1 Introduction
XBRL reports may include duplicate facts, that is, two or more facts that purport to provide the same piece of information. The reported values may be the same, or different. Where the values are different, this may or may not be indicative of a problem in the data. For example, the same information reported at differing levels of precision would yield different literal values, but is not indicative of an error in the data.
The XBRL v2.1 specification [XBRL 2.1] provides a definition of duplicate facts, but aside from specifying their impact on calculation checks, it does not prohibit or even discourage their use. Further, it does not make any distinction between different classes of duplicate facts based on the consistency of their values.
Whilst preparer guidance for the creation of XBRL reports usually discourages or prohibits the use of duplicate facts, best practice for the creation of Inline XBRL [Inline XBRL Specification] reports can legimately lead to duplicates. It is not uncommon for a report to include the same piece of information multiple times, and tagging guidance for Inline XBRL typically requires all such occurrences to be tagged. In some cases, such facts may be de-duplicated when the document is transformed into XBRL, but in other cases duplicate facts will be present in the resulting XBRL.
It is not uncommon for a report to contain the same piece of information multiple times, but stated to differing levels of precision. For example, a figure for revenue may be stated to the nearest million when referenced in text, but reported to the nearest thousand on the income statement. If both are tagged in an Inline XBRL document, it will result in duplicate facts which are not the same, but which should be consistent.
This document provides definitions for different classes of duplicates, clarifies the behaviour required of Inline XBRL processors with respect to duplicates, and provides recommendations for how duplicates should be handled in a filing system.
This document does not address consistency between fractional facts in
XBRL (i.e. facts for concepts using the xbrli:fractionItemType
data type. Such facts are not in common use, and are not supported by the
forthcoming Open Information Model specification. References to numeric facts
in ths in document refer to non-fractional numeric facts.
2 Classes of duplicates
This section provides definitions for different types of duplicates that may be encountered. All of these would be considered duplicates under the XBRL v2.1 definition of duplicate items. The figure below shows the relationship between the different classes of duplicates defined in this section.
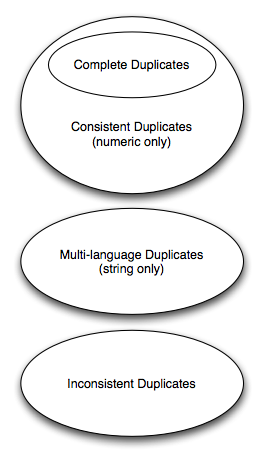
It is expected that the forthcoming Open Information Model specification will provide new, formal definitions of these classes of duplicates based on "aspects", rather than the syntactical definitions provided by the XBRL v2.1 specification. This working group note will be updated to reflect this.
2.1 Complete duplicates
Facts that fulfil the XBRL v2.1 definition of duplicate items, and which additionally:
- have equal values,
- in the case of numeric facts, have the same (inferred) value for decimals; and
- in the case of string facts, have the same effective
@xml:langvalue.
It should be noted that value equality refers to equality in the value space for the corresponding datatype, rather than requiring the same lexical representation. For example, "1.00" and "1.0" would be considered equal for a decimal value.
Despite the name, the definition above ignores custom attributes (i.e. those not defined by the XBRL specification) and also any footnotes attached to the facts. It is felt that in the majority of cases, this will yield desired behaviour under the recommendations below.
2.2 Consistent duplicates (numeric facts)
Facts that fulfil the XBRL v2.1 definition of duplicate items, and which additionally:
- are numeric facts; and
- have reported values and accuracies that are consistent with having been rounded from a single actual value.
Consistency of numeric values should be established by considering the interval represented by each reported fact, and ensuring that there is overlap between all intervals.
For example, given the reported values 2,500 (stated to -2 decimal places) and 2,000 (stated to -3 decimal places), we have the following intervals:
- 2,500 (-2 d.p.) => [2450, 2550]
- 2,000 (-3 d.p.) => [1500, 2500]
These two intervals overlap, and so are considered consistent (both facts are consistent with having been rounded from a value in the range [2450,2500]).
Technically, the interval represented by a reported value depends on the rounding method used to obtain it. For example, 2,000 (-3 d.p.) is only a valid rounding of 2,500 under certain rounding methods (e.g. "round half to even" or "bankers rounding"). If the value were rounded using the "round half away from zero" (or "commerical rounding") method, it would be 3,000 (-3 d.p.).
In order to avoid declaring values to be inconsistent in this edge case, the intervals used in establishing consistency should be inclusive (or "closed"), but with the constraint that values reported to the same accuracy must have the same reported value. In other words, 2,000 (-3 d.p.) is inconsistent with 3,000 (-3 d.p.) even though there is overlap between the closed intervals; such values would imply an actual value of 2,500, but rounded using different methods in different places in the report.
The approximation of using closed intervals only affects the outcome of the consistency check in the event that the exact value is also included in the report stated to infinite precision.
Numeric facts that are Complete Duplicates are also considered to be Consistent Duplicates.
2.3 Multi-language duplicates (string facts)
Facts that fulfil the XBRL v2.1 definition of duplicate items, and which additionally:
- are string facts; and
- have unique effective values of the
@xml:langattribute.
A string fact is a fact whose concept whose type is, or is derived from, xbrli:stringItemType or xbrli:normalizedStringItemType.
It should be noted that the effective language for a particular
element may be inherited from an @xml:lang attribute appearing on
an ancestor element.
Such duplicates may provide multi-language translations of a fact, but there is no automatable way to determine if the statements being made in different languages are equivalent. As such, this document treats these as a separate class of duplicates which implementations may choose to allow or prohibit depending on the need to support multi-language translations.
3 Issues with the XBRL v2.1 definition of duplicates
The XBRL v2.1 definition of duplicates is imperfect, as it relies on string
equality when comparing the content of elements in the context definition.
This means that QNames values that use different namespace prefixes to refer to
the same namespace would not be considered the same. In the general case, a
QName-aware comparison may not be possible, as it requires XML type information
which may not be available for the contents of <segment> and
<scenario> elements. For implementations that are following the
recommendations made in the Use of Dimensions Working Group Note [DIMENSIONS-USE-WGN], where the only content of these elements will be
XBRL Dimensions, a more robust QName-aware comparison can and should be used.
This anomaly will be removed with the switch to aspect-based definitions described above.
4 Duplicates in Inline XBRL: processor behaviour
The Inline XBRL specification [Inline XBRL Specification] allows, but does not require, processors to de-duplicate facts that are complete duplicates when transforming from Inline XBRL to XBRL. Consistent (but not complete) duplicates and inconsistent duplicates will not be be de-duplicated by an Inline XBRL processor, and so will always be included in the resulting XBRL.
As such, XBRL that is produced by an Inline XBRL processor may contain duplicates of all categories described above, with the exact handling of complete duplicates being processor-dependent. More details on the behaviour relating to duplicates can be found in the Inline XBRL Primer [Inline XBRL Primer].
5 Issues with duplicates
The presence of duplicates in an XBRL document can create problems for processing, storage and analysis of the data.
5.1 Calculation consistency checking
The XBRL v2.1 specification provides the "summation-item" arcrole that can be used to define simple calculation relationships between concepts that will be checked against corresponding facts in an XBRL report. Such calculation checks are only performed if neither the total, nor any of the contributing items, have duplicates; the presence of any duplicates effectively disables calculation checks.
A further issue is that the XBRL v2.1 specification requires that calculations are checked to be correct to the declared precision of the total (summation item). This can be problematic if the total item is reported multiple times at different precisions. For example, the item may be presented on face financial statements at a lower precision to how it is presented in a detailed note. If the contributing items are also stated at the lower precision, the calculation check may only pass when the lower precision version of the total fact is used.
Unfortunately, there is no good solution to this problem: including both facts would disable the check, and including only the lower precision fact loses information, and may have knock-on effects if that fact is itself a contributing item to another calculation check. Implementers should be aware of the limitation of calculation checks in this regard.
The facts in the example below represent a consistent calculation.
"millions"
Item1: 2.6 (reported as 2600000 decimals = -5)
Item2: 3.1 (reported as 3100000 decimals = -5)
-----
Total: 5.7 (reported as 5700000 decimals = -5)
If the total item were also reported elsewhere to a greater a precision, for example as 5,722,000 (decimals = -3), this creates a problem for the calculation. Including both versions of the facts (as consistent duplicates) would disable the calculation check. Including only the most precise (5,722,000) would cause the calculation to be checked to a precision of decimals = -3, and thus fail. Including only the less precise fact would represent a loss of information.
5.1.1 Calculation consistency checks in Inline XBRL
As de-duplication of facts in an Inline XBRL document is, to some extent, implementation dependent, this in turn means that the results of checking of "summation-item" relationships against XBRL produced via an Inline XBRL transform are implementation dependent.
Even where an Inline XBRL processor performs de-duplication to the maximum extent allowed by the specification, the use of Inline XBRL may still yield consistent or inconsistent duplicates in the resulting XBRL. The presence of either would effectively disable any calculation checks performed on these facts.
If summation-item checks are being used in combination with Inline XBRL, it is recommended that a separate de-duplication process is used prior to applying such checks.
5.2 Formula processing
Variables in formula rules will "bind" to each occurrence of a duplicate fact, causing the rules to evaluate for each combination of the duplicate facts involved in the rule. This may have an adverse effect on performance, and may cause repetition of any detected errors.
For example, take a trivial rule that checks the equality of two facts, A and B:
A == B
If A and B are both reported twice, as duplicates A1 and A2, and B1 and B2, then the rule will be evaluated four times, once for each combination of facts:
A1 == B1
A1 == B2
A2 == B1
A2 == B2
Clearly, if more duplicate facts are involved, this has the potential to lead to a very large number of unnecessary evaluations, and a large number of repeated results.
5.3 Storage
The presence of duplicates adds significant complexity to the storage of facts in systems such as databases as, in general, individual facts can no longer be uniquely identified by the combination of their aspects (i.e. the combination of concept, period, entity, dimensions, etc.)
If Inconsistent Duplicates are rejected, and Complete Duplicates are de-duplicated, then any remaining Consistent and Multi-Language Duplicates can be uniquely identified provided that precision and language are treated as aspects. However, the possibility that a given query on the storage system may result in multiple numeric facts differentiated only by their precision is likely to add complexity to any further processing.
6 Duplicates in XBRL: Recommended approach
Where Inline XBRL is not used, it is typically possible to avoid the issues relating to duplicates by simply using filing rules to prohibit the inclusion of any duplicates at all:
- Complete duplicates are entirely redundant, and can be prohibited without loss of information.
- Consistent duplicates can be avoided by requiring preparers to exclude all but the most precise fact. As there is no mechanism to tie the different occurrences of the fact to the presentation view in which they should be considered, there is little value in including them.
- The legitimacy of multi-language duplicates will depend on the filing system. Filing rules should either prohibit their use, or give clear guidance on how and when they should be used.
- Inconsistent duplicates should be prohibited.
7 Duplicates in Inline XBRL
Inline XBRL introduces "legitimate" reasons for the inclusion of duplicates. In many reporting scenarios, it is common for the same piece of information to be presented multiple times in a human-readable presentation of the report. For example, the figure for revenue may appear on the main financial statements as well as in a note giving a detailed breakdown.
It is generally considered best practice to tag all figures in an Inline XBRL document, as this makes it easier to spot untagged figures, and it makes it possible for consumers to navigate effectively between XBRL facts and the locations in which they were reported in the presentation.
7.1 Complete duplicates in Inline XBRL
As described above, whether multiple tagging of complete duplicates in Inline XBRL results in duplicates in the resulting XBRL is processor-dependent.
7.2 Consistent duplicates in Inline XBRL
It is possible that the same information is presented to a different precision in different places. In this case, even using an Inline XBRL processor that de-duplicates to the maximum extent allowed by the specification, consistent duplicates will be present in the resulting XBRL.
7.3 Inconsistent duplicates in Inline XBRL
It is also possible that the same fact is reported with different values that are not consistent, giving inconsistent duplicates in the resulting XBRL. In the case of numeric facts, this is almost certainly indicative of an error, either in the underlying presentation or in the way that it has been tagged.
In the case of non-numeric facts, it is possible that inconsistent duplicates would result from strings that would be considered equivalent from a business perspective. For example, when reporting the name of a director, the forename might be abbreviated in one place but not another (e.g. "J. Smith" vs "John Smith"). Similarly, differences in capitalisation and spacing would result in duplicates that are technically inconsistent, but which might be considered acceptable from a business perspective.
Clearly, the ideal solution would be to have all such facts presented in exactly the same manner, so that all occurrences can be tagged without introducing inconsistent duplicates. In practice, the document production workflow may make this impractical, and in this case, the benefits of completeness of tagging may be outweighed by the complexities created by having inconsistent duplicates in the document.
7.4 Recommended approach
The following recommendations are made for dealing with duplicates in Inline XBRL:
- Require all occurrences of a numeric fact to be tagged in Inline XBRL
- Allow additional occurences of non-numeric facts to be left untagged if they would result in an inconsistent duplicate
- Reject filings that contain inconsistent duplicates
- When performing summation-item, XBRL Formula, or other processing on XBRL obtained from Inline XBRL, de-duplicate all complete duplicates, and remove all consistent duplicates except the fact that is stated to the highest accuracy
If completeness of tagging is considered critical, then an alternative approach would be to only reject numeric, inconsistent duplicates, and accept that inconsistent non-numeric duplicates may be present in the XBRL.