

What is iXBRL?
iXBRL, or Inline XBRL, is an open standard that enables a single document to provide both human-readable and structured, machine-readable data. iXBRL is used by millions of companies around the world to prepare financial statements in a format that provides the structured data that regulators and analysts require, whilst allowing preparers to retain full control over the layout and presentation of their report.
iXBRL takes the HTML standard that is used to power the world’s web pages, and embeds extra “tags” into it that give meaning to the figures and statements in a format that can be understood by a computer.
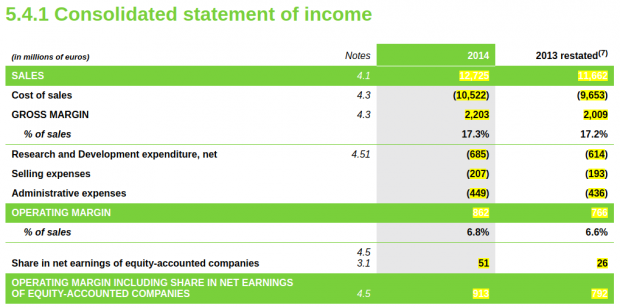
The sample above shows an income statement that has been tagged using iXBRL. Click on the image to explore this statement using an interactive iXBRL viewer. The sample shows how structured data can be included in an iXBRL report whilst retaining full control over the appearance of the statement (the sample is based on the income statement on page 240 of this PDF report).
Exploring the tags in the sample above will reveal the names of the “concepts” against which the figures are tagged (e.g. “ifrs:Revenue”). These are drawn from a dictionary of concepts, known as a taxonomy. In this case, the sample is an IFRS report and so it has been tagged using the IFRS taxonomy, published by the IFRS Foundation.
Report presentation
As noted above, iXBRL allows preparers to retain full control over the presentation of their report. This includes the use of graphics and photos, as demonstrated in Global Legal Entity Identifier Foundation’s 2018 Annual Report:

Click on the image to explore the full sample in the interactive viewer.
Entity-specific disclosures
Different reporting entities (whether they are companies, organisations or government agencies) prepare different reports, in accordance with relevant accounting standards. Even within peer groups, Company A’s financial statements will be different to Company B’s, according to their communication needs. iXBRL provides a number of different mechanisms to allow this diversity, reflecting the variations that have always been present in financial statements.
In the example below, an entity-specific taxonomy, known as an extension taxonomy, has been used to tag the specific operating segments included in the report.
.
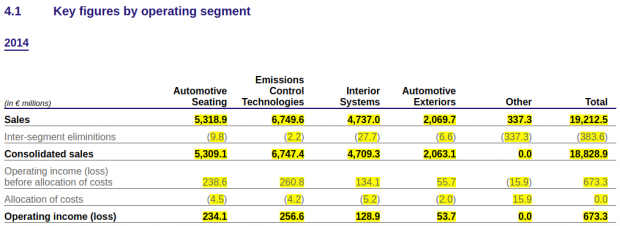
Click on the image to explore the full sample using the interactive viewer. This sample also demonstrates how text disclosures can be tagged as well as the numerical figures.
This is not the only way in which variations across different financial statements can be managed, and in early 2017, XBRL International will make some recommendations about the most appropriate ways that this can be managed.
Beyond financial reports
The use of iXBRL is not limited to company financial reports. The benefits of combining human-readable and machine-readable information can assist many domains in making the transition away from inefficient manual processes. The sample below shows a corporate action document, disclosing a dividend payment.

Clicking on the image will allow you to explore the full sample. You can clear more about the efforts to modernise corporate actions reporting on the XBRL US website.
An open standard
The final sample is shown in a different, more fully-featured iXBRL viewer, made available by the US Securities and Exchange Commission (SEC). Consumers have a free choice of tools for consuming and analysing iXBRL reports, a key benefit of using an open standard.
The SEC’s viewer enables some sophisticated searches to be performed, for example, using information in the taxonomy to search a company’s quarterly return to find disclosures relating to a particular accounting standard change, but even this is barely scratching the surface of what is possible using iXBRL data.
Working with iXBRL data is not just about exploring reports using a web browser. The samples linked to above are valid iXBRL reports that can be loaded into any compliant processor, and the data within them can be consumed by analytics engines, loaded into databases for querying, or processed into new reports. All this can be done whilst retaining links back to the information as it was originally reported and presented.
Who uses iXBRL?
iXBRL is in use around the world:
- In the US, all companies must file iXBRL to the SEC, such as this 10-Q filing from Delta.
- In the UK, over two million companies file iXBRL each year to HMRC, the UK tax authority, and to Companies House, the business registrar.
- In Japan, over 9000 listed companies and investment funds use iXBRL to submit financial statements to the Japan Financial Services Agency (JFSA)
- In Denmark, the Danish Business Registrar has collected over 100,000 iXBRL formatted financial statements for the purposes of registration and market information.
- ESMA, the European Securities and Markets Authority obliges public companies that report in IFRS (the vast majority of EU financial statements) to use Inline XBRL as the standard behind ESEF, for mandatory IFRS based Annual Financial Statement filings of all public companies across Europe, for reporting periods commencing on or after 1 January 2021. For a a range of actual filings associated with the ESEF mandate, see our sub-site, https://filings.xbrl.org.
What about Sustainability Data?
Starting in 2023 and accelerating quickly across the world a wide range of securities regulators are obliging the use of XBRL in statutory sustainability disclosures. Early voluntary filings are beginning to become available. For example, here is an integrated financial statement and sustainability report prepared by Aviva, a UK insurance company. And here is an example set of analytics based on that single report.

Specifications
XBRL technical specifications can be found on our XBRL Specification sub-site.




