herm Fischer: One may realize that versioning could evolve to a 2.0 to re-invent the concept-based event reporting into aspect-based event reporting.]
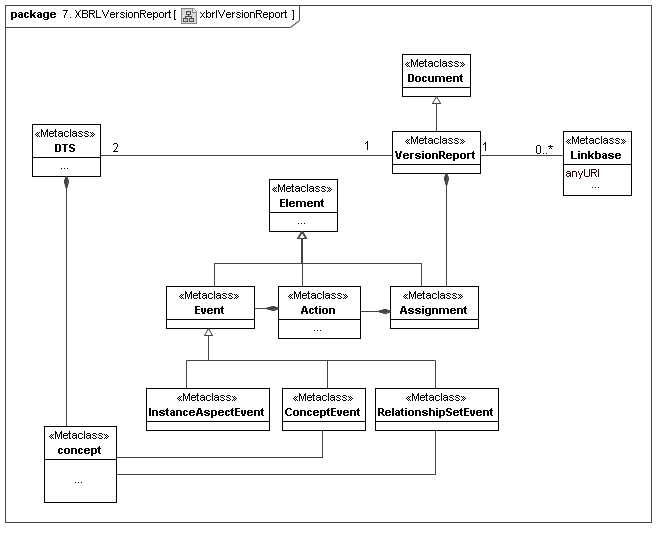
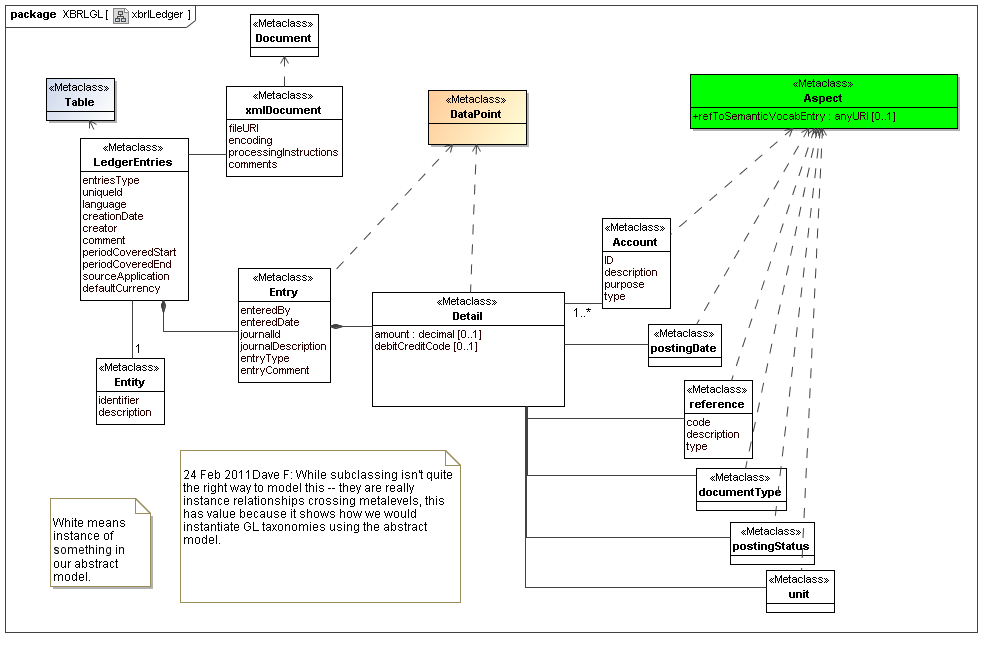
5 Secondary model - Global Ledger
The secondary Global Ledger model represents that financial reports come from ledgers (and journals), to show how ledger entries (GL) fit to data points (when not viewed as syntax). [Herm Fischer: This model makes me want to propose a GL aspect model (for formula and versioning), and stop using the FR aspect model for formulas upon GL entries.]
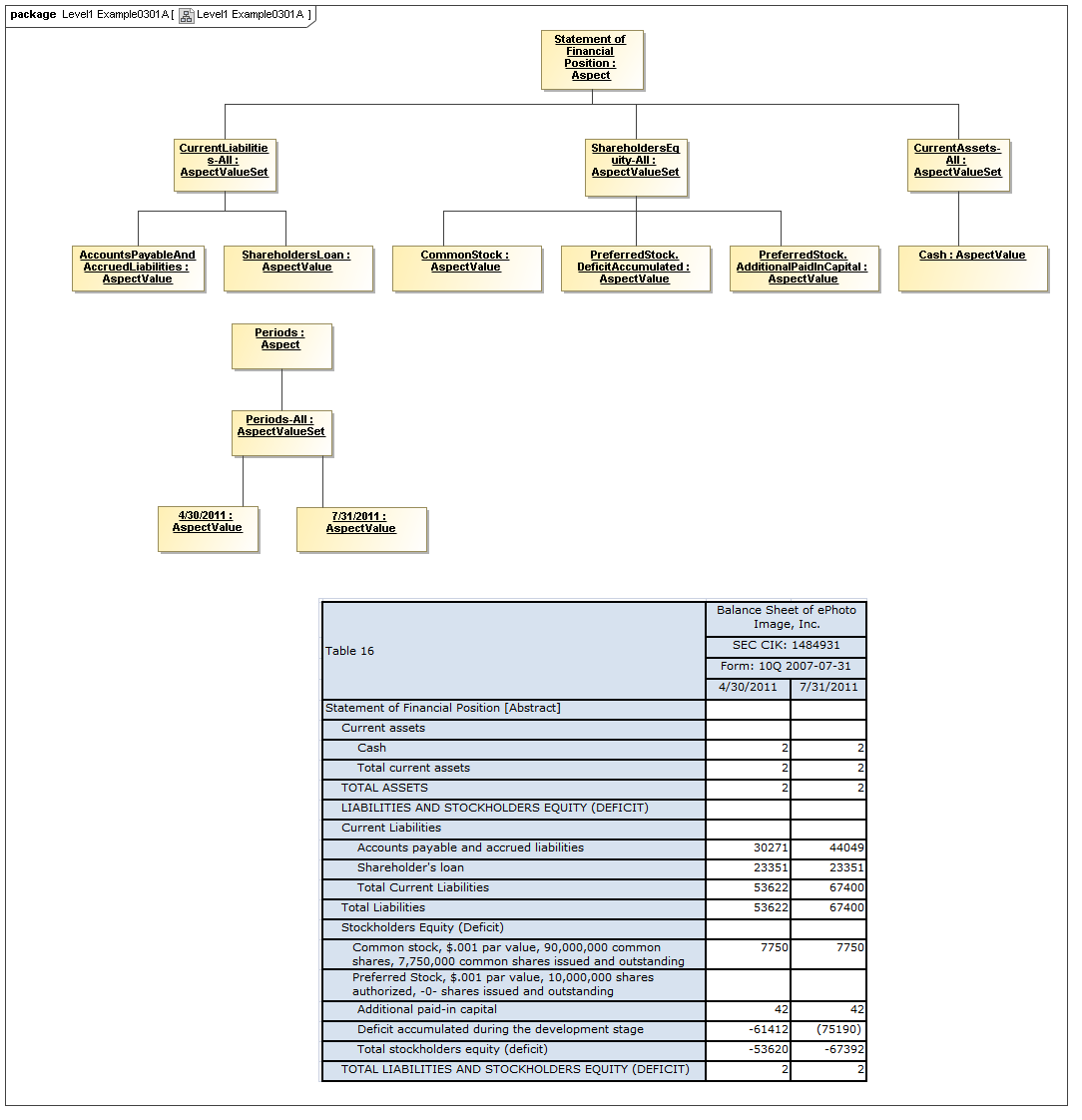
6 Secondary model - Financial Report Logical Model
A Financial Report Logical Model and its Report Elements are described in section 5, including details in section 5.19 [MDLBUSINFOXBRL], and "SEC Logical Model" [MDLBUSINFOXBRLDIAG].
6.1 Finanacial Report
This diagram relates the primary model elements to the Financial Report Logical Model.
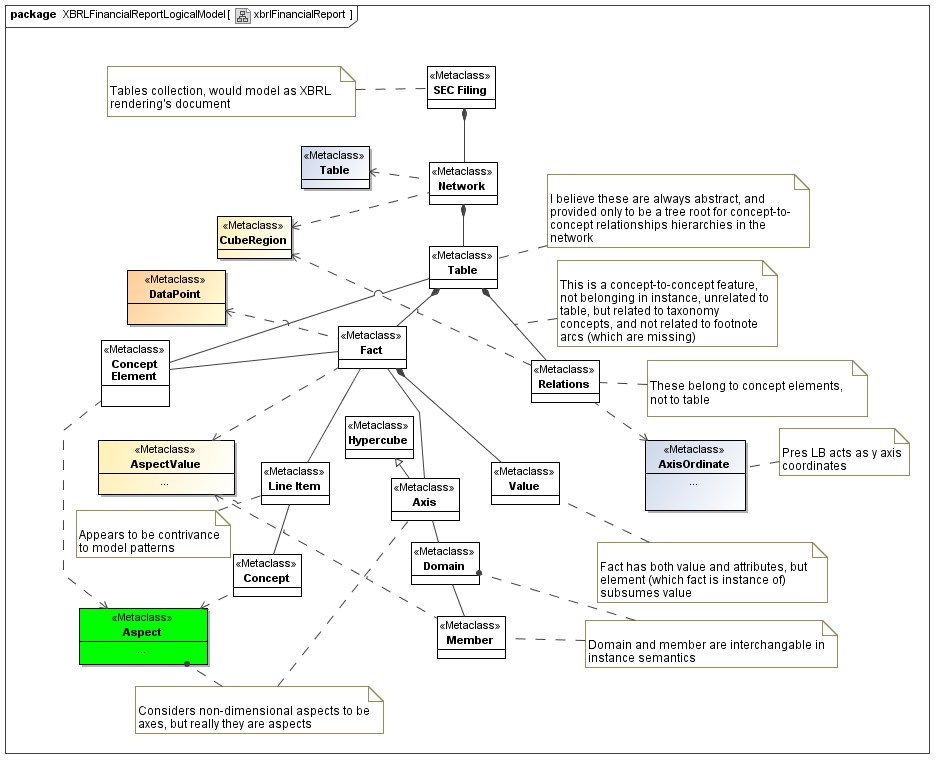
The notion of a document as a collection of tables ("SEC Filing") is in the fujitsu "Rendering Linkbase" and has been introduced to the primary layer as a result of this model.
This logical model interleaves taxonomy and instance, description of class and property of instance, in a profound manner, but nonetheless the elements map to the concepts of the primary model.
Network is a cube region's table, it is used as such by the SEC viewer, and Edgar Filer Manual requires that it be constructed for that purpose.
Network, corresponds to an XBRL ELR, and as thus a cube region's set of aspects that have relationships, represented by a dashed line from cube region to relationships to concept elements (the presentation/calc/dimensional-relationship-set relationships).
Table (the term of this logical model, not the term of the primary layer) is represets XBRL concepts that are abstract, being used as root elements in hierarchies (because XLink requires root elements in this manner), and has absolutely ontologic meaning in the instance, and only tree-building-purpose in the presentation linkbase. It is not an identifying aspect of a data point primary item and doesn't correspond to any primary layer model elements.
Table (logical model term) is a syntactic contrivance to associate concept-to-concept relationships with a cube region of the table (mapped, as an XBRL ELR).
Relationships in XBRL relate to a table (as an organizing abstract concept not in the instance), and actually belong to the primary layer aspects of the cube region (both concept element and dimensional element aspects).
The logical model XBRL presentation relationships are there to organize the "y-coordinates" order of the concept-element aspects into rows of the table.
In logical model calculation relationships, may either be used for computational validation, or to capture XBRL ontological semantics not otherwise communicated (See use to identify concept aspects which are chosen in a nonstandard manner, and figures 3 - 5.[XBRLSECFILINGRATIOS]), but aren't otherwise aspect relationships of a fact-identification aspect model.
Fact is an instance of a data point. It does have a concept-element aspect but also it has domain member aspects. It doesn't have axes (dimensions) or domains (hierarchy-head members).
This logical model is valuable to show what might be perceived by people examining XBRL syntax and in enforcing modelling discipline.
7 Feedback requested
The Abstract Modelling Task Force is seeking your input and opinions on these specific topics:
- TBD
Feedback can sent to modelling-feedback@xbrl.org.