1 Introduction
This is a Use Case document that captures some of the main ways that people and computers should interact when using Inline XBRL. Inline XBRL is designed to resolve the problem faced by document preparers in their dealings with the eXtensible Business Reporting Language (See [XBRL 2.1] ). Conceptually, Inline XBRL draws on the ideas used by the Microformats group.
Inline XBRL, like Microformats, rejects the idea that data and formatting must be separate. The "traditional" view is that applications should produce an XBRL instance document and an XBRL-specific set of rendering metadata that need to be combined via a stylesheet or rendering pre-processor to create something that is human readable. However, it is easier for software developers, especially accounting software vendors, to create reports in XHTML that contain XBRL fragments. This means that vendors need only work out how to create XHTML documents and can adapt existing report rendering capabilities to format business reports. A normative stylesheet can then reliably and predictably strip out the unstructured information from the XHTML and create a valid XBRL instance document. This is simpler, provides more control and flexibility in report formatting, and can be fairly easily implemented.
Inline XBRL makes it possible to extract an XBRL instance document on demand. This means that the technique makes it feasible for regulators, exchanges, banks and others responsible for the collection of business reports in XBRL format to ask preparers to merely submit their information as an Inline XBRL document. This is a human readable XHTML file that can be stored and redistributed in this original format. At any time, the XBRL instance document can be created, validated and passed on to relevant analytical processes.
2 Background
Professionals responsible for the production and dissemination of business reports are generally concerned that the information they release is carefully formatted. Accounting documents (particularly financial disclosures) attract special attention from preparers, auditors and securities regulators. The manner in which they are formatted - from ensuring that figures are correctly aligned, that sub-totals and totals are suitably emphasised all the way through, to the font-size of footnotes - can all be important. Individual preparers have different preferences and these, too, need to be taken into account.
While users of financial and business information are often entirely unconcerned about the way that preparers format their documents, this is not always the case. There are often legal and generally customary reasons that make it convenient for users to be able to refer to the "hard copy" , even where they are really referring to an on-screen document.
The purpose of Inline XBRL, then, is to make it possible to deliver structured, machine-readable data inside a human readable rendering of these data.
3 Relationship to other work
This document has been prepared with reference to the Inline XBRL Wiki. [CFLWIKI] .
4 Terminology
The term Actor is referring to a person or system that interacts with an Inline XBRL document.
4.1 Types of Actors
The Actor referred to as a Report Writer is a system or module of a system that creates Inline XBRL documents.
The Actor referred to as a Preparer is a person responsible for the creation and dissemination of a business report.
The Actor referred to as an Analytic System refers to a system that consumes XBRL for input into an analytical process.
The Actor referred to as an Analyst refers to a person charged with the review of a business report, for decision-making of one sort or another.
The Actor referred to as a Data Collector is a generic term given to the organisation with the authority to require that data be provided to it, including in XBRL format.
4.1.1 Types of Data Collectors
The Data Collector referred to as a Regulator is a statutory authority obliged to collect business performance information from entities within its jurisdiction, either for analysis or for public dissemination to allow market participants to analyse. Examples include securities regulators, tax authorities, companies registrars, prudential and monetary policy authorities.
The Data Collector referred to as a Securities Exchange is a securities trade and clearing house often charged with, among other things, the periodic collection and re-dissemination of market sensitive performance information about the securities listed there.
The Data Collector referred to as a Headquarters is a generic term given to a central organising unit of a company or agency that requires operating divisions or legal units of that organisation to provide information to it in order to monitor performance and/or consolidate information across the business.
5 Document conventions
The following formatting is used for normative technical material in this document:
Text of the normative example.
The following formatting is used for non-normative examples in this document:
Text of the helpful example.
The following formatting is used for non-normative counterexamples (examples of poor, discouraged or disallowed usage) in this document:
Text of the counter example.
6 Use cases
6.1 Use Case 1: Report Preparation
A Preparer needs to publish a company financial report by filing it with the national securities regulator .
The major steps in this use case are shown in Figure 1 . Notice that only the main steps are shown and that the key aspects of the use case (that relate to the way that the Inline XBRL is actually created) are outlined in blue. The use case is described in detail below. Note that the numbers in the diagram relate to the steps set out in Section 6.1.4 .
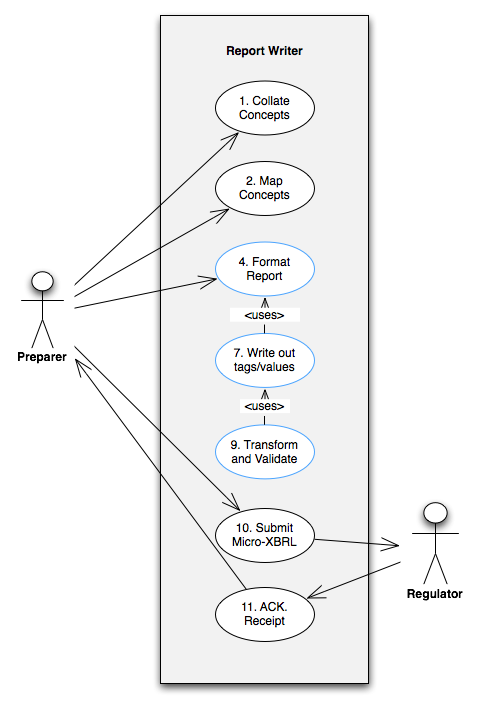
6.1.1 Summary
The Preparer collates the information needed for the financial report from the necessary systems and processes and uses the Report Writer to determine the optimal way to present the resulting report in human readable form. The Preparer maps each reporting term that is going to be presented as an XBRL fact to the relevant concept contained in the XBRL taxonomy. [ 1 ] The Preparer must also determine the XBRL contexts against which each concept will be reported. Of course, in both these steps the Preparer will normally use the functionality of the Report Writer .
Armed with information about content, metadata and presentation, the Report Writer lays out the report in XHTML format. Relevant XBRL header information - identifying the XBRL base schemas and taxonomies in use - is written out to the report in a manner that is machine, but not easily human, readable. Similarly, the XBRL contexts that are used in the report are written into the XHTML.
Each reporting fact is written out to the XHTML, bracketed
by XBRL fragments identifying the taxonomy concept in use
(ie: the tag), the context which the fact relates to, as well
as the reporting unit (ie: currency or other unit of
measure), and the precision attribute for numeric and monetary
items. A special
scale
indicator is also written out for numeric and monetary
items. This allows the stylesheet to unambiguously transform
values from their shortened form (eg: "In millions") into an
actual number.
This process is repeated for every reported fact that is to be disclosed in XBRL format.
The resulting XHTML document can then be saved in preparation for filing.
The Report Writer will either use a copy of the XBRL normative stylesheet (which will be published as part of the Inline XBRL specification) or use a trusted web-based service to make that normative transformation. The Report Writer should then validate the resulting XBRL instance document to ensure that the instance document conforms to the published taxonomy.
The Report Writer will confirm to the Preparer that the document is ready to be filed. The Preparer can either use the capabilities of the Report Writer to carry out that filing, or use whatever other process for authentication and secure delivery that the Regulator has defined. In most circumstances, the Regulator will provide an acknowledgement back to the user.
6.1.2 Actors
The Preparer is responsible for creating the financial report, based on the output of one or more accounting trial balances as well as a range of other inputs.
The Report Writer is used by the Preparer to collate the reporting facts and determine the manner in which they will be laid out on a page. This might be done with or without an application-specific template.
The Regulator receives, validates and acknowledges performance reports provided by the Preparer .
6.1.3 Triggers
Report Preparation is triggered by statutory, market or corporate obligations to produce financial reports.
6.1.4 Basic course of events
6.1.4.1 Collate component information
The Preparer identifies the sources of the information needed to produce the required performance report. These sources will typically range from a single Trial Balance, multiple Trial Balances, one or more consolidation systems (such as Hyperion, Word and Excel documents) and/or a range of internal applications and processes.
6.1.4.2 Map source components to XBRL taxonomy
The Preparer uses the Report Writer to map the source components of the performance report to the relevant XBRL concepts contained in the chosen taxonomy (strictly, the discoverable taxonomy set).
It should be noted that the Report Writer could be a module of a consolidation system or an external application, including fairly light-weight tools such as Excel plug-ins.
To describe the steps associated with the production of an Extension Taxonomy is outside of the scope of this Use Case. However, readers should be aware that the Preparer may, in many cases, need to manage the creation of an extension taxonomy. This could simply involve the addition of company-specific concepts, the addition of unique labels for otherwise standard concepts, changes to a calculation framework, or similar. This is an important aspect of XBRL document production, but is needed regardless of whether the Preparer is creating a simple XBRL instance document or a more usable Inline XBRL document. It will often be managed from within the Report Writer or it might be done outside of that tool; for instance, within a taxonomy-development platform. In any event, the process is ignored in this document.
6.1.4.3 Define contexts that will be used
The Preparer uses the Report Writer to manage the definition of XBRL contexts. These include uniquely identifying corporate entity information, the dates associated with concepts appearing within the report, as well as segment and scenario information. The contexts act as unique keys to associate with facts.
Note that segment and scenario indicators often need to be constrained by reference to a Dimensional taxonomy that deals with reporting structures.
6.1.4.4 Format the report
The Preparer uses the Report Writer to lay out the performance report as needed. The level of fine grained formatting that is required is generally an equilibrium between the Report Writer's capabilities and the Preparer's aspirations.
Report formatting is something that a wide range of Report Writer applications, without XBRL capabilities, do today. Most, although not all, can create HTML or XHTML versions of those reports.
Preparers and their advisers (particuliarly auditors and lawyers) have been known to spend an inordinate amount of time on the look and feel of their financial disclosures. Preparers expect that their financials will be consumed as complete documents and generally taken as a whole. This in no way reflects the analytical reality, but is an important aspect of business report production, both culturally and, in many areas, legally.
6.1.4.5 Embed the XBRL boilerplate into the XHTML
The Report Writer identifies the base XBRL schemas that need to be referenced to allow the resulting XBRL instance document to be validated, together with the taxonomy entry point (or taxonomies) that need to be referenced inside the instance document via namespace declarations. This header information is written out to the XHTML document in a manner that will be ignored by web browsers.
6.1.4.6 Embed context fragments into the XHTML
The Report Writer uses the information previously determined about the contexts (that need to be referenced by individual reporting facts) and writes these XBRL fragments out to the XHTML document in a manner that will be ignored by web browsers.
6.1.4.7 Bracket reporting facts with XBRL tags
The
Report Writer
writes out reporting facts in plain XHTML, but brackets
that information with XBRL instance fragments containing
the tags, context IDs, precision attributes, unit IDs and
the special
scale
element. The stylesheet will use these opening and closing
tags, together with the (visible) contents of the tags, to
generate XBRL instance facts.
This process is repeated for every fact that needs to be written into the report. Note that while there are, in theory, mechanisms that would make the XHTML less verbose (for instance by nesting context IDs for dimensionally equivilent facts) the advantage of this bracketing mechanism is simplicity and flexibility.
To understand this process somewhat better, consider the following graphic:

6.1.4.8 Save the resulting file
The Report Writer saves the resulting file. Presumably most applications will provide a WYSIWG editing environment that will collapse the formatting and "bracketing" steps.
6.1.4.9 Transform the XHTML into an XBRL instance and validate that file
The Report Writer should transform the Inline XBRL document into an XBRL instance document, using either a local copy of the normative stylesheet or via a trusted web service.
The Report Writer should validate the resulting instance document using an XBRL conformant validator.
6.1.4.10 Submit the Inline XBRL report
The Preparer uses the Report Writer or an external process to authenticate to and submit the Inline XBRL report to the Regulator .
6.1.4.11 Return a confirmation
The Regulator synchronously or asynchronously returns a message confirming the successful receipt of the Inline XBRL report, its conversion into XBRL and the validation of the resulting instance document.
6.1.5 Alternative course of events
There will be circumstances in which the validation of a resulting XBRL document either fails (it throws an error) or generates one or more warnings. This alternative course is not especially relevant to the Use Case associated with the production of an Inline XBRL document so is not covered here.
6.1.6 Post Conditions
There are no required steps here, although it is also possible to publish the Inline XBRL document on a corporate website, assuming that all relevant disclosure rules have been followed. The use of the Inline XBRL logo (a provisional one appears below)

on such a web site will allow, via the submission of the referring page (ie: the Inline XBRL page) to an externally hosted CGI script that runs the normative Stylesheet that converts the page into XBRL, the creation of an XBRL document. In other words it is possible to facilitate the instant conversion of a page into XBRL without any special infrastructure.
6.2 Use Case 2: Report Collection
A tax authority needs to collect financial statements from each company in the country. The tax laws oblige larger companies to provide more information and smaller companies to provide a short-form financial condition report. In every case, company reporting obligations in this regard are governed by the accounting standards in force. The information being sought is not captured in a form, but is a full financial statement where each company that files with the Regulator has significant freedom in terms of both the content and layout of the performance information being disclosed.
The regulator needs to be able to consume the information in XBRL form in order to be able to populate a business intelligence system that helps the Regulator in its risk and enforcement processes. However, whenever the Regulator needs to interact with an individual company, it is important that the rendered, human-readable version of the document can be used by both parties.
The main aspects of this use case are shown in Figure 3 . Notice that only the main steps are shown and that the key aspects of the use case (that relate to the way that the Inline XBRL is stored, transformed and rendered) are outlined in blue. The use case is described in detail below. Note that the numbers in the diagram relate to the steps set out in Section 6.2.4 .
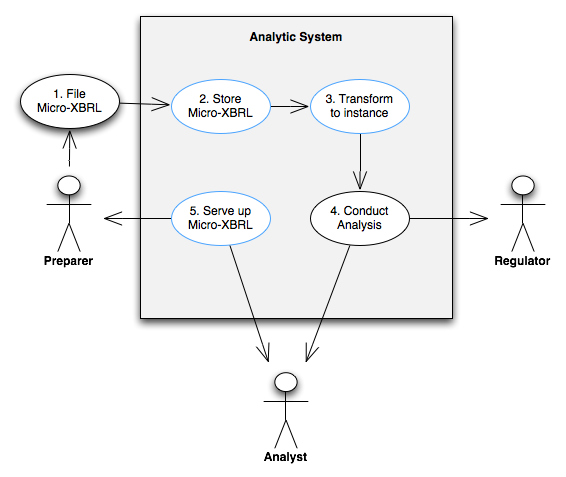
6.2.1 Summary
The Regulator publishes or references one or more authoritative XBRL taxonomies that model the accounting frameworks in use. The Regulator publishes a single XHTML CSS that must be used by every filer. This means that all reports, while they can be set out in very different ways, contain different types of information and relate to very different enterprises, will have the same look and feel. The fonts will be the same, the lines will be the same, the emphasis will be the same.
Preparers use these taxonomies to create Inline XBRL reports that are both a rendering of the financial statement and the XBRL report that the Regulator requires. Every file that is submitted will have the same look and feel, thanks to the single CSS.
The Analytic System receives and stores each Inline XBRL document, which will also have passed through a mechanism providing authentication and non-repudiation. At any time, the Analytic System can provide the original rendering of the report by retrieving the stored Inline XBRL (XHTML) document.
The Analytic System will also convert the Inline XBRL document into an XBRL instance document and validate it, both for XBRL conformance and (generally) against a system of business rules or data quality checks. Any anomalies will be directed to an Analyst or back to the Preparer as policy dictates.
The Analytic System will store the XBRL document and transfer it into the Regulator's business intelligence environment. In this environment the Analyst will be able to conduct a range of work such as looking for anomalies or business-rule failures. Often thnis will be done by comparing the data to prior year reports, other reports from different parts of the Regulator , peer group analyses as well as internal tolerances and rules of thumb.
In the event that the Analyst decides to review a filed report with the Preparer , the original (human readable) Inline XBRL document will generally be referenced.
These simple steps show the manner in which Inline XBRL can be used to make a business report human readable while also providing the structured (marked-up) information needed for a range of analyses. While the structured data is more likely to give rise to useful information than either unstructured data that is analysed by hand or summary structured data typed into a report based on unstructured data, it can, at any time, be reviewed in its original human-readable format.
6.2.2 Actors
The Regulator , in this case a tax authority, administers the law and provides the systems, infrastructure and environment to allow the periodic submission and analysis of business reports.
The Preparer is responsible for creating the financial report in Inline XBRL format. See Section 6.1 for details on the way this work is completed.
The Analytic System facilitates the storage, transformation and analysis of the business report submitted by the Preparer .
The Analyst works for the Regulator and uses the Analytic System to understand the performance and compliance with relevant laws by the Preparer .
6.2.4 Basic course of events
This use case describes the way that a tax authority can use Inline XBRL to gain the benefit of "interactive data" while at the same time avoiding the change management, cultural and legal issues associated with a move away from an authoritative "paper" financial statement or business report. Because Inline XBRL is just XHTML, preparers and their advisers remain comfortable with the content of the report: it looks exactly as the preparer intended. Since the report can be instantly converted into an XBRL instance document, the regulator can use a wide range of quantitative and heuristic analysis techniques, via modern business intelligence systems, to more efficiently and effectively conduct its investigations. If there is a need to discuss the filing with the preparer , the Inline XBRL/XHTML rendering of the report can be used so that everyone is working from the same page.
For those that are more comfortable with flow diagrams than use case diagrams, Figure 4 depicts this idea as a flow-chart:
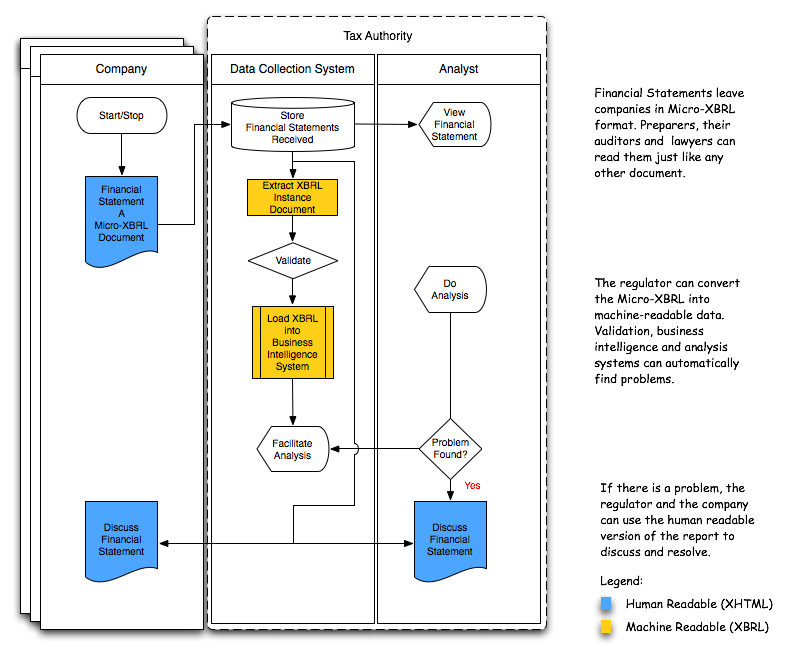
6.2.4.1 Submit the Financial Statement
Companies are generally required to provide a reconciliation of any differences between accounting and taxable profit. Many tax authorities require companies to provide financial statements to assist this process. Financial statements are not forms. Each one depicts a unique enterprise and each one is laid out in slightly different ways.
The Preparer creates an Inline XBRL document, authenticates to the tax authority's systems, and submits the Financial Statement.
See Section 6.1 for details about the way the Preparer carries out this exercise.
6.2.4.2 Submit the Financial Statement
Having passed authentication and non-repudiation steps, [ 2 ] the first step for the regulator's data collection system is to store the Inline XBRL in its original (ie: XHTML) format. Note that it will also be necessary to store, with the document (and for the same length of time as the document -- and in some cases, longer) any extension taxonomy that might have been created in support of the XBRL part of the report.
6.2.4.3 Transform the XHTML Inline XBRL document into an XBRL instance document.
The data collection system then uses the normative stylesheet to convert the Inline XBRL into an XBRL instance document.
Immediately after the transformation is completed, XBRL validation needs to be carried out. In the event of a problem associated with the conversion or the validation, a "red channel" process will usually take over to deal with the anomoly. This will be completed either manually or according to a predefined workflow.
However, assuming that there is no such hiccup, this structured version of the data can now be stored in a relational or XML-based database, ready for analysis to be carried out. In most environments a range of automated tests and preliminary analysis will be completed at this point.
6.2.4.4 Carry out Analysis
The Analyst working for the tax authority can now complete whatever periodic or ad-hoc analysis is warranted. There is an almost infinite number of forms that such analysis can take. Every environment will be different and every environment will use very different technology. The details are beyond the scope of this document. The result of the analysis is a determination as to whether or not the taxpayer company is in compliance with the relevant laws. In the usual course of events (when nothing anomolous is discovered) this use case ends here.
6.2.4.5 Conduct Investigation or Enquiry
In the event that the Analyst determines that inquiries need to be made of the taxpayer company then the Inline XBRL document that was submitted by the preparer can be retrieved, if necessary sent back to the taxpayer company and its advisors, and discussed until the issue is concluded. The point, of course, is that while the Analyst was assisted by the electronic data processing and business intelligence systems that can operate only with structured, machine readable data, this information was derived from the human-readable Inline XBRL document. Humans, when discussing the information, can use the human-readable version.
6.3 Use Case 3: Internal Consolidation
Disparate enterprises with heterogenous financial systems tend to have complex consolidation processes. Inline XBRL can assist business reporting by allowing disparate systems to use a standards-based (that is, XBRL) process. Human-readable Inline XBRL can be viewed by authorised personnel. Authorised systems can convert the same Inline XBRL into XBRL instance documents and use the data for consolidation or other relevant business processes.
This use case is depicted in Figure 5 . Note that the numbering refers to the steps set out in Section 6.3.4 .
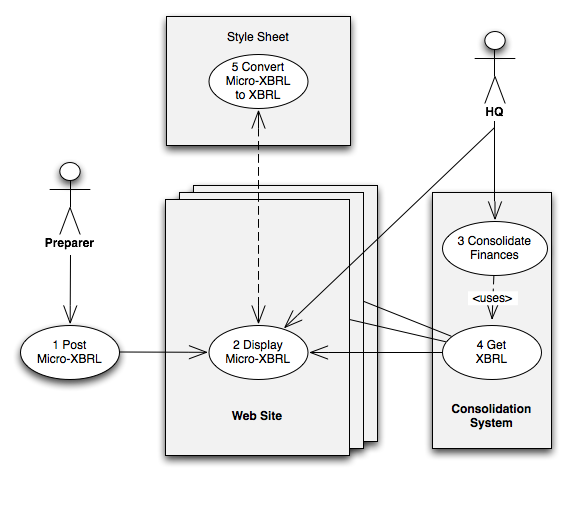
6.3.1 Summary
Management accountants within operating divisions or other relevant business lines have a variety of reporting obligations to Headquarters . To meet these obligations (they could be financial, key performance measures, tax or any other kind of business report) these business controllers use their respective report production applications to create Inline XBRL documents. These are posted to a suitable place within an enterprise intranet. Generally, these pages will only be accessible to authorised users.
Controllers and Managers at Headquarters and other authorised users within the Enterprise that need to understand business performance within a particular business line can navigate to the Inline XBRL page and read the report.
Authorised systems can also navigate to the Inline XBRL pages. Using a copy of the normative stylesheet (held centrally but within the trusted Enterprise network or via an embedded copy of the stylesheet) each application can convert each page into structured data: an XBRL instance document.
So long as the web pages are properly controlled (via a document management or other version control system) the Authorised systems can rely on and use this data for consolidation purposes.
This is a simple, transparent and restful way of managing data consolidation within the Enterprise.
6.3.2 Actors
The Preparer , in this case a management accountant or line controller , is responsible for the accurate and timely creation of financial and other business reports for the proper management of the organisation. Much of this work is conducted on behalf of Headquarters .
Staff at Headquarters are responsible for the collection, collation, consolidation and publication or filing of a range of business reports.
The Consolidation System facilitates the storage, transformation and analysis of the business reports submitted by the Preparer for consolidation by Headquarters .
6.3.3 Triggers
Reporting is triggered by timelines in policies set out by Headquarters which, in turn, are often shaped by legislation or commercial obligations defined by one or more external data collectors . The process of consuming the reports, whether in human readable or XBRL form, are generally also driven by these policies, but can also be very ad hoc.
6.3.4 Basic course of events
This use case describes the way that an enterprise can utilise Inline XBRL to simplify and standardise the consolidation of financial information and other similar business reports.
Large or geographically dispersed organisations tend to have complex and disparate consolidation systems. This use case describes a mechanism that allows such organisations to maintain their legacy systems (they need merely adapt their Report Writers to make them Inline XBRL capable or purchase relatively inexpensive software to convert their existing reports into Inline XBRL) and take advantage of the XBRL standard to simplify and make transparent the consolidation process.
6.3.4.1 Business Lines create reports and post to intranet
Let's say that each business line in a large enterprise has an obligation to provide a report containing headcount, new hires, departures and the spend on contract staff, as well as the total spend on wages and salaries every month. This is just an example; it could be any kind of report - statutory financial, a management report, a key performance report, a tax report.
The management accountant in each division creates a report in Inline XBRL and posts it to a defined place on the corporate intranet. Because the report is written in Inline XBRL it can be read (as an XHTML document) and, when necessary, converted into XBRL. While, presumably, the report will need to be available at a particular time each month, there would be nothing stopping the management accountant from updating it at any time if corrections are needed.
6.3.4.2 View the report
Authorised staff at Headquarters can examine the report the moment it has been posted.
6.3.4.3 Consolidate the data
A controller at Headquarters is responsible for consolidating the information across the enterprise. To do this, the controller needs to obtain a report from each operating unit, convert the report into XBRL and then use the consolidation system to pull the data together in line with the business rules that govern the process.
The first step is to initiate the consolidation exercise by instructing the consolidation system about the location of the Inline XBRL reports on the intranet.
The consolidation system can then start to obtain the information by following the steps set out in Section 6.3.4.4 . Once the XBRL instance documents have been acquired the consolidation system can draw together an Enterprise view of the report, defined in accordance with the business rules that govern that consolidation process. Those rules (and the actual consolidation) are outside of the scope of this use case, which is focussed merely on the transparent publication and acquisition of the relevant data.
6.3.4.4 Get the XBRL
The consolidation system acquires the XBRL by pointing a copy of the normative stylesheet (see Section 6.3.4.5 ) at each page of Inline XBRL that needs to be converted into an instance document.
The consolidation system can then store the resulting instance documents, if necessary converting them into a preferred local format, in order to complete the process set out in Section 6.3.4.3 .
6.3.4.5 Convert Inline XBRL into XBRL instance document
The normative stylesheet converts any given page of validly constructed Inline XBRL into an XBRL instance document. The stylesheet will need to run either from a trusted location within the enterprise or from inside the consolidation system .
6.4 Use Case 4: Comparative financial analysis
A common use of web-sites is comparative analysis of investor information relating to different companies. Key financial figures from comparable companies are displayed side by side on a web page. Using Inline XBRL, such sites could allow investors to download financial data directly from the webpage.
It is characteristic of this use case that the financial data presented on the web page will be used to produce multiple target XBRL instance documents.
6.5 Use Case 5: Extended corporate reporting
A large multi-national corporation makes a Corporation Tax filing in the United Kingdom. The size of their full financial statement and the extent of other supporting documentation required by the filing process (in particular, the free format tax computation) means that the filing is extremely unwieldy. As an Inline XBRL document, the filing can easily exceed 5 megabytes in size (the extreme limit for displaying HTML in browsers).
Similarly, an investor relations web site might make it easier to navigate a large financial report by breaking up the financial statement into multiple web pages.
For such web pages it is essential to be able to form the Inline XBRL document as a set of multiple documents, which may be hyperlinked together. Such multiple Inline XBRL documents are processed together to create a single, combined XBRL instance document.