
Stop Feeding AI Junk – How XBRL-MCP Can Deliver Clean Business Data


Janis Steinmann
This guest opinion piece is from Janis Steinman. Janis is the Head of XBRL at Lucanet, a leading software house that provides CFO Solution Platforms to enterprises across the world. He is also the Chair of XBRL International’s Best Practices Board. Janis has collaborated in developing this article with José Antonio Huizar Moreno, the CEO of 2H, a software house in Mexico City that specialises in XBRL solutions for the Latin American market. José is a member of the XBRL Best Practices Board.

José Antonio Huizar Moreno
Like many AI initiatives, these techniques are new, and somewhat experimental, so care should be taken in your own efforts in this area.
XBRL has successfully standardized financial reporting by creating structured, machine-readable data that preserves semantic meaning and enables automated processing. However, accessing and analyzing this data has traditionally required specialized technical knowledge, creating significant barriers between financial professionals and the insights they need. Extracting comparative metrics, calculating ratios, or performing trend analysis typically involves downloading files, navigating complex software interfaces, and spending considerable time on data manipulation before meaningful analysis can begin.
Recent developments in artificial intelligence and database technology have introduced a fundamentally different approach to XBRL analysis. Model Context Protocol [MCP] servers, a new standard for enabling AI applications to communicate with external data sources, now make it possible to analyze XBRL data through natural language conversation. Instead of wrestling with technical tools, financial professionals can ask questions like “Compare the liquidity ratios of these companies over the past year” and receive immediate, accurate responses complete with calculations and visualizations.
José Antonio Huizar Moreno, a member of XBRL International’s Best Practice Board, has created a technical tutorial to outline how this new technology can be used in the context of XBRL analysis. You can access the tutorial here.
Following is a quick description of the approach, the usage and the consequences for a less tech-savvy audience.
Handling XBRL Complexity – A Different Approach
Recent developments in artificial intelligence and database technology have enabled a new approach using the MCP standard where financial professionals can analyze XBRL data through natural language conversation. Instead of navigating complex software interfaces, analysts can ask questions like “Compare [Company A]’s cash flow trends with [Company B] over the past four quarters” and receive immediate responses with supporting data and visualizations.
XBRL’s power lies in its dimensional structure, where each fact carries context including the reporting entity, time period, measurement unit, and additional dimensional information. Traditional analysis tools often struggle with this complexity, requiring users to manually navigate hierarchies and filter contexts.
The conversational approach preserves XBRL’s dimensional richness while making it accessible through natural language. When you ask about performance in a specific business segment, the system automatically applies appropriate dimensional filters. For year-over-year comparisons, it correctly aligns time periods across different reporting cycles.
The Technical Magic, Simplified
The system works through four integrated layers that work seamlessly together: The Data Storage Layer utilizes a modern database system for easy document storage and SQL reliability, while the API Layer provides clean, fast access to financial data, handling complex queries, pagination, and filtering. The Communication Layer, with the MCP server, acts as a translator between the database and AI tools, and the Analysis Layer offers a natural language interface for simplified financial analysis.
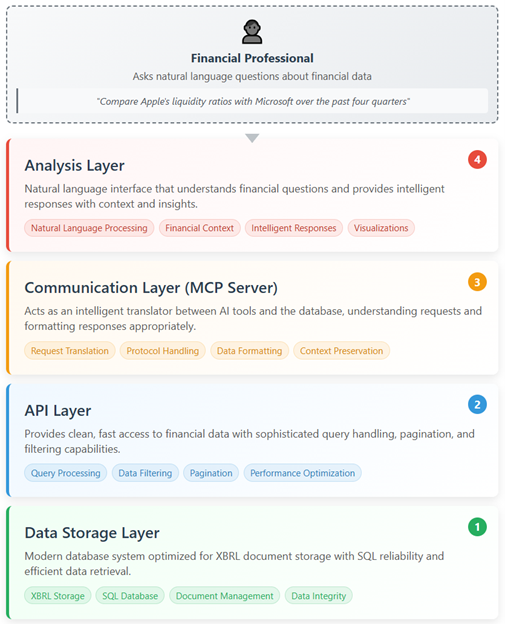
MCP servers work as intelligent translators that enable AI assistants to access and work with external information sources. Think of them as specialized assistants that sit between the AI and various databases or services, understanding requests from the AI and knowing how to retrieve the appropriate information from external systems. When you ask an AI assistant a question that requires current data or specific calculations, the AI recognizes that it needs outside help and sends a request to the relevant MCP server. The server then handles all the technical work of finding, processing, and organizing the requested information before sending it back to the AI in a format it can understand and use in its response to you.
For XBRL financial analysis, this process works seamlessly in the background during normal conversation. When you ask an AI assistant to analyze a company’s financial ratios, the AI identifies this as a request requiring financial data and contacts the XBRL-focused MCP server. The server accesses the financial database, locates the relevant company information, performs the necessary calculations, and returns the results along with appropriate context about what the numbers mean. The AI then combines this information with its knowledge of financial analysis to provide you with a comprehensive response that includes both the specific calculations you requested and broader business insights.
Solving the Context Window Challenge
One of the most significant practical advantages of the MCP server approach over AI-based consumption of unstructured PDF or HTML reports lies in how it addresses the fundamental context window limitations of large language models. When financial professionals attempt to analyze company filings by uploading entire PDF annual reports or (HTML formatted) US SEC 10-K documents, they quickly encounter a critical bottleneck: these documents often contain hundreds of pages of text that far exceed what any AI system can process in a single conversation.
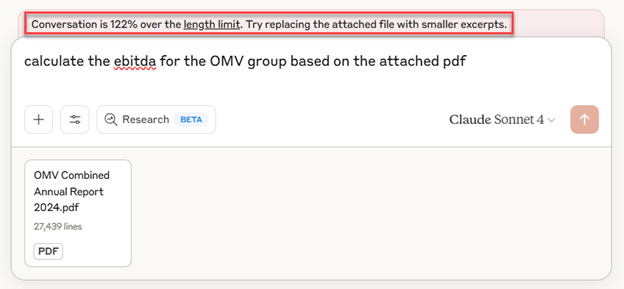
A typical 10-K filing lodged with the US SEC’s EDGAR system can contain 200-300 pages of dense financial information, regulatory disclosures, risk factors, and narrative explanations. When converted to text, this represents hundreds of thousands of tokens—well beyond the context window of even the most advanced language models. The result is that analysts must either work with truncated documents, losing crucial information, or break their analysis into multiple fragmented conversations, losing the coherent analytical thread.
The MCP server approach fundamentally solves this problem by transforming the interaction model. Instead of trying to feed entire documents into the AI’s context window, the system maintains the complete XBRL dataset in an external database and retrieves only the specific information needed to answer each question. When you ask “Show me the profit and loss of Hays”, the MCP server extracts precisely the relevant financial facts from the structured data, performs the calculations, and returns a focused response containing only the essential information.
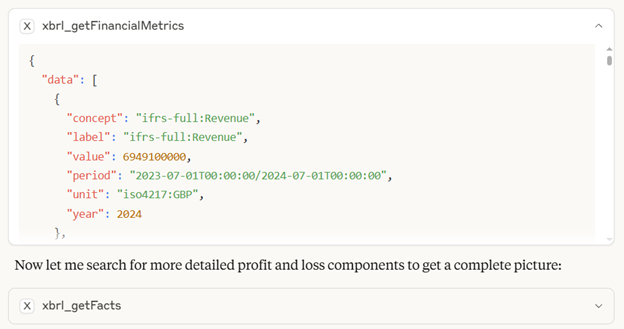
This selective retrieval means that complex multi-company analyses that would be impossible with PDF documents become straightforward conversations. You can compare metrics across dozens of companies, analyze trends over multiple years, and perform sophisticated financial modeling—all within a single coherent analytical session. The AI maintains full context of your analytical objectives while the MCP server handles the heavy lifting of data extraction and computation.
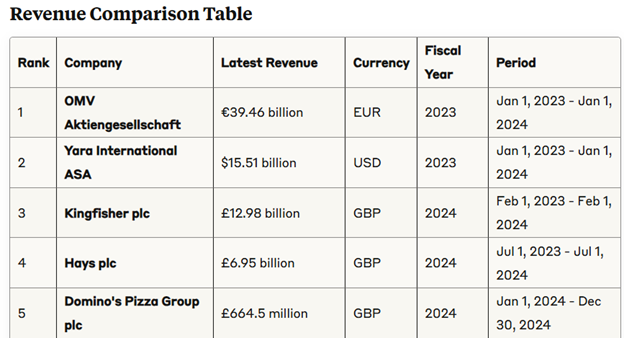
Traceability and Source Attribution
The MCP server approach provides a significant advantage in maintaining clear audit trails and source attribution that is lost when working with PDF documents. When financial professionals analyze traditional PDF filings, the AI’s responses are based on unstructured text that has been processed and synthesized, making it close to impossible to verify exactly which specific data points, calculations, or disclosures informed particular conclusions. This opacity creates challenges for regulatory compliance, audit requirements, and professional due diligence where source verification is essential. For example:

With structured XBRL data accessed through MCP servers, every piece of information returned carries precise metadata about its origin. When the system calculates a debt-to-equity ratio, it can specify exactly which balance sheet line items were used, from which reporting period, and reference the specific XBRL tags and contexts that define those values. This granular attribution extends beyond simple data retrieval to complex calculations and comparative analyses. For example:

The structured nature of XBRL data also enables automated citation and referencing. Each analytical statement can be directly linked back to the source filing, specific line items, and even the underlying accounting standards that define how those items should be interpreted. This creates a clear chain of evidence from raw regulatory filings through analytical processing to final insights, supporting both internal quality control processes and external audit requirements.
This transparency becomes particularly valuable when AI reasoning reveals unexpected patterns or anomalies. Rather than having to manually search through hundreds of pages of PDF documents to understand why certain conclusions were reached, analysts can immediately trace the logical path from source data through calculations to insights. The system can show exactly which financial statement items contributed to a particular ratio, how those items were defined in the XBRL taxonomy, and what contextual factors influenced the analysis.
For regulatory compliance and professional standards, this enhanced traceability means that analytical work can be more easily documented, reviewed, and validated. Audit teams can efficiently verify that analyses are based on the correct source data, that calculations follow appropriate methodologies, and that conclusions are properly supported by the underlying financial information. This level of documentation and verification would be extremely time-consuming to achieve when working with unstructured PDF content.
Beyond Traditional Analysis Tools
The approach can simplify comparative analysis by automatically calculating financial metrics like ratios, growth rates, and period-over-period trends. It generates financial statements, computes key ratios such as return on assets and debt-to-equity, and assesses financial health indicators with context-aware insights. By understanding XBRL’s multidimensional data structure, it eliminates the need for complex database queries, allowing users to extract information effortlessly through natural language questions like, “What was [entity]’s revenue in Q4 2024?”
The AI provides context-aware insights, retrieving numbers and offering explanations, and identifying patterns that might not be obvious from raw data. Automated visualization creates charts and graphs through simple requests, with the system selecting appropriate visualization types based on the data and analysis being performed. Integrated analysis lets you combine multiple analytical techniques in a single conversation, enabling you to calculate ratios, compare companies, analyze trends, and assess risks without juggling multiple tools.
This approach represents a shift in how financial professionals interact with structured data, removing technical barriers and leveraging the rich information in XBRL filings. For analysts, it offers direct access to insights without waiting for IT support or struggling with complex software interfaces. Researchers can explore large datasets and test hypotheses through conversational interaction. Auditors benefit from quick verification of figures and automated calculation of key ratios for risk assessment. Investors can easily compare companies and identify investment opportunities or red flags.





