
Insights from Japan’s Digitally Tagged KAMs: 3 – Seeing Similarity in Text Disclosures

This is part of a short series on initial insights from our analysis of digital KAMs data being collected in Japan for the first time. For the first post and introduction, start here.
In the earlier posts in this series, we looked at how digital tagging of Key Audit Matters (KAMs) using XBRL is helpful in understanding risks identified in the audit. Using early Japanese data, we have drawn out insights at the level of broad themes, industry sectors and specific entities.
One of the objectives of disclosing KAMs is to provide meaningful information about the audit and enhance communicative value. These outcomes may be poorly served when excessive similarities are found in KAM disclosure texts across entities – with these similar texts sometimes referred to as ‘boilerplate disclosures.’
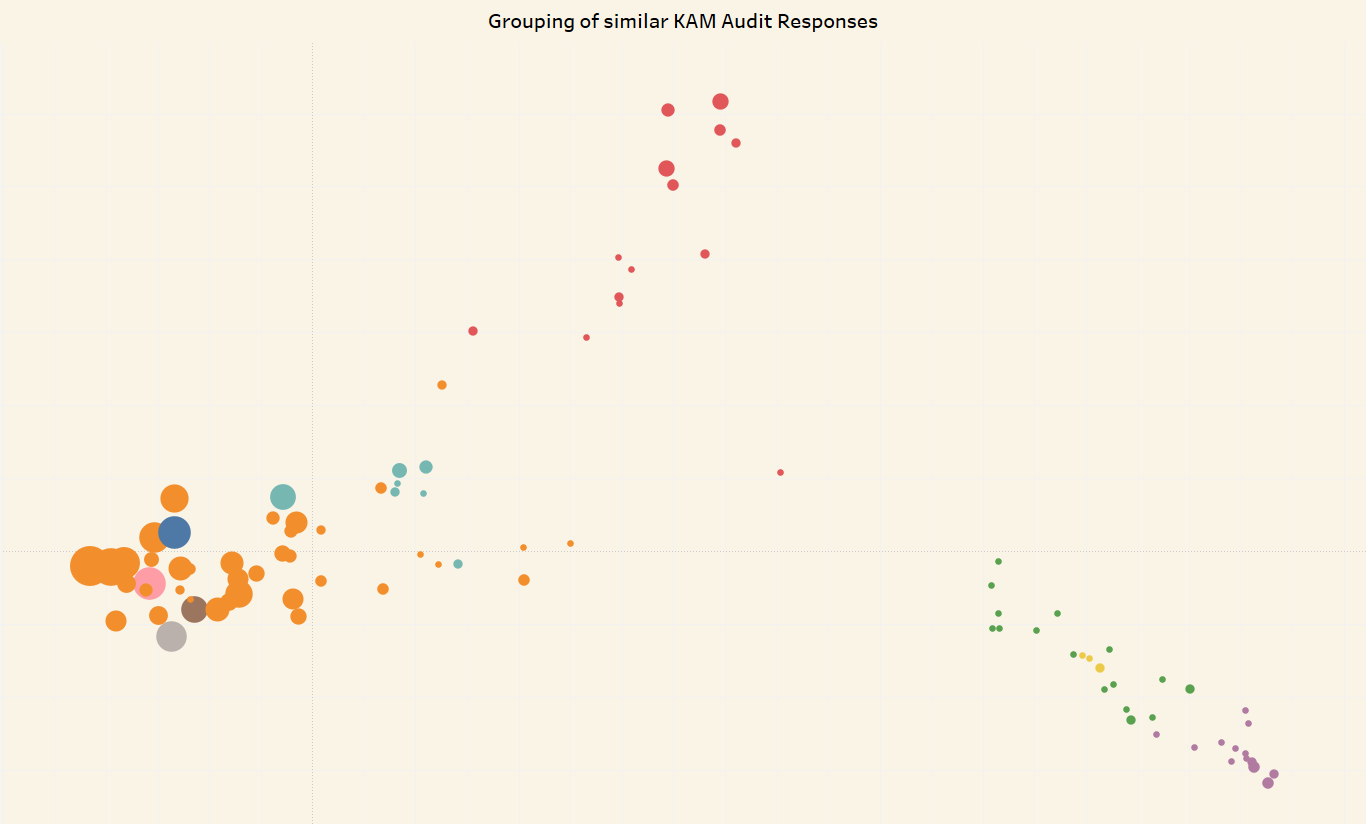
For this analysis we used the text block tagged with ‘Audit Response KAM’, comprising the auditor’s comments on the KAMs they have identified. The graphic shows audit responses with greater than 90% similarity with at least one other report. Dots of the same colour indicate responses that fit into similar groups, with the size of the dots reflecting the number of audit responses.
On a technical note: cosine similarity was used to find similarities between audit responses; clustering was used to group related responses. To represent similar groups visually, we used principal component analysis (PCA), whereby the two most important dimensions in indicating similarity are plotted against each other.
We analysed roughly 2,800 digitally tagged audit responses on KAMs, all taken from consolidated financial statements by Japanese public companies. Of these, around 500 had more than 90% similarity with at least one other audit response. Much of this similarity appears to be generated within audit firms: around 80% of similar audit responses had the same audit firm.
It would not be appropriate to draw any firm conclusions at this stage; we hope to see further analysis and a deeper understanding of the context of the data. There is an extent to which similar KAMs will tend to reappear as common concerns, particularly within industries, but it is also possible that regulators may wish to consider whether the reuse of boilerplate text compromises KAM usefulness. As we have seen in this series so far, the digitally tagged KAMs can be put to analytical use in a number of ways which would have been prohibitively resource-hungry in a non-digital disclosure environment.
In the next and final post, we will explore how granularly tagged KAMs with specific data points (including description, auditor response, and note reference) are even more analytically useful than complete text blocks.
Please note that the data was originally in Japanese and was translated using Google Translate, so it may well contain translation errors. It is also early days for this new tagging requirement, so we can expect some data-quality issues; we understand that the Japanese Institute of Certified Public Accountants is currently working on some relevant guidance. We thank XBRL Japan for sharing the data, enabling us to set the ball rolling with this initial analysis.





