
This document is a public draft. Readers are invited to submit comments to the Implementation Guidance Task Force.
- 1 Abstract
- 2 Why use XBRL formula rules for validation rules?
- 3 Scope
- 4 Creating XBRL formula rules
- 4.1 Simple logical expression
- 4.2 Rules involving multiple concepts
- 4.3 Mandatory concepts
- 4.4 Date comparison with user friendly message
- 4.5 Explicit dimensional aggregation
- 4.6 Aggregation across typed dimension records
- 4.7 Facts spanning multiple periods
- 4.8 Rules where all facts may not be reported
- 4.9 Combining filters and defining rule severity
- 4.10 Conditional rule execution (preconditions)
- 4.11 Rules using external values (parameters)
- 4.12 Defining common values across rules as parameters
- 4.13 Facts with different aspects
- 4.14 Reusing relationship trees
- 4.15 Dimensional aggregration using dimensional relationships
- 4.16 Using an XBRL function library
1 Abstract
XBRL formula rules is a standardised mechanism for defining validation rules for XBRL reports. This tutorial introduces the features available in XBRL formula rules, and explains how common types of validation rule can be implemented.
This guidance is primarily targeted at taxonomy authors seeking to author validation rules.
2 Why use XBRL formula rules for validation rules?
Validation rules can increase the data quality and accuracy of XBRL reports. Validation rules are backed by requirements from the underlying business domain or driven by the technical requirements of the filing system.
XBRL formula rules is a standardised mechanism for embedding validation rules in an XBRL taxonomy. This allows a collector to publish a taxonomy that contains all of the validation constraints that reports are required to comply with, alongside other metadata such as labels and documentation. Conformant XBRL software will automatically apply the formula rules as part of validation, making it easy for preparers to check reports prior to submission. By publishing the rules in an executable format such as XBRL formula rules, collectors avoid the possibility of mis-interpretation of the rules by preparers and third-party software developers.
XBRL formula rules provides built-in features to work seamlessly with XBRL data, addressing XBRL-specific requirements such as selecting facts based on XBRL aspects, querying taxonomy relationships, and traversing XBRL dimensional models.
3 Scope
This tutorial explains how different types of business rules can be implemented as XBRL formula rules. The tutorial does not attempt to address all features of the XBRL Formula specification1 but covers those required to address the most common types of validation rules. This tutorial only covers the use of XBRL formula rules for validation2 and does not address their use for the production of new XBRL reports.
4 Creating XBRL formula rules
There are three components common to most XBRL formula rules:
- The Rule Name
- An identifier for the rule that is used to provide an error code if it fails.
- The Test Expression
- The logic that is evaluated in order to determine the outcome of the rule. This is the core of a rule. The test expression uses the XPath 2 expression language.
- Variables
- Inputs to the test expression. For example, if the test expression performs an aggregation, variables are used to select the total and contributing facts from the XBRL report.
XBRL formula rules may also have other optional components, including preconditions, severities and parameters. These are introduced in later examples.
The examples in this tutorial use the "XF" text-based formula language prototype. This provides exactly the same functionality as the XML-based syntax defined in the XBRL standard but is more concise and easier to read. Although this language is not yet the subject of a formal specification, it is the easiest way to demonstrate XBRL formula rules functionality.
4.1 Simple logical expression
To demonstrate basic XBRL formula rules functionality, consider a simple logical condition such as a requirement that reported Revenue is not negative.
The XF syntax for such a rule is shown below.
namespace eg = "http://example.com/taxonomy"; assertion NonNegativeRevenue { variable $v1 { concept-name eg:Revenue; }; test { $v1 ge 0 }; };
The "assertion" keyword is used to define the rule, and provides the rule name, "NonNegativeRevenue".
When creating a formula rule, we first select the facts that we want to apply a test to. This is done using variables. In this case, a single variable "v1" is defined. The "concept-name" line (highlighted) defines a "Concept Filter" which selects facts reported using the "eg:Revenue" concept.
The test expression "$v1 ge 0" will check that the facts assigned to the variable "v1" have a value that is greater than or equal to zero.
The namespace declaration line (highlighted) binds the prefix "eg" to the namespace "http://example.com/taxonomy" for use in QNames in the rest of the XF file.
The rule will be evaluated for each time that the variable matches (or "binds to") the XBRL report. This means that the test expression will be evaluated for each occurrence of a fact using the concept "Revenue". This may include facts reported with different periods, units or taxonomy-defined dimensions. The characteristics (concept, period, unit, taxonomy-defined dimension and entity) used to uniquely identify a fact are known as "Aspects".
Figure 1 shows the results that would be expected from a hypothetical XBRL report containing six "revenue" facts with different aspects.
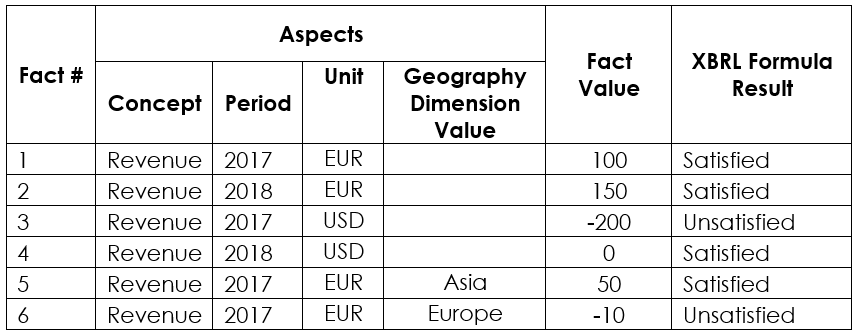 Figure 1: Evaluation results for facts with different aspects
Figure 1: Evaluation results for facts with different aspectsIf no "Revenue" fact is present in the XBRL report then this rule will not be evaluated. Section 4.8 demonstrates how to define a rule that raises an error if a required fact is not reported.
4.2 Rules involving multiple concepts
Business rules often require validation involving multiple facts from an XBRL report.
For example, validating the fundamental accounting rule: "Assets = Equities + Liabilities" involves comparing three facts.
namespace eg = "http://example.com/taxonomy"; assertion BalanceSheetEquality { variable $v1 { concept-name eg:Assets; }; variable $v2 { concept-name eg:Equities; }; variable $v3 { concept-name eg:Liabilities; }; test {$v1 eq $v2 + $v3}; };
In this example, we define three variables (v1, v2, v3) using concept filters to select the facts that we are interested in. The test expression "$v1 eq $v2 + $v3" then performs the required validation on the selected facts.
In the simple case where the XBRL Report contains just a single fact for each concept, in the same period and with the same units and taxonomy-defined dimension value, the rule will be evaluated just once.
It is quite possible that the XBRL report will contain more than one fact for each concept. For example, a report may include facts for multiple reporting periods. In this case it is important that the facts being compared pertain to the same period. More generally, we want to ensure that facts sharing the same aspect values are grouped together for evaluation.
Fortunately, this grouping (known as "Implicit Filtering") is a built-in feature of XBRL formula rule, and is the default for rules written in XF. This ensures that any aspects that are not specified explicitly by the filters (known as "uncovered aspects") are matched to form a logical set. In this example, the only aspect that is explicitly filtered is the concept, so implicit filtering ensures that other aspects i.e. period, unit, entity and taxonomy-defined dimension are the same within each set of facts being evaluated. Figure 2 shows how the facts in an XBRL report including multiple periods, units and taxonomy-defined dimension would be grouped for evaluation.
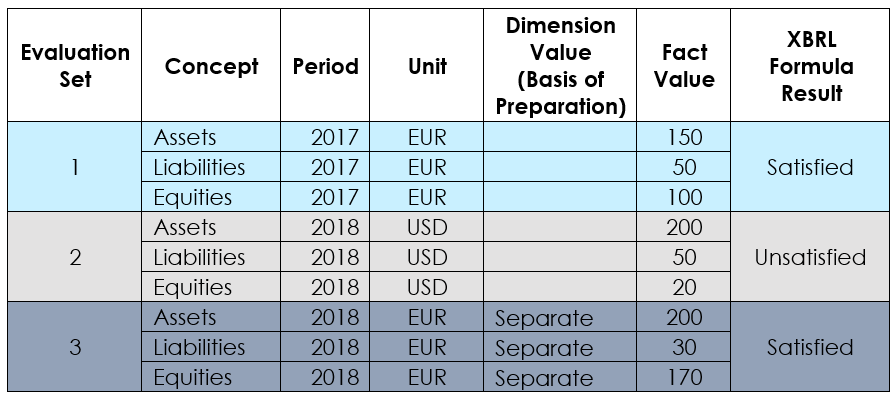 Figure 2: Evaluation sets formed by applying implicit filtering
Figure 2: Evaluation sets formed by applying implicit filteringImplicit filtering is a powerful feature of XBRL formula rule as it allows a single rule to be applied to multiple reporting scenarios.
It should be noted that when comparing fact values, XBRL formula rules do not take into account the stated accuracy of the fact. Rule authors should consider what tolerance, if any, should be permitted to allow for rounded values.
4.3 Mandatory concepts
One of the common types of business rule found in filing programmes is ensuring that a mandatory concept is reported. In XBRL formula rule, a mandatory concept check is generally implemented as an "Existence Assertion".
The following example demonstrates how the business rule "Current Period End Date must be reported" would be implemented using an Existence Assertion
namespace eg = "http://example.com/taxonomy"; assertion MandatoryCurrentPeriodEndDate { variable $v1 { concept-name eg:CurrentPeriodEndDate; }; evaluation-count {.}; };
In this case, a single variable "v1" is defined and is constrained to match facts with a concept of "eg:CurrentPeriodEndDate".
In an Existence Assertion, we use the special test expression, "evaluation-count". Rather than evaluating once each time the defined variables bind, it performs a count of the number of times that the variables bind.
The expression "evaluation-count {.}" will ensure that the variables bind at least once. In this case, this ensures that the variable $v1 matches a fact using the eg:CurrentPeriodEndDate concept at least once.
This rule will have one of the two possible results
- Satisfied - If the concept "Current Period End Date" is reported at least once in the XBRL report.
- Unsatisfied - If the concept "Current Period End Date" is NOT reported in the XBRL report.
The "." item in the evaluation-count expression provides the number of times that the variables in the rule bind.
The expression above is effectively a short-hand for:
evaluation-count { . gt 0 }
In other words, testing that the evaluation count is greater than zero.
It is possible to write other tests. For example, if we want to ensure that there is exactly one fact in the XBRL Report using the eg:CurrentPeriodEndDate concept, we can use the following expression:
evaluation-count { . eq 1 }
This ensures that the evaluation count is exactly equal to one, meaning that the variable "v1" bound exactly once.
4.4 Date comparison with user friendly message
In this example, we want to ensure that the date reported for "Current Period End Date" is later than the date reported for "Current Period Start Date" and provide a useful message to the user if this is not the case.
namespace eg = "http://example.com/taxonomy"; assertion DocumentDateCheck { unsatisfied-message (en) "Current Period Start Date must be before Current Period End Date"; unsatisfied-message (fr) "La date de début de la période en cours doit être avant la date de fin de la période en cours"; variable $v1 { concept-name eg:CurrentPeriodEndDate; }; variable $v2 { concept-name eg:CurrentPeriodStartDate; }; test { $v1 gt $v2 }; };
Here in this rule, two variables (v1 and v2) are constrained by date concepts and the test expression checks the required validation.
Additionally, the rule also defines two "unsatisfied messages" (highlighted). In the event of an evaluation failure, the message will be displayed to the user in order to help understand the nature of the problem. As can be seen, the message has been provided in two languages: English ("en") and French ("fr"), allowing a formula processor to display a localised error message. Any number of such translations can be provided.
XBRL formula rules also has a provision to define "satisfied messages" which will be available to users on successful evaluation of a validation rule.
4.5 Explicit dimensional aggregation
Business reports that make use of XBRL dimensions often require the validation of aggregate values across a dimensional breakdown (domain members).
Figure 3 is an extract of a "Property, Plant and Equipment" (PPE) disclosure, in which the Asset classes are modelled as XBRL Dimensions and the disclosure items are defined as concepts. This example explains how an XBRL formula rule can be defined to validate aggregation across the asset classes, ensuring that for each row, the total in the right hand column is equal to the sum of the other items in the row.
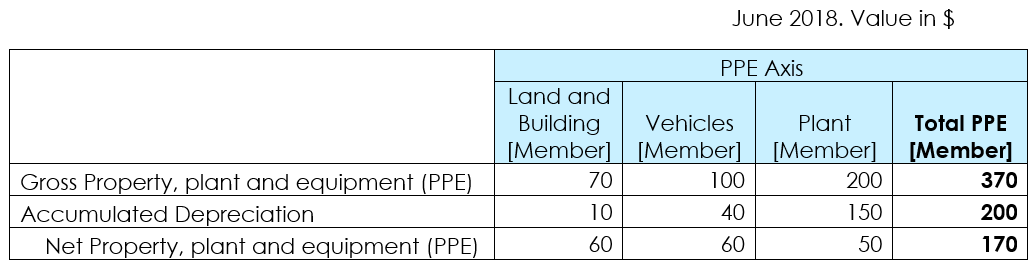 Figure 3: Sample Property, Plant and Equipment disclosure
Figure 3: Sample Property, Plant and Equipment disclosurenamespace eg = "http://example.com/taxonomy"; assertion PPETotal { variable $AssetClass1 { explicit-dimension eg:PPEAxis member eg:LandAndBuildingMember; }; variable $AssetClass2 { explicit-dimension eg:PPEAxis member eg:VehiclesMember; }; variable $AssetClass3 { explicit-dimension eg:PPEAxis member eg:PlantMember; }; variable $Total { explicit-dimension eg:PPEAxis member eg:PPETotalMember; }; test {$Total eq $AssetClass1 + $AssetClass2 +$AssetClass3}; };
In this rule, an "explicit dimension" filter is defined for each variable (highlighted for "AssetClass1"). The explicit dimension filter specifies the Dimension and Domain Member enabling the selection of fact(s) pertaining to the specific dimensional aspect.
For example, the fact(s) filtered for variable "AssetClass1" will have "eg:PPEAxis" as its dimension with the value (domain member) as "eg:LandAndBuildingMember".
The test expression aggregates the value across the PPE dimensional breakdown (Land, Vehicles and Plant) and compares it with the total PPE value.
Note that as we have not specified a concept filter, this rule will apply to all facts with the specified dimensional aspects i.e. Gross PPE, Accumulated Depreciation and Net PPE. Implicit filtering will ensure that facts with the same concept (corresponding to the rows in the table) are grouped together for evaluation. The rule will be evaluated three times, once for each concept.
Dimensional aggregation rules can also be defined in XBRL formula rules by leveraging the existing dimension relationship available in the taxonomy, rather than specifying members explicitly as has been done in this example. This approach is explained in Section 4.15.
4.6 Aggregation across typed dimension records
A business report collecting granular or transactional data may need to validate the cumulative value of all the records with the aggregated value reported separately.
Figure 4 gives an extract of a "Counterparty exposure" disclosure in which the counterparty identification captured as Legal Entity Identifier (LEI) is modelled as typed dimensions and exposure as a concept. The total exposure ($ 80) is modelled as a non-dimensional data point. This example explains how an XBRL formula rule can be defined to validate aggregation across the typed dimensions members.
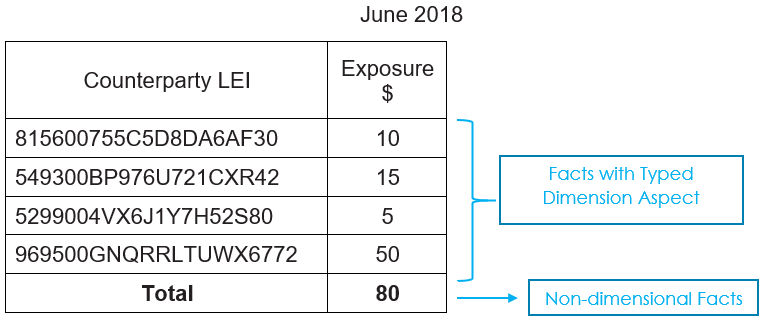 Figure 4: Breakdown of exposure by counterparty, identifier by LEI
Figure 4: Breakdown of exposure by counterparty, identifier by LEInamespace eg = "http://example.com/taxonomy"; assertion CounterpartyExposure { concept-name eg:Exposure; variable $components { bind-as-sequence typed-dimension eg:CounterpartyAxis; }; variable $total { not typed-dimension eg:CounterpartyAxis; }; test {$total eq sum ($components)}; };
This example defines a concept filter at the assertion level. This is technically known as a "group filter" and will be applied to all variables in the assertion. This means all the facts filtered for the rule will be using "eg:Exposures" as a concept. Group filters simplify the selection of facts based on aspects that are common to all variables.
The "components" variable defines a "typed dimension" filter specifying the dimension as "eg:CounterpartyAxis" (highlighted). All facts filtered for this variable will have the specified typed dimension. The filter also specifies the "bind-as-sequence" keyword which means that all facts selected by the filter will be grouped into a sequence in a single evaluation, rather than resulting in a separate evaluation for each dimension value.
In this Figure 4 example, the exposure facts (10,15, 5 and 50) pertaining to different counterparties will be considered in one evaluation. This is different to previous examples where each fact matching the filter criteria is evaluated separately.
The "total" value is reported using the same eg:Exposure concept, but reported without the "CounterPartyAxis" dimension. This is selected as the "total" variable by using the same typed dimension filter but with the "not" keyword (highlighted). This negates the filtering criteria, means the facts bound to "total" will NOT have the specified typed dimension aspect. In this example, the complemented typed dimension filter combines with the group concept filter to select the non-dimensional total exposure fact ($ 80).
The test expression "$total eq sum ($components)" aggregates the sequence of individual counterparty exposure facts (10,15, 5 and 50) and compares it with the reported total exposure (80). For the data shown in the example above, this rule would be evaluated only once. If additional facts were reported with different aspects, for example, facts for different periods, the rule would be evaluated multiple times.
4.7 Facts spanning multiple periods
Financial reports often include period reconciliation (roll-forward) disclosures, which check that the total at the end of a reporting period is equal to the total at the start of that period plus any changes that occur during the period. One such example is given in Figure 5 for "Cash and Cash Equivalents". This example demonstrates how an XBRL formula rule can be defined to validate the facts across multiple periods.
 Figure 5: Roll-forward example
Figure 5: Roll-forward exampleIn the table above, the first and third rows use the same instant concept ("Cash and cash equivalents"). The middle row is a duration concept ("Increase (decrease) in cash and cash equivalents").
Although the table above shows six figures, in XBRL this would be reported as five facts, as the opening balance of the 2017 period is the same fact as the closing balance of the 2016 period.
In writing a formula rule to check this roll forward calculation, we need to be careful to group the facts correctly for evaluation.
namespace eg = "http://example.com/taxonomy"; assertion CashReconciliation { variable $Changes { concept-name eg:IncreaseDecreaseInCashAndCashEquivalents; }; variable $ClosingBalance { concept-name eg:CashAndCashEquivalents; instant-duration end $Changes; }; variable $OpeningBalance { concept-name eg:CashAndCashEquivalents; instant-duration start $Changes; }; test {$ClosingBalance eq $OpeningBalance + $Changes}; };
The variable "Changes" defines a concept filter to select the facts with the duration concept "eg:IncreaseDecreaseInCashAndCashEquivalents".
The concept filters for variable "ClosingBalance" and "OpeningBalance" are the same however their fact values are measured at a different point in the time. To specify this additional "period filters" (highlighted) are defined.
The variable "ClosingBalance" defines an "instant-duration" period filter with the "end" keyword pointing to the "Changes" variable. This selects facts whose instant date matches the end date of the duration period of the facts bound by the variable "Changes".
Similarly, the variable "OpeningBalance" defines an "instant-duration" period filter with the "start" keyword pointing to the "Changes" variable. This will select facts whose instant date matches the start date of the duration period for facts bound by the variable "Changes".
Let's start with the first fact bound to the "Changes" variable i.e. "Increase (decrease) in cash and cash equivalents" pertaining to year 2017. Here the end duration date of the fact (40) is "2017-12-31". This means only the fact for "eg:CashAndCashEquivalents" with "2017-12-31" as its instant date will be bound to the "ClosingBalance" variable. Here it happens to be the "Closing Balance - Cash and Cash Equivalents" fact (140).
The start duration date of the fact bound to the "Changes" variable (40) is "2017-01-01". This means the fact for "eg:CashAndCashEquivalents" with an instant date of "2016-12-31" will be bound to variable "OpeningBalance". 3 In this case it is the "Opening Balance - Cash and Cash Equivalents" fact (100).
In a similar way the other fact (10) bound to the "Changes" variable will select its respective "ClosingBalance" fact (100) and "OpeningBalace" fact (90)
The instant-duration period filter thus matches facts across multiple periods to form an evaluation set. For the data given in Figure 5, the rule would be evaluated twice.
4.8 Rules where all facts may not be reported
In the examples seen so far, rules have only been applied when all variables bind to facts in the report. In many report types, not all facts are mandatory, and it is desirable to apply rules against those facts that have been reported. Let's take an example of an aggregation rule:
Current Assets = Current Inventories + Current Receivables + Cash
This example explains how an XBRL formula rule can be defined to check this rule, even if some of the contributing facts are not reported. In this example the disclosure items Current Assets, Current Inventories, Current Receivables and Cash are modelled as concepts in the taxonomy.
namespace eg = "http://example.com/taxonomy"; assertion CurrentAssets { variable $Parent { fallback {0} concept-name eg:CurrentAssets; }; variable $Child1 { fallback {0} concept-name eg:CurrentInventories; }; variable $Child2 { fallback {0} concept-name eg:CurrentReceivables; }; variable $Child3 { fallback {0} concept-name eg:Cash; }; test {$Parent eq $Child1 + $Child2 + $Child3 }; };
All variables have a concept filter and an additional "fallback" keyword (highlighted). The fallback keyword is used to provide a value that is used if the variable does not bind to a fact in the report.
Here the fallback value is set to zero (indicated inside curly brackets), which means if a value for the "eg:CurrentInventories" concept is not found in the report a value of zero will be used for the "Child1" variable when evaluating the test expression. This will result in the desired behaviour of checking that the total is equal to the sum of those contributing facts that are included in the report.
Let us assume a scenario in which the value reported for "eg:CurrentAssets" is 100 and its breakdown values are not reported, thus all "Child" variables will bind to the fallback value. The rule will fail as "100" would be compared to zero. A rule failure is desirable if the breakdown needs to be mandatorily reported, but would be undesirable if reporting of the contributing components is optional. In this case, a precondition could be used (see Section 4.10) to ensure that the rule is only evaluated if at least one contributing fact is reported. It should be noted that in the special case where if all variables bind to the fallback value, the rule will not be evaluated.
4.9 Combining filters and defining rule severity
In some cases, it is necessary to apply the same validation checks to multiple different facts or sets of facts. For example. we might require that both "Current Assets" and "Non-Current Assets" are reported as non-negative values. This could be done by defining two separate rules, one for each concept. In this example we"ll show a simpler approach that allows a single rule to check both concepts.
In this example we require negative values reported for "Current Assets" and "Non-Current Assets" to be flagged as departure from the norm and not be considered as an error. This example also shows how we can control the severity if a rule is not satisfied.
The disclosure items in this example are modelled as concepts in the taxonomy.
namespace eg = "http://example.com/taxonomy"; assertion PositiveValueAssets { unsatisfied-severity WARNING; variable $PositiveItems { or { concept-name eg:CurrentAssets; concept-name eg:NonCurrentAssets; }; }; test { $PositiveItems ge 0 }; };
The "PositiveItems" variable has two concept filters combined using the "or" construct (highlighted). This means the facts bound to this variable can have "eg:CurrentAssets" or "eg:NonCurrentAssets" as their concept. Every fact in the XBRL report which has one of these concepts would be bound by the variable and will be subject to this validation.
It should be noted that this is different to the default behaviour for when multiple filters are specified, which is to require that all are satisfied, which would of course be impossible in the case of two different concept-name filters as seen here. See Section 4.7 for how multiple filters are combined.
It is possible to classify a rule as ERROR or WARNING using the severity feature. Here in the rule the severity is set as "WARNING" at the assertion level (highlighted). This means that in case the validation is not satisfied, the failure will be treated as a WARNING. If severity is not explicitly defined for an XBRL formula rule, the severity defaults to "ERROR".
4.10 Conditional rule execution (preconditions)
Some rules require conditional validations evaluation. Few examples of such rules are
- Breakdown for "other revenue" is required if value is greater than $ 10000
- "Shares held by holding company" is mandatory to report if the company is a subsidiary company.
The prerequisites that are to be satisfied before validating the rule are referred as "preconditions" in XBRL formula rule. This example demonstrates how these preconditions can be defined in the XBRL formula rules.
Let's take an example of a rule which requires the accounting standard disclosed to be as "IFRS" if the entity is listed. The listing status and accounting standard are modelled in the taxonomy as "Extensible Enumeration" concepts. Here we first want the rule to check if the company is listed, and then proceed to check if the "Accounting Standard" disclosued is "IFRS".
namespace eg = "http://example.com/taxonomy"; namespace xs = "http://www.w3.org/2001/XMLSchema"; assertion AccountingStandard { variable $Standard { concept-name eg:AccountingStandard; }; variable $Status { concept-name eg:ListingStatus; }; precondition { $Status eq xs:QName("eg:Listed") }; test { $Standard eq xs:QName("eg:IFRS") }; };
The rule defines two variables and respective concept filters. Additionally, the rule defines a precondition (highlighted). The precondition expression checks if the value reported for the facts bound to variable "Status" is "eg:Listed". If the precondition is satisfied, the rule further proceeds to evaluate the test expression, otherwise the rule produces no result.
Any variables used in the preconditions are also subject to implicit filtering. The uncovered aspects for "Standard" and "Status" variables will be matched before forming an evaluation set. Figure 6 shows different XBRL report scenarios and their corresponding precondition result and the final XBRL formula rule result.
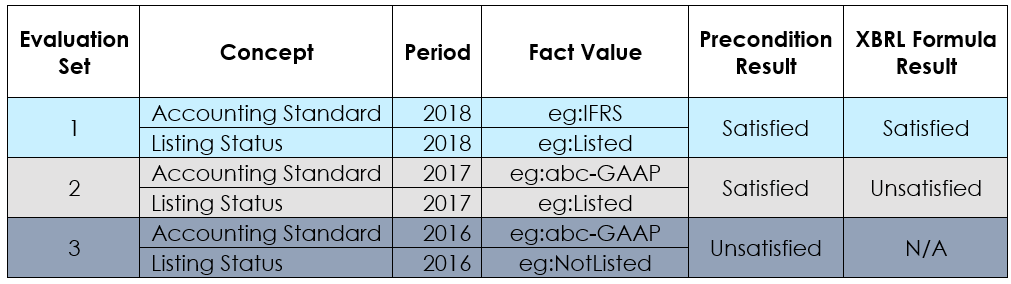 Figure 6: Effect of preconditions on XBRL formula rule results
Figure 6: Effect of preconditions on XBRL formula rule resultsIt should be noted that whilst preconditions can be built into the test expression, the behaviour is not exactly equivalent. For example, the above rule could be rewritten without the precondition by using the following test expression:
if $Status eq xs:QName("eg:Listed") then $Standard eq xs:QName("eg:IFRS") else true()
The primary practical difference to note is that where a precondition is not satisifed, no validation result is produced at all, whereas a test expression will always produce a "satisfied" or "unsatisfied" result. In this example, if the listing status of company is reported as "NotListed", the above test expression will produce a satisfied result wheares the use of precondition would not produce any result.
Appropriate use of preconditions can lead to more readable rules.
In some circumstances, the use of preconditions can lead to improved performance. Where preconditions depend only on parameters (see Section 4.11) and not on any variables, formula rules processors may make the optimisation of avoiding variable evaluation altogether which is typically the most time-consuming part of formula evaluation. It should be noted that processors are not required to perform such optimisation and performance may vary between different processors.
4.11 Rules using external values (parameters)
Some validation rules are dependent on information that is not known at the time of the taxonomy creation. Let's take an example of a rule validating the reserve balance of the banks with respect to the reserve ratio prescribed by the central banks.
i.e. minimum reserve balance = deposits * reserve ratio
We may wish to write this rule in a way that allows the reserve ratio to be altered without updating the formula rule and thus the taxonomy. This example shows how this can be done by making the reserve ratio an external parameter to an XBRL formula rule. In this example, "Reserve balance" and "Deposits" are modelled as concepts.
namespace eg = "http://example.com/taxonomy"; namespace xs = "http://www.w3.org/2001/XMLSchema"; parameter ReserveRatio { required as xs:decimal }; assertion MinimumReserveBalance { variable $ReserveBalance { concept-name eg:ReserveBalance; }; variable $Deposits { concept-name eg:Deposits; }; test { $ReserveBalance ge $Deposits * $p1}; parameter $p1 references $ReserveRatio; };
The rule declaration has a parameter definition (highlighted). The parameter (ReserveRatio) is defined to capture the value of the reserve ratio. The "required" keyword specifies that this parameter is mandatory. An error will be raised if this rule is executed without supplying a value for this parameter. It also additionally defines the datatype of the parameter value, which in this case is "decimal".
In order to use a parameter in an assertion, we need to bind it to a variable. This is done using the "parameter $p1 references $ReserveRatio" syntax (highlighted), which binds the parameter named "ReserveRatio" to "$p1" for use in the test expression.
In order to execute this rule, a value must be provided for the ReserveRatio parameter. For example, providing a value of 0.1 will check that Reserve Balance is greater than 10% of Deposits. The mechanism by which parameters are provided will depend on the formula processor in use.
It needs to be noted after the rule is evaluated, the externally supplied value for reserve ratio will not be stored anywhere in XBRL formula rule. Every time this rule will be validated the value for reserve ratio needs to be provided.
Using a parameter allows a value for reserve ratio to be provided at the time of rule execution, rather than hard-coding a value in the taxonomy.
A parameter can be used by multiple validation rules. The value supplied for the parameter is used across all rules in which the parameter is referenced. Section 4.12 demonstrates how parameters can be defined based on values in the XBRL report.
4.12 Defining common values across rules as parameters
Some sets of validation rules have code that is common across multiple rules. For example, execution of some rule may depend on the filing type of the report, which is determined by evaluation of an expression. Parameters can be used to evaluate this expression once, and re-use the result across all rules.
Let's take an example of a rule where we need to check the summation of revenue breakdown only for annual report. The concept "Type of Filing" modelled as an "Extensible Enumeration" is used for reporting the filing type. Quarterly and Annual are possible filing types. Revenue items are defined as taxonomy concepts.
namespace eg = "http://example.com/taxonomy"; namespace xs = "http://www.w3.org/2001/XMLSchema"; parameter FilingType { select { eg:FilingType } }; assertion RevenueBreakdown { variable $Total { concept-name eg:Revenue; }; variable $Product { concept-name eg:RevenueProduct; }; variable $Service { concept-name eg:RevenueService; }; precondition { $FT eq xs:QName("eg:Annual") }; test { $Total eq $Product + $Service }; parameter $FT references FilingType; };
A parameter (FilingType) is defined here, with the "select" keyword (highlighted). The select keyword specifies that the value for the parameter will be evaluated by the processor, unlike an externally supplied value in the Section 4.11.
The expression used in the select keyword selects the reported value for "eg:FilingType" concept and sets it as a value for "FilingType" parameter. This parameter is used in precondition as "FT" to check if the Filing Type is Annual. The test expression for revenue is evaluated when the precondition is satisfied.
It should be noted that the fact selected for the parameter value is evaluated separately from the assertion and does not participate in implicit filtering. This means that the facts involved in the assertion do not need to have the same period or other aspects as the "eg:FilingType" fact.
In this example "Filing Type" is a string concept and "Revenue" items are monetary concepts. As discussed in the Section 4.13, if we wanted to define FilingType as a variable, we would need to take additional steps to ensure that evaluation occurs, as facts for these concepts will necessarily have different aspects.
The flip side of not being subject to implicit filtering is that if multiple "FilingType" facts are present, the value of the parameter would be a sequence of all such facts, and the precondition will fail as it would be comparing a sequence to a single value. In practice, FilingType would typically be a mandatory fact, required to be reported exactly once, and would be subject to a separate existence assertion.
The value selected for a parameter is used across evaluation sets within a rule and across all rules in which the parameter is referenced. Figure 7 shows a sample of XBRL report scenarios and evaluation results for this rule.
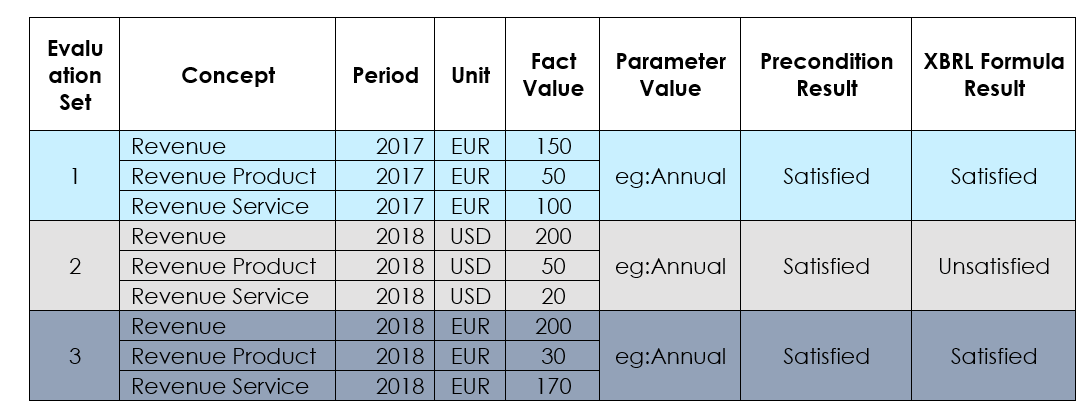 Figure 7: Use of parameters in preconditions
Figure 7: Use of parameters in preconditions4.13 Facts with different aspects
In previous examples we have seen how XBRL formula rules use implicit filtering to ensure that rules are applied within sets of facts sharing the same aspects. In some cases, rules need to be applied to facts with different aspects. The most common example of this is rules involving both numeric facts (which always have a "unit" aspect) and non numeric facts (which cannot have a unit aspect).
For example, let's consider a rule which mandates that "Audit report" must be reported if Revenue is greater than $10,000.
Here "Audit Report" is modelled as string concept and "Revenue" is modelled as monetary concept. This would mean that the unit aspect would not be reported for "Audit Report" facts but will be reported for "Revenue" facts.
namespace eg = "http://example.com/taxonomy"; assertion AuditReportMandatory { variable $Revenue { concept-name eg:Revenue; }; variable $AuditReport { fallback {()} aspect-cover unit; concept-name eg:AuditReportTextBlock; }; precondition {$Revenue gt 10000}; test {not(empty($AuditReport)}; };
In this rule the "Revenue" variable is used in a precondition to ensure that the rule will be evaluated only if the value of Revenue reported is greater than 10,000.
The implicit filtering of XBRL formula rule will evaluate the rule for sets of facts that share the same aspects (except for the those that are explicitly filtered). It is impossible for facts for Revenue and AuditReportTextBlock to share the same value for the unit aspect, and so if we did not mention the unit aspect the rule would never be applied.
To address this, the "AuditReport" variable defines an additional "aspect-cover filter" for "unit" (highlighted). The aspect cover filter specifies that the aspect is ignored for the purposes of implicit filtering. In other words, the specified aspect is not required to match the value of that aspect for other variables in the evaluation set. This means that the AuditReport variable will be included in an evaluation set with the Revenue variable, regardless of the units (currency) that the Revenue fact is reported with.
In the event that Revenue is reported multiple times with different units, multiple evaluations will occur and the same "AuditReportTextBlock" fact will be used in each of them (assuming all other aspects are the same).
It should be noted that the "AuditReport" variable specifies a fallback value of "()" (i.e. an empty value). This ensures that the rule is evaluated, even if an "AuditReportTextBlock" fact is not reported. In this case, the empty value for the "AuditReport" variable will not satisfy the test expression, resulting in a validation error.
4.14 Reusing relationship trees
XBRL taxonomies contain hierarchical information about the concepts in the taxonomy. These can include calculation and presentation hierarchies. The semantics conveyed by these hierarchies can be used to drive validation rules.
This example demonstrates how taxonomy relationship trees can be reused in XBRL formula rules. Let's take an extract of a presentation tree hierarchy for Current Assets:
- Current Assets Abstract
- Current Investments
- Current Financial Assets
- Current Tax Assets
- Other Current Assets
- Current Assets
Rule: All the facts for concepts belonging to the Current Asset hierarchy are to be reported as positive or zero.
This rule could be defined by using multiple concept filters to explicitly identify the required concepts as seen in Section 4.9. Building the rule this way would be time consuming if there are many concepts involved. It also creates a maintenance burden, as the list of concepts would need to be updated manually if the presentation tree changes, and the details of concepts embedded in a rule are harder to review than concepts arranged in a presentation tree.
In this example we will show how the presentation tree can be used to drive an XBRL formula rule. A similar approach can be used to allow taxonomy relationships to define calculation rules. An example of this is shown in Section 4.15
namespace eg = "http://example.com/taxonomy"; namespace xbrli = " http://www.xbrl.org/2003/instance"; assertion CurrentAssetsPositive { variable $CurrentAssets { concept-relation eg:CurrentAssetsAbstract linkrole "http://example.com/taxonomy/role/BalanceSheet" arcrole "http://www.xbrl.org/2003/arcrole/parent-child" axis child; concept-data-type non-strict xbrli:monetaryItemType; }; test { $CurrentAssets ge 0}; };
The "CurrentAssets" variable defines a "concept-relation-filter" (highlighted). This filter selects facts with concepts from an already existing relationship tree in the taxonomy.
"eg:CurrentAssetsAbstract" in the syntax indicates the source of the relationship tree, from which the related concepts will be traversed.
"http://example.com/taxonomy/role/BalanceSheet" conveys the extended link role in which the relationship is defined.
"http://www.xbrl.org/2003/arcrole/parent-child" indicates the arc role (type of relation) used to define the relationship. Here in this example, the arc role indicates that the relationship is from the presentation tree.
The "axis" keyword indicates the required relationship between selected concepts and the source concept (eg:CurrentAssetsAbstract). The value of "child" specifies that the concept must be a direct child of the source concept. If we wanted to select all descendants of the source concept, not just the direct children, we could specify "descendant" as the axis value.
Other options for axis include "parent", "ancestor", and "sibling". These options select concepts with the specified relationship with to the source concept. It is also possible to include the source concept itself by suffixing the axis value with "-or-self". For example, "descendant-or-self" would include all descendants of the source concept, and the source concept itself.
The rule construct would thus select all facts from Current Assets group of concepts (Current Investments, Current Financial Assets, Current Tax Assets, Other Current Assets or Current Assets) and evaluate the test expression for each fact.
The selection of concepts from an existing taxonomy tree relation can be further constrained by prescribing conditions on attributes such as preferred label, or weight.
The "CurrentAssets" variable also defines an additional "concept-data-type" filter (highlighted). This filter selects all the facts whose concept data type is "xbrli:monetaryItemType". This additional filter ensures that only monetary concepts from the presentation tree are selected for the rule evaluation. This avoids the possibility of evaluation errors resulting from an attempt to compare facts for any non-numeric concepts that may be included in the presentation tree.
The "non-strict" keyword in the filter specifies that the filter includes concepts whose datatype is "xbrli:monetaryItemType" or any type derived from it. Specifying "strict" here would select only those concepts with the specified type and exclude those with a derived datatype.
4.15 Dimensional aggregration using dimensional relationships
As discussed previously, aggregation across dimension members is a common validation requirement. Section 4.5 shows how a dimensional aggregation can be checked by explicitly identifying the individual domain members involved. XBRL formula rules can also leverage the dimensional relationships in a taxonomy to define such an aggregation, avoiding the need to state members explicitly and making maintenance of the rule easier. This section demonstrates how to use an explicit dimension filter to select members based on relationships defined in the taxonomy.
In this example "Classes of Borrowings" is modelled as a dimension and we wish to validate aggregation across its domain members.
- Borrowings Axis
- Borrowings Member
- Bonds Debentures Member
- Bonds Member
- Debentures Member
- Redeemable Preference Shares Member
- Term Loans Member
- Intercorporate Borrowings Member
- Deposits Member
- Other Loans and Advances Member
- Bonds Debentures Member
- Borrowings Member
Based on this tree, we wish to validate the aggregation totals for the two parent members, "Borrowings Member" and "Bonds Debentures Member". This can be achieved with a single XBRL formula rule by leveraging this hierarchy.
namespace eg = "http://example.com/taxonomy"; assertion BorrowingAggregation { variable $parent { explicit-dimension eg:BorrowingsAxis; }; variable $children { bind-as-sequence explicit-dimension eg:BorrowingsAxis member $parent linkrole "http://example.com/taxonomy/role/Borrowing" axis child; }; test { $parent eq sum($children) }; };
Here the "parent" and "children" variables define explicit dimension filters with different level of constraints.
The "parent" variable selects all facts with the "eg:BorrowingsAxis" dimension. The "children" variable defines an explicit dimension filter which selects facts based on having a dimension value in a specified tree. The first line, (highlighted), specifies the dimension that we are filtering on (eg:BorrowingsAxis). We can then specify a subset of the domain-member tree that we wish to filter to, by specifying a source ($parent), and extended link role (linkrole "http://example.com/taxonomy/role/Borrowing") and an axis ("child"). This will select all members that are a direct child of the member that the $parent variable is bound to.
For example, if the $parent variable binds to the value for "Borrowings Member", the "children" variable will select all facts with a member that is a direct child of "Borrowings Member" in the specified link role (as explained in Section 4.14). All such facts will be bound as a sequence to the "children" variable and will then be used to evaluate the test expression.
Similarly, "Bonds Debentures Member" bound for variable "parent" would filter its children from the dimension relationship to form an evaluation set.
An evaluation will not occur for the members that do not have any child members, such as "Term Loans Member" as although the "parent variable" will bind to all members in the tree, the "children" variable cannot bind where there are no child members, and evaluations only occur where all variables bind.
Figure 9 lists the evaluation set for the rule for the sample reported data in Figure 8
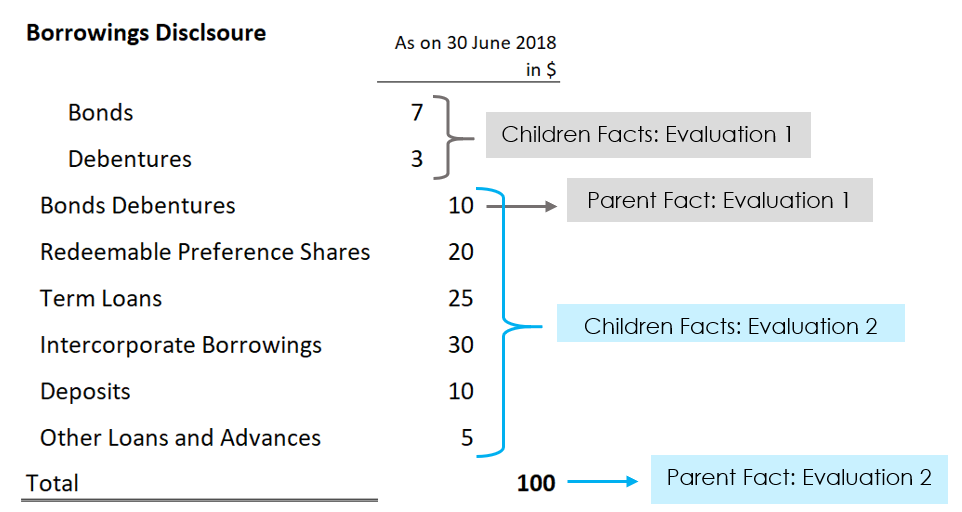 Figure 8: Breakdown of borrowings by hierarchy of borrowing class
Figure 8: Breakdown of borrowings by hierarchy of borrowing class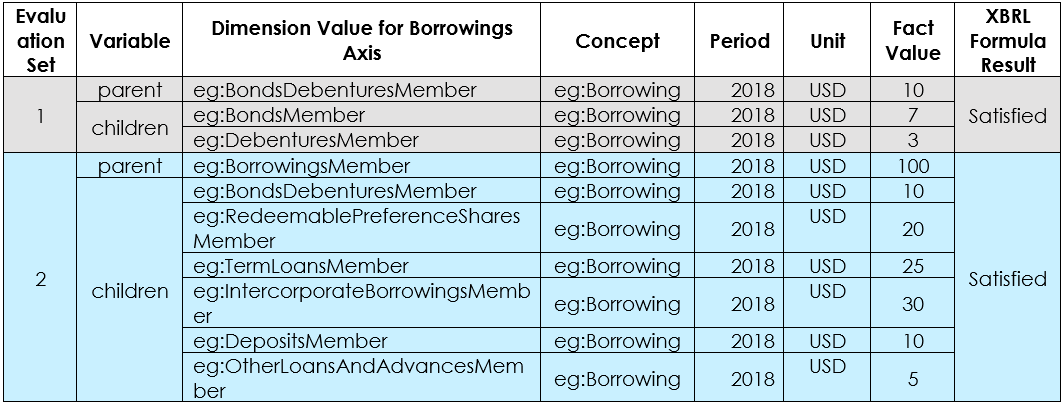 Figure 9: Rule evaluations at different levels within hierarchy
Figure 9: Rule evaluations at different levels within hierarchy4.16 Using an XBRL function library
The XPath 2 expressions in XBRL formula rules can make use of standard XPath 2 functions as well as XBRL functions. The XBRL formula specification provides a registry of XBRL-specific extension functions that can assist writing XBRL formula rules. Examples of these functions include querying instant date or identifier value for a fact or querying details of a concept's definition, such as the balance type or period type attributes.
XBRL functions can be used in test expressions, variable filters or error messages. A listing of available functions can be found in the XBRL International function registry.
To demonstrate the use of XBRL functions, consider a validation rule that requires that all reported facts use the standard scheme for Legal Entity Identifiers (LEIs) as the entity identifier scheme.
namespace xfi = "http://www.xbrl.org/2008/function/instance"; assertion lei-identifier-scheme { unsatisfied-message (en) "The entity identifier scheme associated with this fact ('{ xfi:identifier-scheme(xfi:entity-identifier(xfi:entity($v))) }') is not the standard LEI scheme ('http://standards.iso.org/iso/17442')"; variable $v1 { }; test { (xfi:identifier-scheme(xfi:entity-identifier(xfi:entity($v1))) eq 'http://standards.iso.org/iso/17442')}; };
The assertion defines a "v1" variable with no filter constrains, which means all facts will be selected for this rule evaluation.
The test expression uses three functions, "xfi:entity", "xfi:entity-identifier" and "xfi:identifier-scheme" (highlighted), to fetch the scheme value of the identifier reported in the entity aspect of the fact. The identifier-scheme value is then compared with the "http://standards.iso.org/iso/17442' which is the standard LEI scheme.
The unsatisfied message (highlighted) also makes use of functions in order to print the actual identifier-scheme value in the error message for a fact which has failed the validation rule. The use of XPath expressions allows the inclusion of dynamic information in the error message.
This document was produced by the Implementation Guidance Task Force.
Published on 2018-09-27.
-
The XBRL Formula Specification refers to validation rules as "assertions". ↩
-
When a date is used as the start date for a period, it is interpreted as meaning the instant at the start of that day. This makes it equivalent to a period end or instant period specifying the previous day, as this is interpreted as referring to the instant at the end of the day. In this example, a start date of "2017-01-01" is the same as an end date or instant of "2016-12-31". ↩





