
ESEF Errors and Common Pitfalls: 7 – HTML formatting

This is part of a series on common errors and pitfalls in ESEF filings, observed in our analysis of hundreds of reports collected in our repository, at filings.xbrl.org. For the series introduction, start here.
Inline XBRL embeds XBRL tags into an HTML document, resulting in a single document that enables filers to provide computer-readable data whilst retaining significant control over the report presentation. HTML allows styling and formatting to be applied to the report, and ESEF filings often include a very high level of document design, similar to that seen in PDF financial reports. The techniques used to achieve this styling can, however, cause issues with Inline XBRL tags. This post describes some of these issues, and how to avoid them.
Concealed Facts
Under the current Inline XBRL v1.1 specification, numeric tags are not permitted to contain any HTML tags. This means that any styling must be applied to the whole of the tagged number. This is not normally an issue, as there is rarely a need to apply styling to individual digits or characters within a number. However, some ESEF filings have been created by using an automated PDF-to-HTML conversion process, which can result in HTML tags being included within numbers that need to be tagged.
Let us take the example of this extract to understand the issue.
![]()
Although the highlighted number doesn’t appear to have any unusual styling or formatting, if we look at the HTML source we can see that there is an additional <span> tag between the decimal point and the last digit:
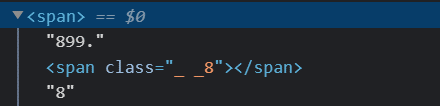
The <span> element is being used to make a very minor adjustment to character spacing, in order to preserve the appearance of the PDF from which it was created. Such adjustments are often less than a pixel in width, and are almost undetectable, but the inclusion of the <span> element creates a problem for tagging in Inline XBRL.
The approach taken in this case was to repeat the number in a second HTML element without the additional formatting, and then hide and tag it:
![]()
Unfortunately, this approach undermines one of the key benefits of Inline XBRL — the link between the human-readable displayed value and the machine-readable tagged information. If this report is displayed in an Inline XBRL viewer, it is not possible to see the number that has been tagged, or to use tag information to navigate around the document.
This approach also creates an additional review burden, as there is no guarantee of correspondence between the tagged value and the displayed value.
The ideal solution in this situation is to remove the additional HTML tags so that the number can be tagged in the normal way. We expect that ESMA will clarify its view on this in due course.
The use of a hidden HTML element as a workaround contravenes the Inline XBRL specification, although processors are not required to validate this rule.
White space handling in text tags
The use of styling can lead to unexpected results in text tags. HTML normalises any white space used within text; any combination of spaces, tabs and new lines is treated as being a single space when displayed. For this reason, HTML documents often include additional white space characters that have no effect on the appearance of the document. For example, the highlighted text from the following extract is used to tag the concept Domicile of Entity.
![]()
As in the previous example, the HTML contains additional styling that is used to adjust the character spacing:
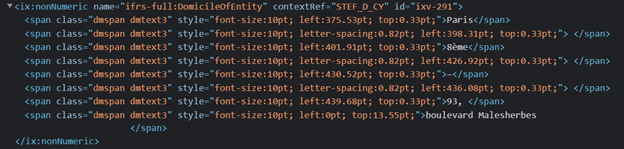
In order to make the HTML source more readable, each <code;> element is placed on a separate line and indented. This has no effect of the display of the document, but the additional white space will be included in values for XBRL facts. In this case, the tagged value is:
Paris 8ème – 93, boulevard Malesherbes
Although consumption software may choose to normalise this additional white space, it is not required to, and so it is recommended to remove such additional space from the HTML document in order to avoid the issue.
If you would like to learn more about these questions (which – we realise – mostly impact XBRL vendors) please join the XBRL Rendering and XBRL Specification Working Groups, which are currently working on ways to greatly improve these issues.





