
The Dutch Model: A Method for the Audit of ESEF Filings

This is a guest post by Jacques Urlus, policy advisor IT & Audit at the Royal Netherlands Institute of Chartered Accountants (NBA) and Vice Chair of our Dutch jurisdiction, XBRL NL. Based on his presentation at Data Amplified Virtual on 16 April 2021, he discusses his unique and groundbreaking work with the NBA on audit of reports submitted using the European Single Electronic Format (ESEF). With countries across Europe now starting to collect ESEF data, audit of that data to ensure its quality is a crucial challenge. The Dutch approach, rooted in pioneering implementation and audit of XBRL, offers a valuable model for assurance of ESEF filings, and other Inline XBRL reporting. Read on, or watch along with the video of his Data Amplified session here.
I would like to share the method and rationale behind the digital audit approach for ESEF filings that we have developed at NBA. One of the goals for audit of a digital reporting format like ESEF is to ensure that a human reader reaches the same decisions and understands the data the same way as a computer analysing the tagged data. This means that the machine-readable aspect of the report needs to be checked by the auditor, and compared with the human-readable content – by auditors who in general do not have a technical background.
The solution we have developed means that auditors do not need any technical knowledge of XBRL to successfully audit an ESEF filing. All technical elements can be audited by software, thanks to our analysis of ESEF rules for software companies. The software will also render the tagged content of an ESEF filing into a consistent, readable view, which can be compared to the original report. Discrepancies here indicate discrepancies between the machine- and the human-readable data and tell us that something is likely to be wrong.
A history of XBRL assurance
In the Netherlands we have a history of providing assurance on XBRL reports, as part of the national Standard Business Reporting (SBR) standard. Since 2017, it has been mandatory for independent companies of medium size and above to file their annual financial reports in XBRL, accompanied by an auditor’s opinion. We decided to make that process digital. The digital audit reports are based on an XBRL taxonomy, which means that the auditor’s opinion is itself a fully-tagged XBRL report.
As in other countries, this report must be signed by the auditor. Since both the annual and the auditor’s report are digital, this signature is digital too, generated with a Qualified Electronic Signature Creation Device (QSCD). The formal meaning of the digital signature can be found in the signature policy. Our business registry, the Netherlands Chamber of Commerce, therefore receives three files: the annual report in XBRL, the auditor’s opinion also in XBRL, and a detached signature containing the hash codes of these files and the digital signature of the auditor.
We think of the SBR Assurance solution as having pillars: first, consistent presentation, whereby a set of generalised rules is used to generate a true, fair and consistent view from an XBRL report. Second is the creation of auditor reports, a process underpinned by the XBRL taxonomy and which supports different types of audit reports in use. Third is linking and signing, producing a secure and dependable digital signature. Of these three, the first is perhaps the most important, since it is consistent presentation that allows us to transform the data in an XBRL report into a document that is readable and comprehensible by humans – in particular, auditors.
In the SBR case we were working with standard XBRL reports. These files, unlike Inline XBRL, are only readable by a computer. As a first step, software renders the report using discovered taxonomy definitions from the XBRL Table Linkbase, Presentation Linkbase and Label Linkbase, to produce a ‘raw’ presentation.
The specification for the consistent presentation contains a generic set of rules, which are then used to convert the raw presentation into an image that is fully viewable and understandable by humans. This presentation is used by the auditor to audit the financial statement – and because all software vendors use the same rules, the render results are always identical, or, as we say, consistent. So not only do auditors always see the same presentation, but all other data users always see what the auditor saw when assessing the XBRL filing.
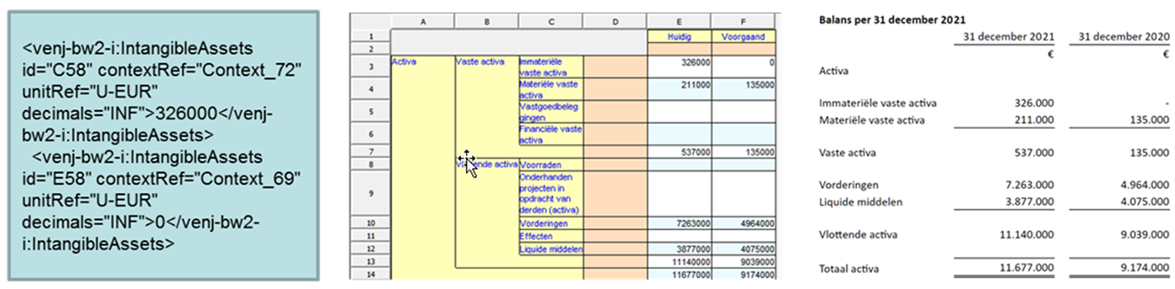
Figure 1: From left to right, XBRL code, raw presentation based on taxonomy definitions, and rendered consistent presentation.
How do we test this? All the software vendors in the Netherlands use the same test instances, and their render results are compared. Changes are made in the software until it meets requirements, and every software vendor is creating the same consistent presentation.
Applying our approach to ESEF
We copied and modified our existing approach for ESEF audit. The big difference is that ESEF uses Inline XBRL, and therefore the report package generates a report that is both human and machine readable. Because the transformation rules are part of the conversion, we call this method consistent transformation.
Why is this so important? The truth is that most auditors have little to no technical knowledge of XBRL. Of course, there are exceptions, but in an average audit team you might be lucky if there is one person who knows the difference between an abstract and a non-abstract item. This means there are parts of the ESEF Regulatory Technical Standards (RTS) and Reporting Manual that are absolutely incomprehensible for them. That is understandable; we all have our own specialisms, and I know IT-professionals who do not know the difference between debit or credit.
The challenge therefore was to develop a methodology that would enable the effective and efficient audit of an ESEF filing, without the auditor needing any substantive knowledge of XBRL.
Our first step was to understand and capture the ESEF requirements as a set of rules. The formal requirements are described in the RTS. When an annual report – or strictly speaking a report package – does not meet these requirements, we think the auditor should stop, inform the reporting entity and request a corrected report package. If the filer does not comply, this should be mentioned in the auditor opinion. Of course, we should consider the issue of materiality. Not everything will end up as a remark in the auditor’s opinion, but that is a matter for the professional judgement of the auditor.
On top of these we have the informal requirements, as laid out in the ESEF Reporting Manual. Failure to comply with these guidelines should not as a rule affect the auditor’s opinion, but we have compiled a list of situations where it may reasonably have an impact.
Why should that be the case? The reporting manual is intended to ensure that a report package can easily be processed by software, with a certain level of standardisation. If an entity does not adhere to the informal requirements, for example by using tuples, typed members, hypercubes and so on, which are disallowed by the manual, the risk arises that software will not be able to process the report package. The ultimate purpose of ESEF is to increase transparency of information, so we need to make sure that all report packages can be accessed and read. In the Netherlands, we believe that the auditor has a responsibility to pay attention to this.
With this in mind, we started by carrying out a complete analysis of the RTS. We explained all of the rules and provided an instruction or example of how to execute each rule. This is the core of the approach. These rules are not intended to be for the auditor, but for the software company that creates the audit software for use with ESEF filings. In other words, we explained the ESEF rules for the software vendors
We then carried out the same analysis for the requirements in the reporting manual, capturing those which were not in our opinion already covered by the RTS, again directed at software vendors. We also gave each informal requirement a ‘classification’ – not intended to be normative, but rather to provide some guidance to the auditor of the impact if the requirement is not adhered to.
In total, we identified 33 formal requirements and 67 informal requirements, which have been combined in what we call our technical audit approach for ESEF, alongside an audit process we have developed. We have uncovered certain areas that require particular attention, such as the transformation rules registry, which is not covered by the RTS and reporting manual. So, for example, what should we do if we encounter the transformation rule fixed-empty – which replaces all content with nothing, so the human reader sees data but the computer gets nothing – or the transformation rule fixed-zero, which replaces every number with a zero? We have developed responses to these scenarios in the absence of official guidance, although we hope that the latter will emerge.
Formulas also require special consideration; the ESMA ESEF taxonomy contains them and so we should also use them. It is important to be aware however that reported facts that produce warnings or errors in the validation process are not necessarily wrong. That distinction can be difficult to explain to both auditors and issuers, but is an important one to make. For example, an error can be flagged if a reporting company is missing the name of its parent entity, where in fact it does not have a parent entity and there is no cause for concern.
Another potential concern, which we were made aware of by our German colleagues, is the use of Cascading Style Sheets to control the display format. This can influence the image of the Inline XBRL document shown by a browser, for example causing it to show differently in landscape and portrait orientation, or in different widths of viewer or browser, and can even have an impact on printed results – in other words, it is possible for the same document to produce different views on different systems.
The digital audit process
So how does the digital audit process work? We start by extracting all the tagged data from the Inline XBRL file – i.e. the ESEF report – taking into account the transformation rules, to generate a complete plain vanilla XBRL file. The software then discovers the complete issuer’s taxonomy from the report package, and uses the definitions to render the XBRL data into a presentation view, calculation view and definition view. This is what we call the consistent transformation.
These overviews are readable and understandable by auditors, and can be compared to the original Inline XBRL document. In other words, auditors can compare the tagged machine-readable data that we have extracted with the human-readable view presented in the ESEF report. This enables the identification of wrongly tagged data, as well as errors in calculation relations, anchoring, labels and so on.
As an auditor, this approach gives you an overall view; on the other hand, by only assessing tagged data with an inline viewer you will not see the relationship between each concept and the total taxonomy. In our readable view, the issuer’s extension elements are also highlighted, showing which IFRS element from the ESMA ESEF taxonomy they are anchored to.
Alongside the auditor, when the audit software processes the report package it also assesses it against all the technical requirements from the RTS and ESEF Reporting manual, as well as basic XBRL validation processes and formulas. In the end we have a 100% audit of the report package, including a both a readable view for the auditor, which they use to assess the correctness and completeness of the annual report, and the execution of automated controls for the technical parts the auditor doesn’t understand.
And what do the results look like? Here for example, on the left we have a rendered statement of financial position produced using the consistent transformation (the machine-readable data), and on the right is the image of the Inline XBRL report (the human readable data). Both sides can be easily compared.
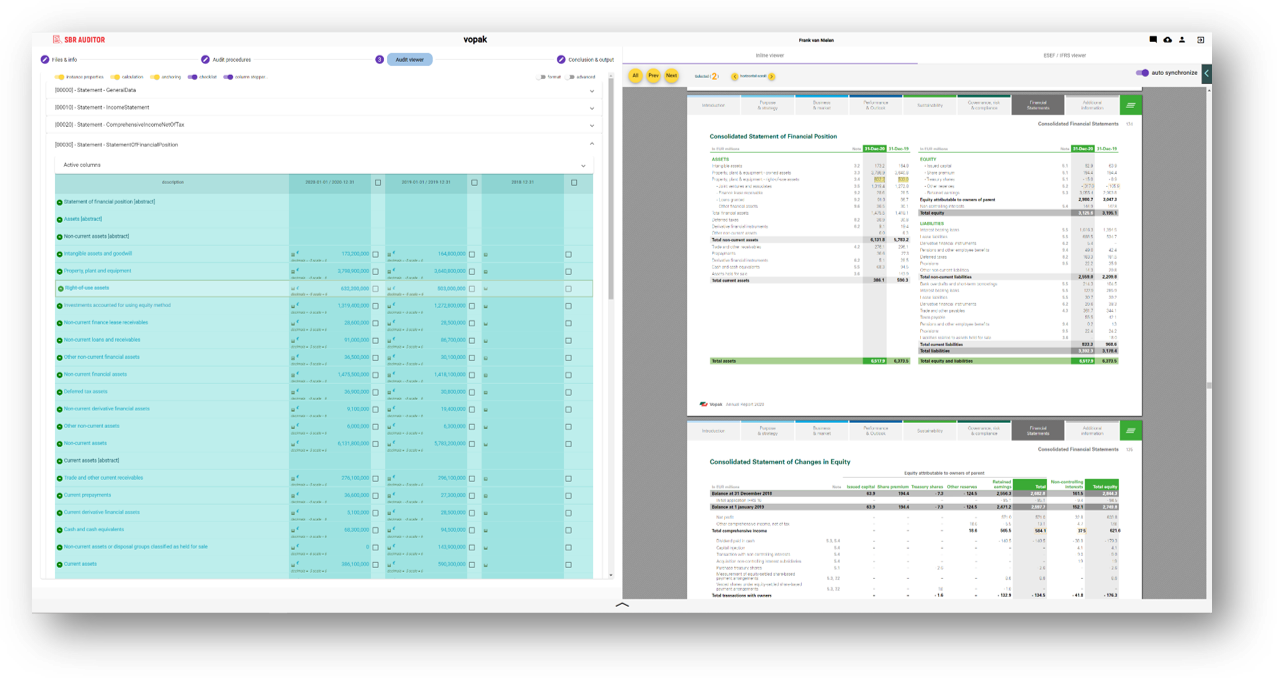
Figure 2: Statement of financial position rendered using the consistent transformation process (left) and as shown in the original ESEF Inline XBRL report (right).
This second example is taken from another software product, showing the same balance also rendered according to the consistent transformation. This view can easily be audited because it looks familiar to an auditor, with the advantage that each element can be examined.
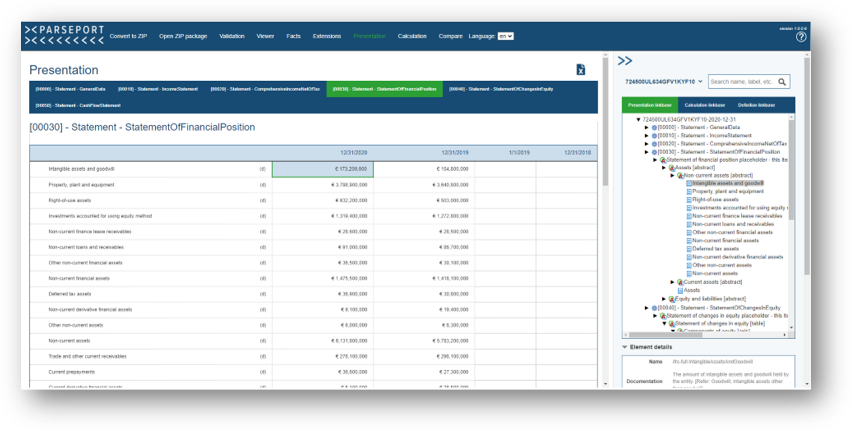
Figure 3: Statement of financial position rendered using the consistent transformation process.
In summary, the basic steps to performing an audit on an ESEF filing are as follows. The auditor performs their ‘classical’ audit on the human-readable Inline XBRL document in the normal old-fashioned way. Alongside that, we use audit software to discover the issuer’s taxonomy content and extract a plain XBRL file from the report. At this stage, all possible automated controls are carried out – including generic XML and XBRL validation, checks against the rules captured from the RTS and reporting manual, and validation of calculations and formulas – and, if necessary, exception reports are generated.
The XBRL data is then rendered, using the discovered taxonomy and following the consistent transformation rules, to create an auditor-friendly view of the tagged machine-readable data. This is compared manually with the Inline XBRL report by the auditor. If there is a mismatch we can assume that an error is likely to have occurred somewhere. For example, if a figure is missing in the balance sheet we can assume that the Presentation Linkbase is not correct, or if a column is missing in the statement of changes in equity we are probably missing a dimensional member.
Digital integrity
We use hash codes to help protect the integrity of the process. To make sure we are all talking about the same audit object – in this case the complete report package, including the meta taxonomypackage.xml file, the entry point scheme, the linkbases and of course the Inline XBRL file itself – we developed an open source solution for creating individual file hash codes and an overall hash code for the report package. This tool, including sources in C# and VB.Net and an installation package, can be downloaded from our website. Hash codes are used, for example, by the auditor in their letter of consent to identify the report package they looked at and ensure that it is not subsequently changed. I understand that other countries are now following our lead and adopting this approach.
Does all of this work?
Yes, we have found that is does! Of course, there are a few minor issues as we learn on the job, but overall, our digital audit approach appears to be working extremely well in offering a method for auditors to tackle ESEF filings and check digital data without technical knowledge.
Although the mandate has been postponed for a year in the Netherlands, as in most other European countries due to the Covid-19 crisis, 18 large companies have filed ESEF report packages on a voluntary basis. All of these filings were audited using our approach, which has so far been integrated into the audit software offered by two companies, Accept and ParsePort. The conclusion of the Dutch Authority for the Financial Markets was that all 18 submitted filings were 100% technically correct – which might leave us with a lack of interesting problems to solve, but it does show that the reporting and assurance processes are working remarkably smoothly so far!
I strongly encourage other audit organisations and software vendors to take a look at this approach, and please do contact us and we will be more than happy to send you all the documentation and ongoing updates.
We’re bringing you a range of insights and reflections from our world-leading speakers – check out the Data Amplified tag to see more, and watch this space!





